 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbstractive Summarization with Combination of Pre-trained Sequence-to-Sequence and Saliency Models
Mar 29, 2020



Pre-trained sequence-to-sequence (seq-to-seq) models have significantly improved the accuracy of several language generation tasks, including abstractive summarization. Although the fluency of abstractive summarization has been greatly improved by fine-tuning these models, it is not clear whether they can also identify the important parts of the source text to be included in the summary. In this study, we investigated the effectiveness of combining saliency models that identify the important parts of the source text with the pre-trained seq-to-seq models through extensive experiments. We also proposed a new combination model consisting of a saliency model that extracts a token sequence from a source text and a seq-to-seq model that takes the sequence as an additional input text. Experimental results showed that most of the combination models outperformed a simple fine-tuned seq-to-seq model on both the CNN/DM and XSum datasets even if the seq-to-seq model is pre-trained on large-scale corpora. Moreover, for the CNN/DM dataset, the proposed combination model exceeded the previous best-performed model by 1.33 points on ROUGE-L.
Length-controllable Abstractive Summarization by Guiding with Summary Prototype
Jan 21, 2020
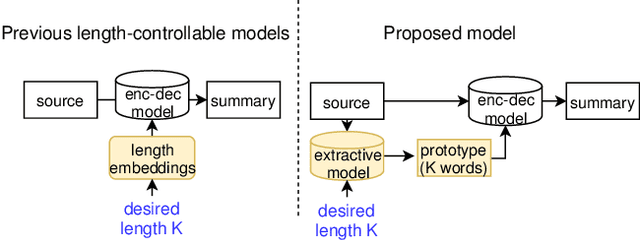
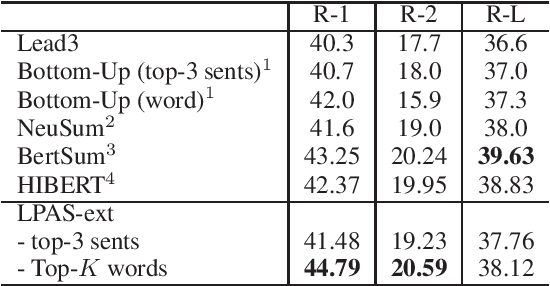
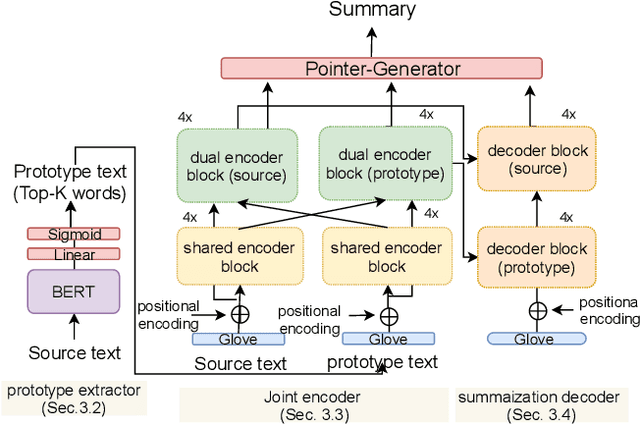
We propose a new length-controllable abstractive summarization model. Recent state-of-the-art abstractive summarization models based on encoder-decoder models generate only one summary per source text. However, controllable summarization, especially of the length, is an important aspect for practical applications. Previous studies on length-controllable abstractive summarization incorporate length embeddings in the decoder module for controlling the summary length. Although the length embeddings can control where to stop decoding, they do not decide which information should be included in the summary within the length constraint. Unlike the previous models, our length-controllable abstractive summarization model incorporates a word-level extractive module in the encoder-decoder model instead of length embeddings. Our model generates a summary in two steps. First, our word-level extractor extracts a sequence of important words (we call it the "prototype text") from the source text according to the word-level importance scores and the length constraint. Second, the prototype text is used as additional input to the encoder-decoder model, which generates a summary by jointly encoding and copying words from both the prototype text and source text. Since the prototype text is a guide to both the content and length of the summary, our model can generate an informative and length-controlled summary. Experiments with the CNN/Daily Mail dataset and the NEWSROOM dataset show that our model outperformed previous models in length-controlled settings.
