 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Question Generation Debias Question Answering Models? A Case Study on Question-Context Lexical Overlap
Paper and Code

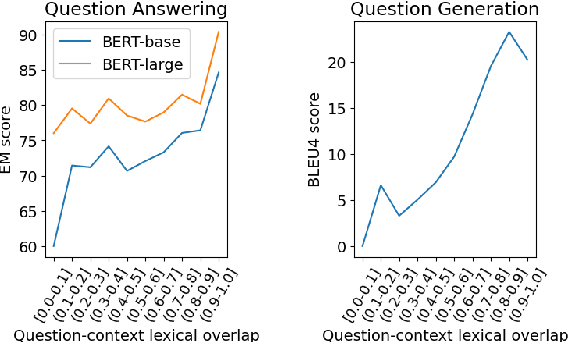
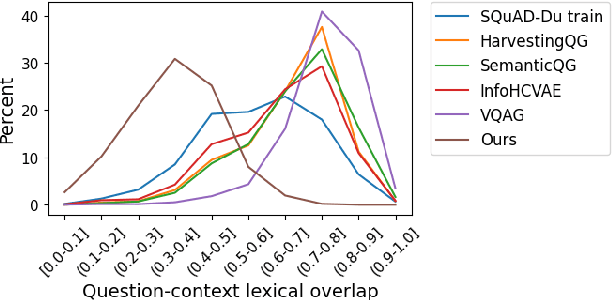
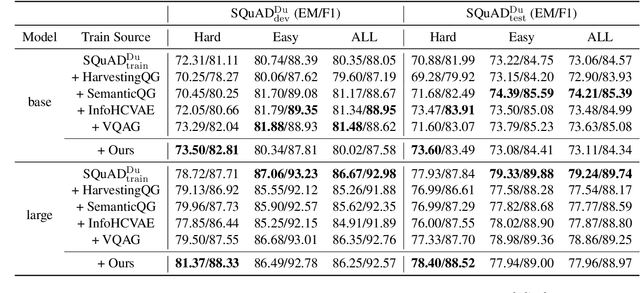
Question answering (QA) models for reading comprehension have been demonstrated to exploit unintended dataset biases such as question-context lexical overlap. This hinders QA models from generalizing to under-represented samples such as questions with low lexical overlap. Question generation (QG), a method for augmenting QA datasets, can be a solution for such performance degradation if QG can properly debias QA datasets. However, we discover that recent neural QG models are biased towards generating questions with high lexical overlap, which can amplify the dataset bias. Moreover, our analysis reveals that data augmentation with these QG models frequently impairs the performance on questions with low lexical overlap, while improving that on questions with high lexical overlap. To address this problem, we use a synonym replacement-based approach to augment questions with low lexical overlap. We demonstrate that the proposed data augmentation approach is simple yet effective to mitigate the degradation problem with only 70k synthetic examples. Our data is publicly available at https://github.com/KazutoshiShinoda/Synonym-Replacement.