 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelative Density Ratio Optimization for Stable and Statistically Consistent Model Alignment
Apr 06, 2026Aligning language models with human preferences is essential for ensuring their safety and reliability. Although most existing approaches assume specific human preference models such as the Bradley-Terry model, this assumption may fail to accurately capture true human preferences, and consequently, these methods lack statistical consistency, i.e., the guarantee that language models converge to the true human preference as the number of samples increases. In contrast, direct density ratio optimization (DDRO) achieves statistical consistency without assuming any human preference models. DDRO models the density ratio between preferred and non-preferred data distributions using the language model, and then optimizes it via density ratio estimation. However, this density ratio is unstable and often diverges, leading to training instability of DDRO. In this paper, we propose a novel alignment method that is both stable and statistically consistent. Our approach is based on the relative density ratio between the preferred data distribution and a mixture of the preferred and non-preferred data distributions. Our approach is stable since this relative density ratio is bounded above and does not diverge. Moreover, it is statistically consistent and yields significantly tighter convergence guarantees than DDRO. We experimentally show its effectiveness with Qwen 2.5 and Llama 3.
Let's Put Ourselves in Sally's Shoes: Shoes-of-Others Prefixing Improves Theory of Mind in Large Language Models
Jun 06, 2025Recent studies have shown that Theory of Mind (ToM) in large language models (LLMs) has not reached human-level performance yet. Since fine-tuning LLMs on ToM datasets often degrades their generalization, several inference-time methods have been proposed to enhance ToM in LLMs. However, existing inference-time methods for ToM are specialized for inferring beliefs from contexts involving changes in the world state. In this study, we present a new inference-time method for ToM, Shoes-of-Others (SoO) prefixing, which makes fewer assumptions about contexts and is applicable to broader scenarios. SoO prefixing simply specifies the beginning of LLM outputs with ``Let's put ourselves in A's shoes.'', where A denotes the target character's name. We evaluate SoO prefixing on two benchmarks that assess ToM in conversational and narrative contexts without changes in the world state and find that it consistently improves ToM across five categories of mental states. Our analysis suggests that SoO prefixing elicits faithful thoughts, thereby improving the ToM performance.
ToMATO: Verbalizing the Mental States of Role-Playing LLMs for Benchmarking Theory of Mind
Jan 15, 2025



Existing Theory of Mind (ToM) benchmarks diverge from real-world scenarios in three aspects: 1) they assess a limited range of mental states such as beliefs, 2) false beliefs are not comprehensively explored, and 3) the diverse personality traits of characters are overlooked. To address these challenges, we introduce ToMATO, a new ToM benchmark formulated as multiple-choice QA over conversations. ToMATO is generated via LLM-LLM conversations featuring information asymmetry. By employing a prompting method that requires role-playing LLMs to verbalize their thoughts before each utterance, we capture both first- and second-order mental states across five categories: belief, intention, desire, emotion, and knowledge. These verbalized thoughts serve as answers to questions designed to assess the mental states of characters within conversations. Furthermore, the information asymmetry introduced by hiding thoughts from others induces the generation of false beliefs about various mental states. Assigning distinct personality traits to LLMs further diversifies both utterances and thoughts. ToMATO consists of 5.4k questions, 753 conversations, and 15 personality trait patterns. Our analysis shows that this dataset construction approach frequently generates false beliefs due to the information asymmetry between role-playing LLMs, and effectively reflects diverse personalities. We evaluate nine LLMs on ToMATO and find that even GPT-4o mini lags behind human performance, especially in understanding false beliefs, and lacks robustness to various personality traits.
Which Shortcut Solution Do Question Answering Models Prefer to Learn?