Unsupervised Domain Adaptation of Language Models for Reading Comprehension
Nov 25, 2019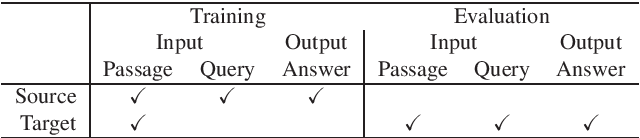
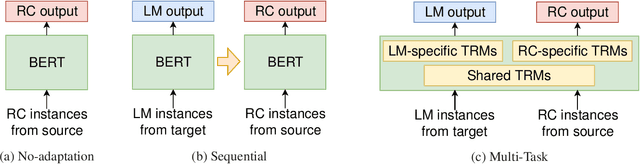

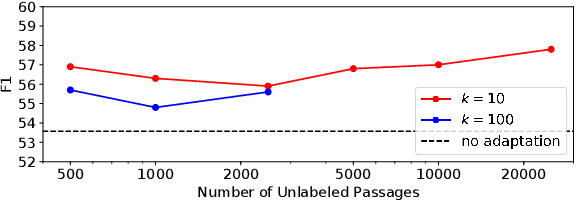
This study tackles unsupervised domain adaptation of reading comprehension (UDARC). Reading comprehension (RC) is a task to learn the capability for question answering with textual sources. State-of-the-art models on RC still do not have general linguistic intelligence; i.e., their accuracy worsens for out-domain datasets that are not used in the training. We hypothesize that this discrepancy is caused by a lack of the language modeling (LM) capability for the out-domain. The UDARC task allows models to use supervised RC training data in the source domain and only unlabeled passages in the target domain. To solve the UDARC problem, we provide two domain adaptation models. The first one learns the out-domain LM and in-domain RC task sequentially. The second one is the proposed model that uses a multi-task learning approach of LM and RC. The models can retain both the RC capability acquired from the supervised data in the source domain and the LM capability from the unlabeled data in the target domain. We evaluated the models on UDARC with five datasets in different domains. The models outperformed the model without domain adaptation. In particular, the proposed model yielded an improvement of 4.3/4.2 points in EM/F1 in an unseen biomedical domain.
A Simple but Effective Method to Incorporate Multi-turn Context with BERT for Conversational Machine Comprehension
May 30, 2019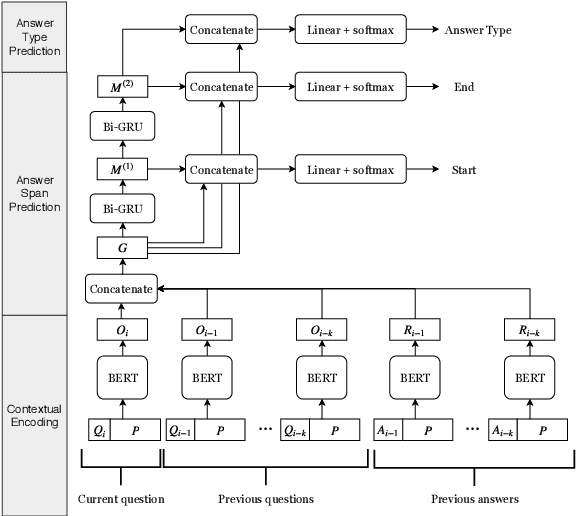
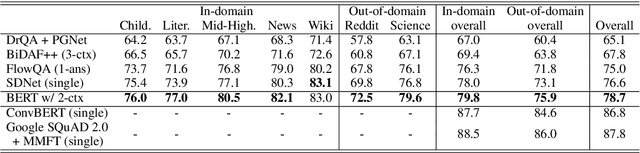
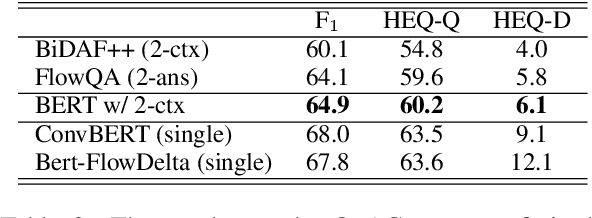

Conversational machine comprehension (CMC) requires understanding the context of multi-turn dialogue. Using BERT, a pre-training language model, has been successful for single-turn machine comprehension, while modeling multiple turns of question answering with BERT has not been established because BERT has a limit on the number and the length of input sequences. In this paper, we propose a simple but effective method with BERT for CMC. Our method uses BERT to encode a paragraph independently conditioned with each question and each answer in a multi-turn context. Then, the method predicts an answer on the basis of the paragraph representations encoded with BERT. The experiments with representative CMC datasets, QuAC and CoQA, show that our method outperformed recently published methods (+0.8 F1 on QuAC and +2.1 F1 on CoQA). In addition, we conducted a detailed analysis of the effects of the number and types of dialogue history on the accuracy of CMC, and we found that the gold answer history, which may not be given in an actual conversation, contributed to the model performance most on both datasets.
