 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Robustness to Variations of Objects and Instructions with a Neuro-Symbolic Approach for Interactive Instruction Following
Paper and Code

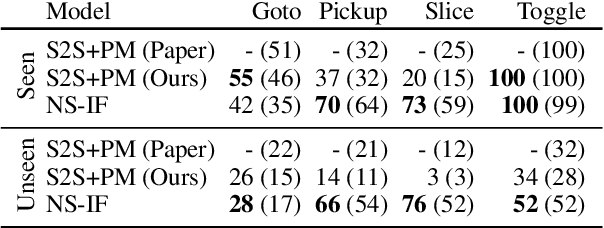
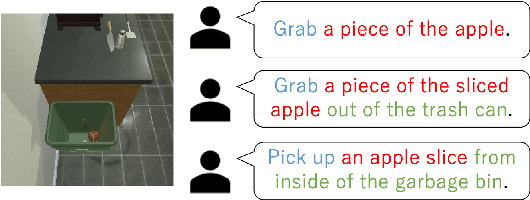
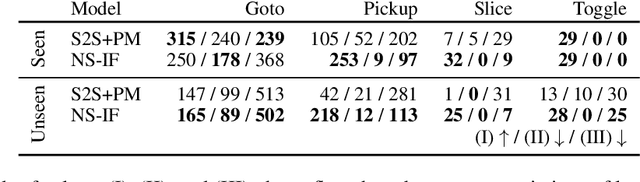
An interactive instruction following task has been proposed as a benchmark for learning to map natural language instructions and first-person vision into sequences of actions to interact with objects in a 3D simulated environment. We find that an existing end-to-end neural model for this task is not robust to variations of objects and language instructions. We assume that this problem is due to the high sensitiveness of neural feature extraction to small changes in vision and language inputs. To mitigate this problem, we propose a neuro-symbolic approach that performs reasoning over high-level symbolic representations that are robust to small changes in raw inputs. Our experiments on the ALFRED dataset show that our approach significantly outperforms the existing model by 18, 52, and 73 points in the success rate on the ToggleObject, PickupObject, and SliceObject subtasks in unseen environments respectively.