 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactor-Conditioned Speaking-Style Captioning
Paper and Code
Jun 27, 2024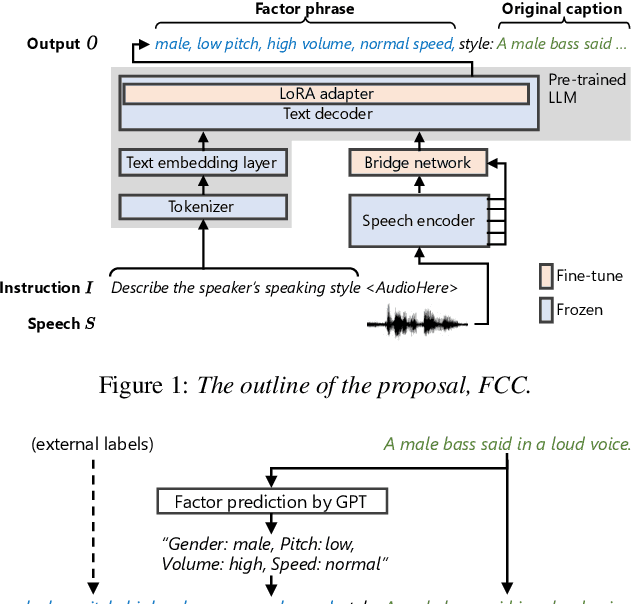



This paper presents a novel speaking-style captioning method that generates diverse descriptions while accurately predicting speaking-style information. Conventional learning criteria directly use original captions that contain not only speaking-style factor terms but also syntax words, which disturbs learning speaking-style information. To solve this problem, we introduce factor-conditioned captioning (FCC), which first outputs a phrase representing speaking-style factors (e.g., gender, pitch, etc.), and then generates a caption to ensure the model explicitly learns speaking-style factors. We also propose greedy-then-sampling (GtS) decoding, which first predicts speaking-style factors deterministically to guarantee semantic accuracy, and then generates a caption based on factor-conditioned sampling to ensure diversity. Experiments show that FCC outperforms the original caption-based training, and with GtS, it generates more diverse captions while keeping style prediction performance.