Answering while Summarizing: Multi-task Learning for Multi-hop QA with Evidence Extraction
May 29, 2019
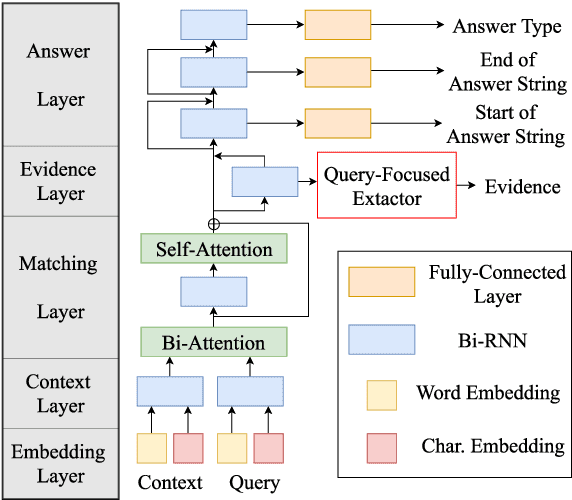
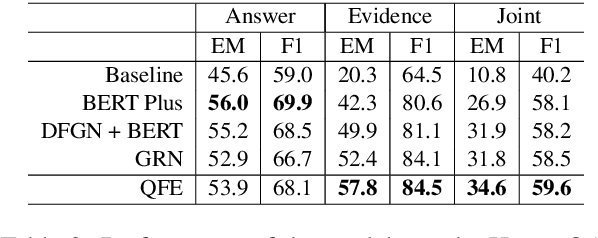
Question answering (QA) using textual sources for purposes such as reading comprehension (RC) has attracted much attention. This study focuses on the task of explainable multi-hop QA, which requires the system to return the answer with evidence sentences by reasoning and gathering disjoint pieces of the reference texts. It proposes the Query Focused Extractor (QFE) model for evidence extraction and uses multi-task learning with the QA model. QFE is inspired by extractive summarization models; compared with the existing method, which extracts each evidence sentence independently, it sequentially extracts evidence sentences by using an RNN with an attention mechanism on the question sentence. It enables QFE to consider the dependency among the evidence sentences and cover important information in the question sentence. Experimental results show that QFE with a simple RC baseline model achieves a state-of-the-art evidence extraction score on HotpotQA. Although designed for RC, it also achieves a state-of-the-art evidence extraction score on FEVER, which is a recognizing textual entailment task on a large textual database.
Multi-style Generative Reading Comprehension
Jan 08, 2019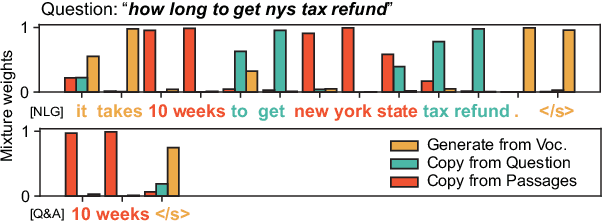

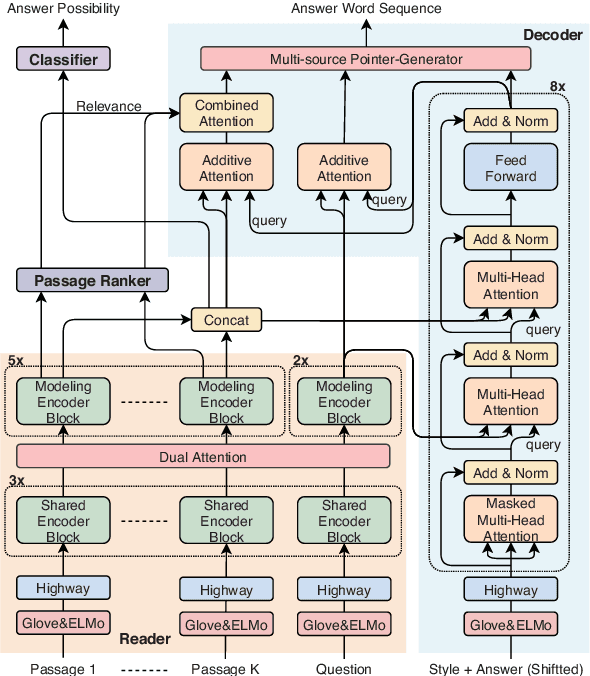
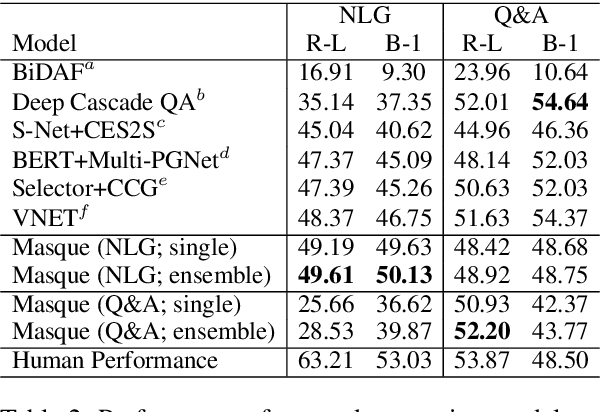
This study focuses on the task of multi-passage reading comprehension (RC) where an answer is provided in natural language. Current mainstream approaches treat RC by extracting the answer span from the provided passages and cannot generate an abstractive summary from the given question and passages. Moreover, they cannot utilize and control different styles of answers, such as concise phrases and well-formed sentences, within a model. In this study, we propose a style-controllable Multi-source Abstractive Summarization model for QUEstion answering, called Masque. The model is an end-to-end deep neural network that can generate answers conditioned on a given style. Experiments with MS MARCO 2.1 show that our model achieved state-of-the-art performance on two tasks with different answer styles.