Nov 29, 2022Question answering (QA) models for reading comprehension tend to learn shortcut solutions rather than the solutions intended by QA datasets. QA models that have learned shortcut solutions can achieve human-level performance in shortcut examples where shortcuts are valid, but these same behaviors degrade generalization potential on anti-shortcut examples where shortcuts are invalid. Various methods have been proposed to mitigate this problem, but they do not fully take the characteristics of shortcuts themselves into account. We assume that the learnability of shortcuts, i.e., how easy it is to learn a shortcut, is useful to mitigate the problem. Thus, we first examine the learnability of the representative shortcuts on extractive and multiple-choice QA datasets. Behavioral tests using biased training sets reveal that shortcuts that exploit answer positions and word-label correlations are preferentially learned for extractive and multiple-choice QA, respectively. We find that the more learnable a shortcut is, the flatter and deeper the loss landscape is around the shortcut solution in the parameter space. We also find that the availability of the preferred shortcuts tends to make the task easier to perform from an information-theoretic viewpoint. Lastly, we experimentally show that the learnability of shortcuts can be utilized to construct an effective QA training set; the more learnable a shortcut is, the smaller the proportion of anti-shortcut examples required to achieve comparable performance on shortcut and anti-shortcut examples. We claim that the learnability of shortcuts should be considered when designing mitigation methods.
Penalizing Confident Predictions on Largely Perturbed Inputs Does Not Improve Out-of-Distribution Generalization in Question Answering
Nov 29, 2022



Question answering (QA) models are shown to be insensitive to large perturbations to inputs; that is, they make correct and confident predictions even when given largely perturbed inputs from which humans can not correctly derive answers. In addition, QA models fail to generalize to other domains and adversarial test sets, while humans maintain high accuracy. Based on these observations, we assume that QA models do not use intended features necessary for human reading but rely on spurious features, causing the lack of generalization ability. Therefore, we attempt to answer the question: If the overconfident predictions of QA models for various types of perturbations are penalized, will the out-of-distribution (OOD) generalization be improved? To prevent models from making confident predictions on perturbed inputs, we first follow existing studies and maximize the entropy of the output probability for perturbed inputs. However, we find that QA models trained to be sensitive to a certain perturbation type are often insensitive to unseen types of perturbations. Thus, we simultaneously maximize the entropy for the four perturbation types (i.e., word- and sentence-level shuffling and deletion) to further close the gap between models and humans. Contrary to our expectations, although models become sensitive to the four types of perturbations, we find that the OOD generalization is not improved. Moreover, the OOD generalization is sometimes degraded after entropy maximization. Making unconfident predictions on largely perturbed inputs per se may be beneficial to gaining human trust. However, our negative results suggest that researchers should pay attention to the side effect of entropy maximization.
Look to the Right: Mitigating Relative Position Bias in Extractive Question Answering
Oct 26, 2022Extractive question answering (QA) models tend to exploit spurious correlations to make predictions when a training set has unintended biases. This tendency results in models not being generalizable to examples where the correlations do not hold. Determining the spurious correlations QA models can exploit is crucial in building generalizable QA models in real-world applications; moreover, a method needs to be developed that prevents these models from learning the spurious correlations even when a training set is biased. In this study, we discovered that the relative position of an answer, which is defined as the relative distance from an answer span to the closest question-context overlap word, can be exploited by QA models as superficial cues for making predictions. Specifically, we find that when the relative positions in a training set are biased, the performance on examples with relative positions unseen during training is significantly degraded. To mitigate the performance degradation for unseen relative positions, we propose an ensemble-based debiasing method that does not require prior knowledge about the distribution of relative positions. We demonstrate that the proposed method mitigates the models' reliance on relative positions using the biased and full SQuAD dataset. We hope that this study can help enhance the generalization ability of QA models in real-world applications.
Improving the Robustness to Variations of Objects and Instructions with a Neuro-Symbolic Approach for Interactive Instruction Following
Oct 13, 2021
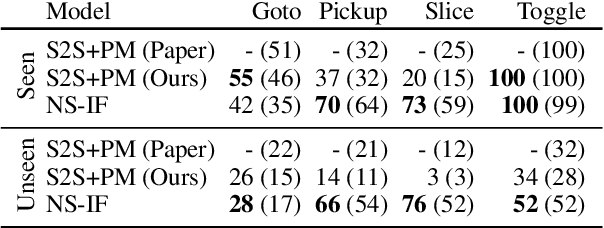
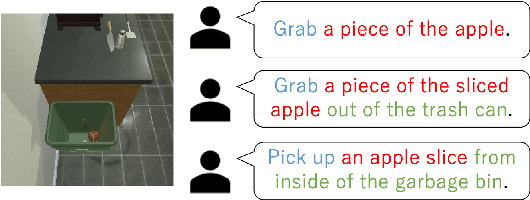
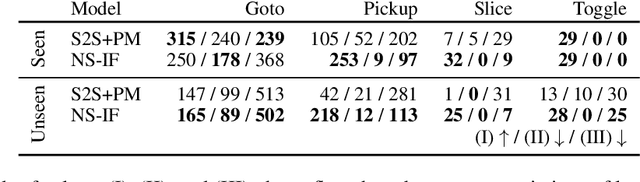
An interactive instruction following task has been proposed as a benchmark for learning to map natural language instructions and first-person vision into sequences of actions to interact with objects in a 3D simulated environment. We find that an existing end-to-end neural model for this task is not robust to variations of objects and language instructions. We assume that this problem is due to the high sensitiveness of neural feature extraction to small changes in vision and language inputs. To mitigate this problem, we propose a neuro-symbolic approach that performs reasoning over high-level symbolic representations that are robust to small changes in raw inputs. Our experiments on the ALFRED dataset show that our approach significantly outperforms the existing model by 18, 52, and 73 points in the success rate on the ToggleObject, PickupObject, and SliceObject subtasks in unseen environments respectively.
