 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Data Augmentation Methods for End-to-End Task-Oriented Dialog Systems
Jun 10, 2024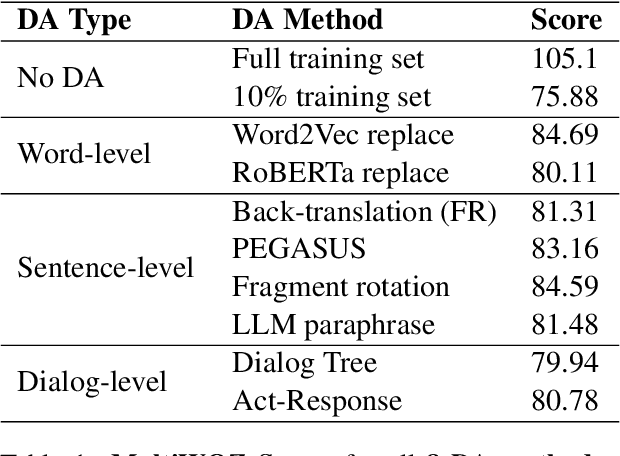
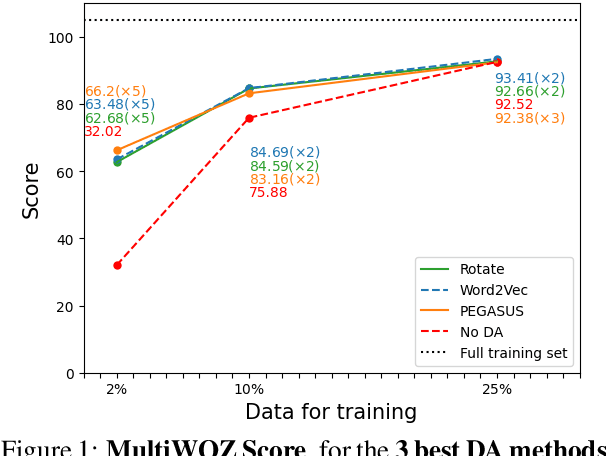
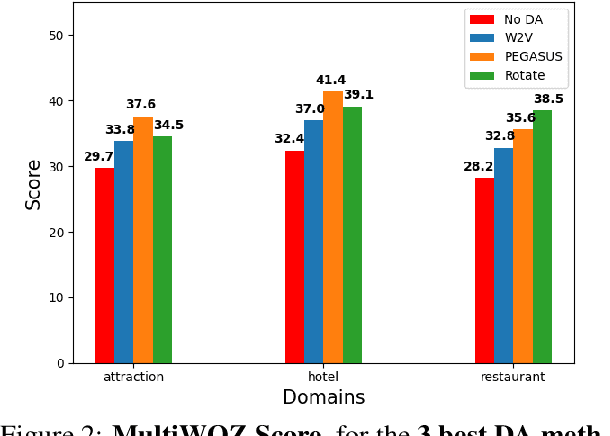

Creating effective and reliable task-oriented dialog systems (ToDSs) is challenging, not only because of the complex structure of these systems, but also due to the scarcity of training data, especially when several modules need to be trained separately, each one with its own input/output training examples. Data augmentation (DA), whereby synthetic training examples are added to the training data, has been successful in other NLP systems, but has not been explored as extensively in ToDSs. We empirically evaluate the effectiveness of DA methods in an end-to-end ToDS setting, where a single system is trained to handle all processing stages, from user inputs to system outputs. We experiment with two ToDSs (UBAR, GALAXY) on two datasets (MultiWOZ, KVRET). We consider three types of DA methods (word-level, sentence-level, dialog-level), comparing eight DA methods that have shown promising results in ToDSs and other NLP systems. We show that all DA methods considered are beneficial, and we highlight the best ones, also providing advice to practitioners. We also introduce a more challenging few-shot cross-domain ToDS setting, reaching similar conclusions.