Retrieve-and-Read: Multi-task Learning of Information Retrieval and Reading Comprehension
Aug 31, 2018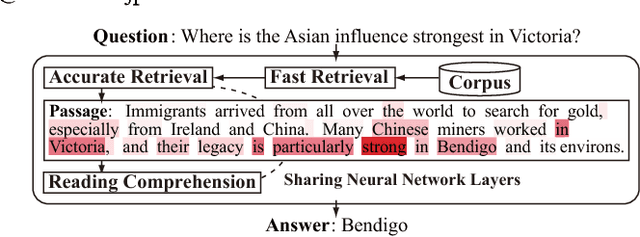
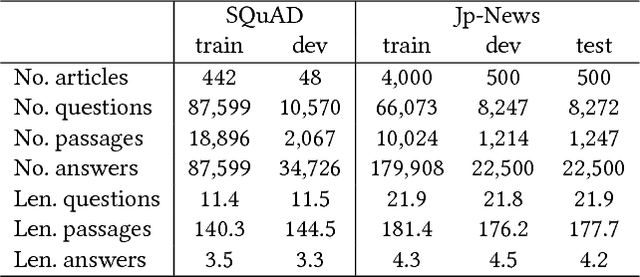
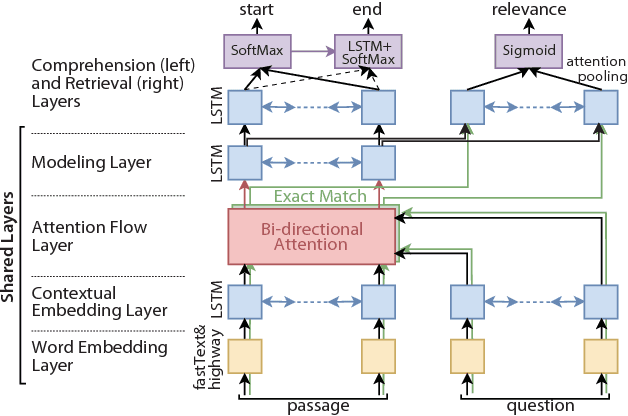
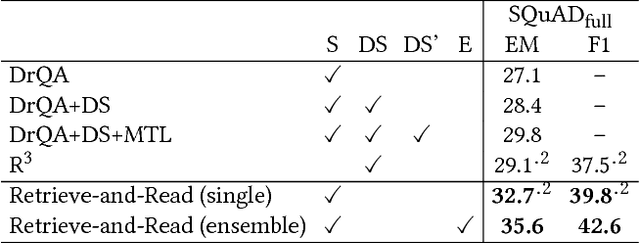
This study considers the task of machine reading at scale (MRS) wherein, given a question, a system first performs the information retrieval (IR) task of finding relevant passages in a knowledge source and then carries out the reading comprehension (RC) task of extracting an answer span from the passages. Previous MRS studies, in which the IR component was trained without considering answer spans, struggled to accurately find a small number of relevant passages from a large set of passages. In this paper, we propose a simple and effective approach that incorporates the IR and RC tasks by using supervised multi-task learning in order that the IR component can be trained by considering answer spans. Experimental results on the standard benchmark, answering SQuAD questions using the full Wikipedia as the knowledge source, showed that our model achieved state-of-the-art performance. Moreover, we thoroughly evaluated the individual contributions of our model components with our new Japanese dataset and SQuAD. The results showed significant improvements in the IR task and provided a new perspective on IR for RC: it is effective to teach which part of the passage answers the question rather than to give only a relevance score to the whole passage.
* 10 pages, 6 figure. Accepted as a full paper at CIKM 2018