Can Question Generation Debias Question Answering Models? A Case Study on Question-Context Lexical Overlap
Sep 23, 2021
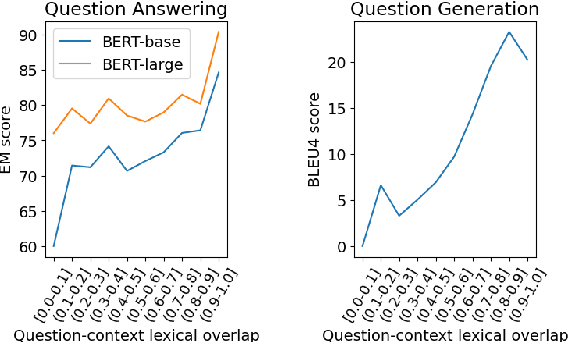
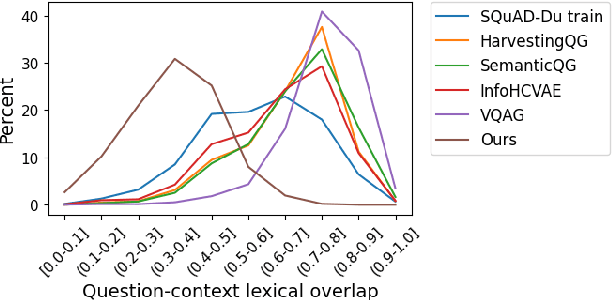
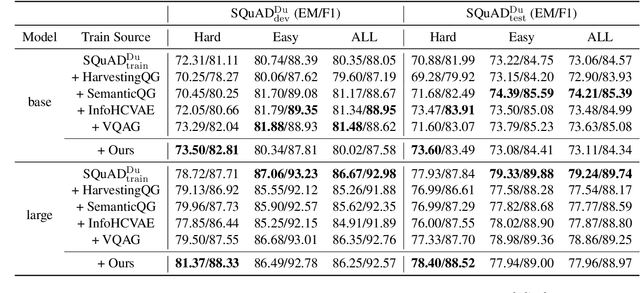
Question answering (QA) models for reading comprehension have been demonstrated to exploit unintended dataset biases such as question-context lexical overlap. This hinders QA models from generalizing to under-represented samples such as questions with low lexical overlap. Question generation (QG), a method for augmenting QA datasets, can be a solution for such performance degradation if QG can properly debias QA datasets. However, we discover that recent neural QG models are biased towards generating questions with high lexical overlap, which can amplify the dataset bias. Moreover, our analysis reveals that data augmentation with these QG models frequently impairs the performance on questions with low lexical overlap, while improving that on questions with high lexical overlap. To address this problem, we use a synonym replacement-based approach to augment questions with low lexical overlap. We demonstrate that the proposed data augmentation approach is simple yet effective to mitigate the degradation problem with only 70k synthetic examples. Our data is publicly available at https://github.com/KazutoshiShinoda/Synonym-Replacement.
