 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution-free calibration guarantees for histogram binning without sample splitting
Paper and Code
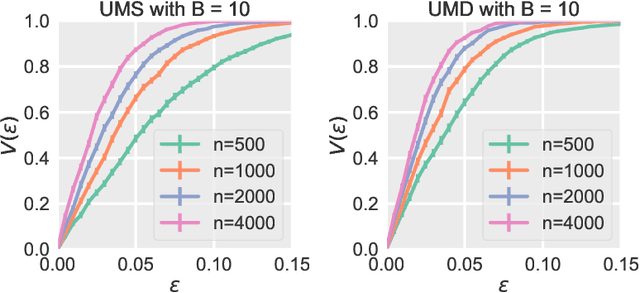
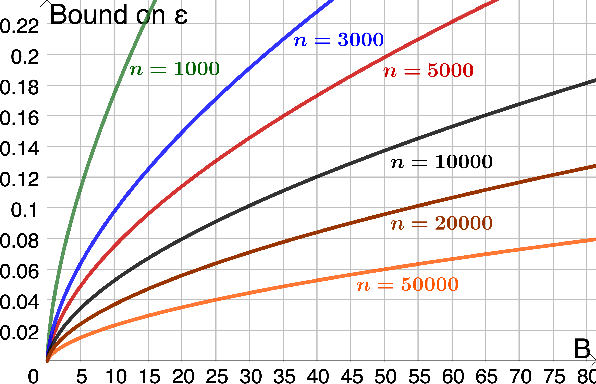
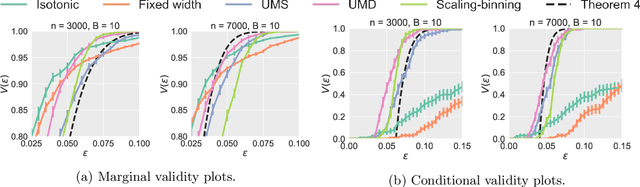
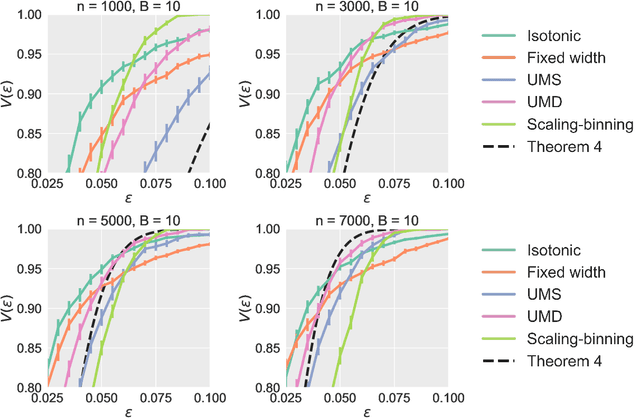
We prove calibration guarantees for the popular histogram binning (also called uniform-mass binning) method of Zadrozny and Elkan [2001]. Histogram binning has displayed strong practical performance, but theoretical guarantees have only been shown for sample split versions that avoid 'double dipping' the data. We demonstrate that the statistical cost of sample splitting is practically significant on a credit default dataset. We then prove calibration guarantees for the original method that double dips the data, using a certain Markov property of order statistics. Based on our results, we make practical recommendations for choosing the number of bins in histogram binning. In our illustrative simulations, we propose a new tool for assessing calibration -- validity plots -- which provide more information than an ECE estimate.