 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Synthetic Data with Hierarchical Structure
Paper and Code
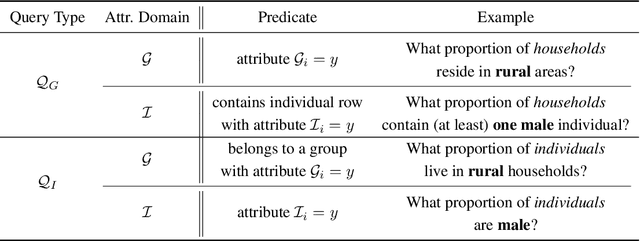
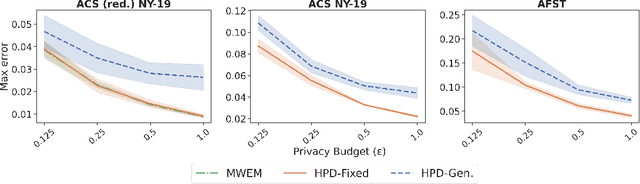

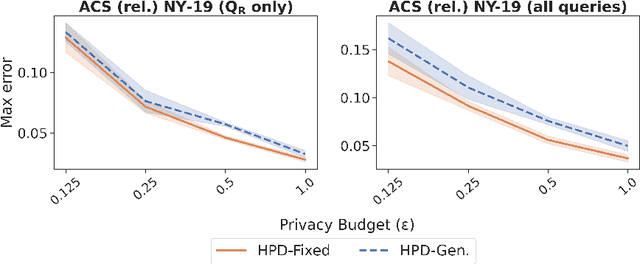
We study the problem of differentially private synthetic data generation for hierarchical datasets in which individual data points are grouped together (e.g., people within households). In particular, to measure the similarity between the synthetic dataset and the underlying private one, we frame our objective under the problem of private query release, generating a synthetic dataset that preserves answers for some collection of queries (i.e., statistics like mean aggregate counts). However, while the application of private synthetic data to the problem of query release has been well studied, such research is restricted to non-hierarchical data domains, raising the initial question -- what queries are important when considering data of this form? Moreover, it has not yet been established how one can generate synthetic data at both the group and individual-level while capturing such statistics. In light of these challenges, we first formalize the problem of hierarchical query release, in which the goal is to release a collection of statistics for some hierarchical dataset. Specifically, we provide a general set of statistical queries that captures relationships between attributes at both the group and individual-level. Subsequently, we introduce private synthetic data algorithms for hierarchical query release and evaluate them on hierarchical datasets derived from the American Community Survey and Allegheny Family Screening Tool data. Finally, we look to the American Community Survey, whose inherent hierarchical structure gives rise to another set of domain-specific queries that we run experiments with.