Variational Question-Answer Pair Generation for Machine Reading Comprehension
Apr 07, 2020


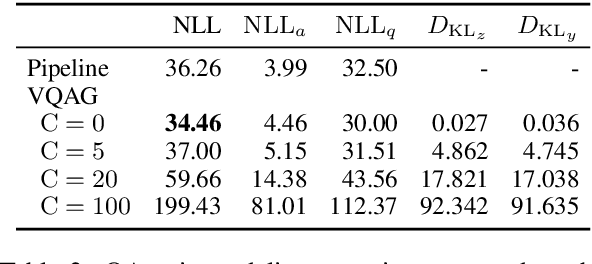
We present a deep generative model of question-answer (QA) pairs for machine reading comprehension. We introduce two independent latent random variables into our model in order to diversify answers and questions separately. We also study the effect of explicitly controlling the KL term in the variational lower bound in order to avoid the "posterior collapse" issue, where the model ignores latent variables and generates QA pairs that are almost the same. Our experiments on SQuAD v1.1 showed that variational methods can aid QA pair modeling capacity, and that the controlled KL term can significantly improve diversity while generating high-quality questions and answers comparable to those of the existing systems.
Multi-style Generative Reading Comprehension
Jan 08, 2019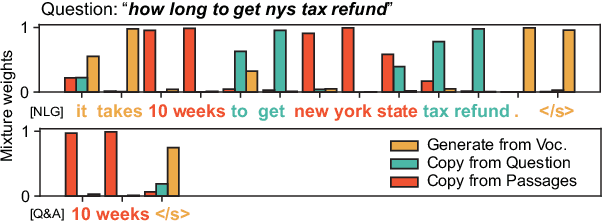

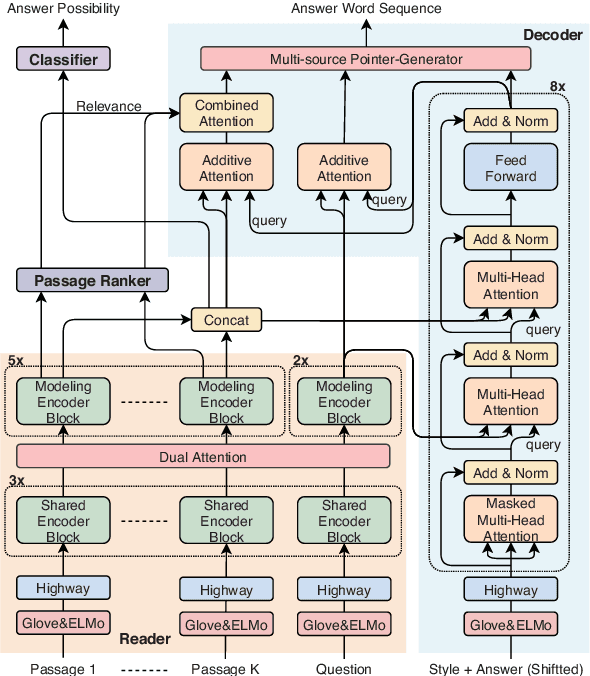
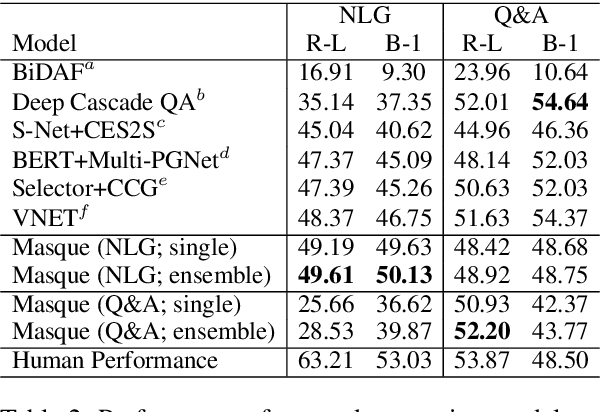
This study focuses on the task of multi-passage reading comprehension (RC) where an answer is provided in natural language. Current mainstream approaches treat RC by extracting the answer span from the provided passages and cannot generate an abstractive summary from the given question and passages. Moreover, they cannot utilize and control different styles of answers, such as concise phrases and well-formed sentences, within a model. In this study, we propose a style-controllable Multi-source Abstractive Summarization model for QUEstion answering, called Masque. The model is an end-to-end deep neural network that can generate answers conditioned on a given style. Experiments with MS MARCO 2.1 show that our model achieved state-of-the-art performance on two tasks with different answer styles.