 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-group Uncertainty Quantification for Long-form Text Generation
Paper and Code
Jul 25, 2024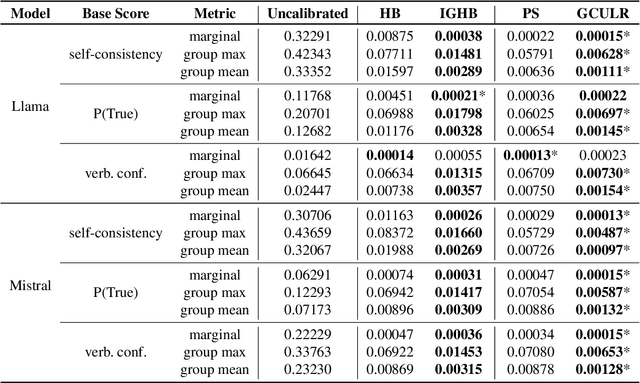
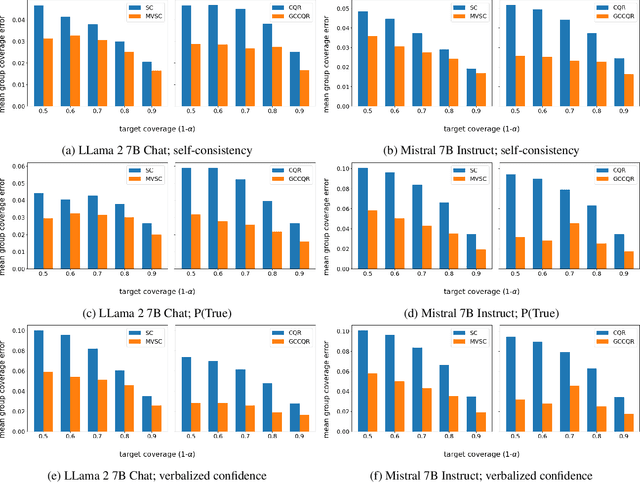
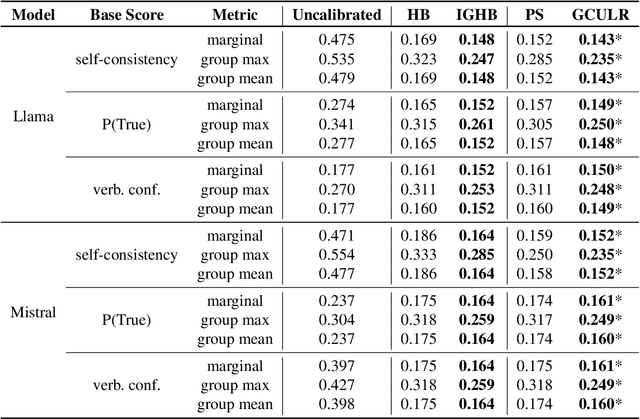
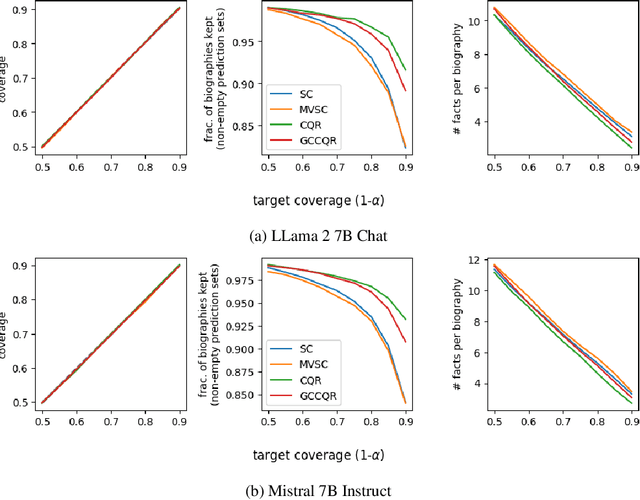
While large language models are rapidly moving towards consumer-facing applications, they are often still prone to factual errors and hallucinations. In order to reduce the potential harms that may come from these errors, it is important for users to know to what extent they can trust an LLM when it makes a factual claim. To this end, we study the problem of uncertainty quantification of factual correctness in long-form natural language generation. Given some output from a large language model, we study both uncertainty at the level of individual claims contained within the output (via calibration) and uncertainty across the entire output itself (via conformal prediction). Moreover, we invoke multicalibration and multivalid conformal prediction to ensure that such uncertainty guarantees are valid both marginally and across distinct groups of prompts. Using the task of biography generation, we demonstrate empirically that having access to and making use of additional group attributes for each prompt improves both overall and group-wise performance. As the problems of calibration, conformal prediction, and their multi-group counterparts have not been extensively explored previously in the context of long-form text generation, we consider these empirical results to form a benchmark for this setting.