 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Utility of Surprisal from Large Language Models for Speech Synthesis Prosody
Jun 16, 2023This paper investigates the use of word surprisal, a measure of the predictability of a word in a given context, as a feature to aid speech synthesis prosody. We explore how word surprisal extracted from large language models (LLMs) correlates with word prominence, a signal-based measure of the salience of a word in a given discourse. We also examine how context length and LLM size affect the results, and how a speech synthesizer conditioned with surprisal values compares with a baseline system. To evaluate these factors, we conducted experiments using a large corpus of English text and LLMs of varying sizes. Our results show that word surprisal and word prominence are moderately correlated, suggesting that they capture related but distinct aspects of language use. We find that length of context and size of the LLM impact the correlations, but not in the direction anticipated, with longer contexts and larger LLMs generally underpredicting prominent words in a nearly linear manner. We demonstrate that, in line with these findings, a speech synthesizer conditioned with surprisal values provides a minimal improvement over the baseline with the results suggesting a limited effect of using surprisal values for eliciting appropriate prominence patterns.
The Power of Prosody and Prosody of Power: An Acoustic Analysis of Finnish Parliamentary Speech
May 25, 2023Parliamentary recordings provide a rich source of data for studying how politicians use speech to convey their messages and influence their audience. This provides a unique context for studying how politicians use speech, especially prosody, to achieve their goals. Here we analyzed a corpus of parliamentary speeches in the Finnish parliament between the years 2008-2020 and highlight methodological considerations related to the robustness of signal based features with respect to varying recording conditions and corpus design. We also present results of long term changes pertaining to speakers' status with respect to their party being in government or in opposition. Looking at large scale averages of fundamental frequency - a robust prosodic feature - we found systematic changes in speech prosody with respect opposition status and the election term. Reflecting a different level of urgency, members of the parliament have higher f0 at the beginning of the term or when they are in opposition.
Predicting Prosodic Prominence from Text with Pre-trained Contextualized Word Representations
Aug 06, 2019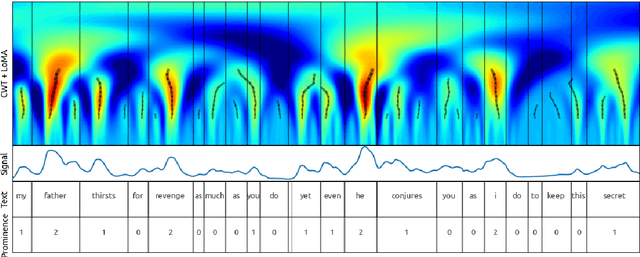
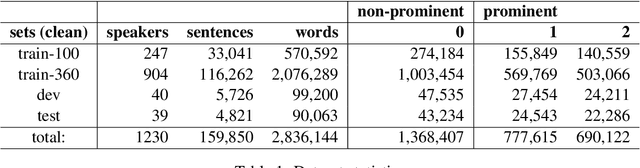

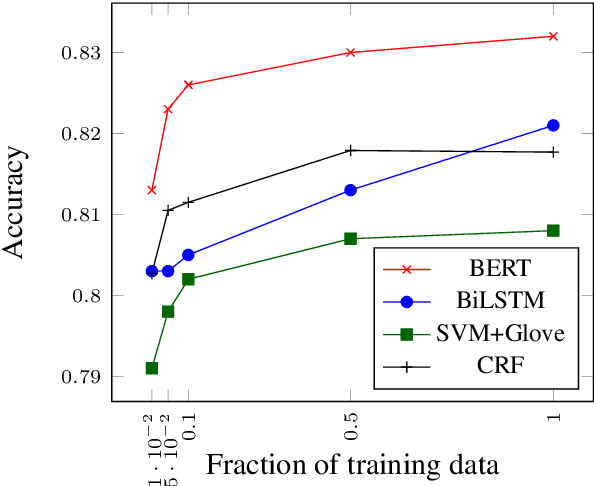
In this paper we introduce a new natural language processing dataset and benchmark for predicting prosodic prominence from written text. To our knowledge this will be the largest publicly available dataset with prosodic labels. We describe the dataset construction and the resulting benchmark dataset in detail and train a number of different models ranging from feature-based classifiers to neural network systems for the prediction of discretized prosodic prominence. We show that pre-trained contextualized word representations from BERT outperform the other models even with less than 10% of the training data. Finally we discuss the dataset in light of the results and point to future research and plans for further improving both the dataset and methods of predicting prosodic prominence from text. The dataset and the code for the models are publicly available.
Hierarchical Representation of Prosody for Statistical Speech Synthesis
Oct 07, 2015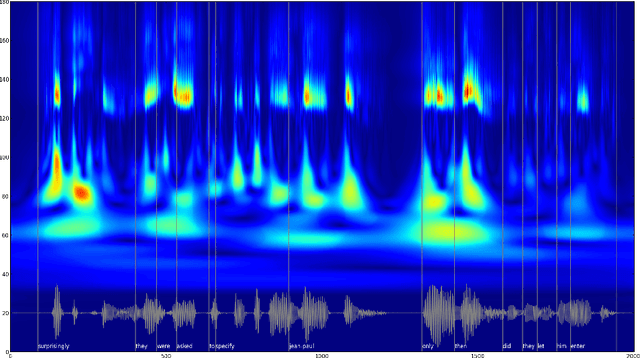
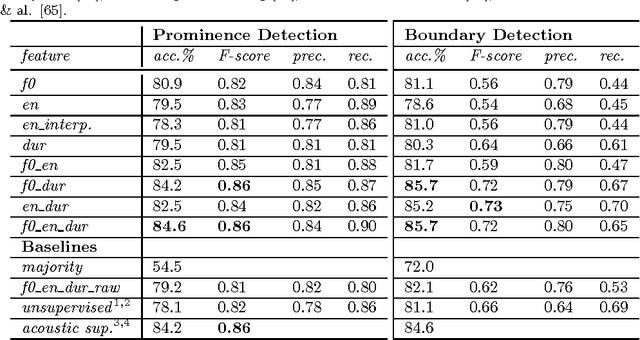
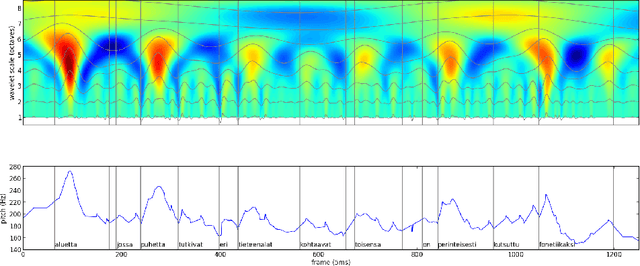
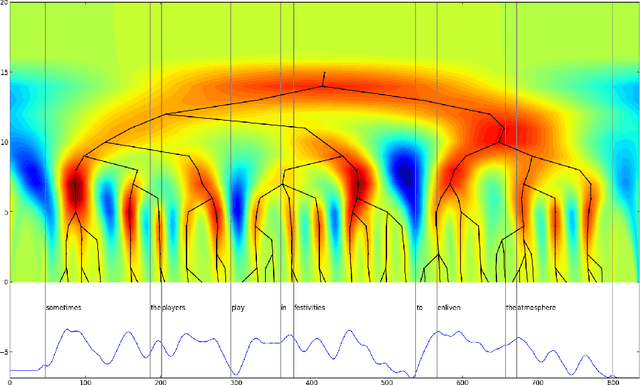
Prominences and boundaries are the essential constituents of prosodic structure in speech. They provide for means to chunk the speech stream into linguistically relevant units by providing them with relative saliences and demarcating them within coherent utterance structures. Prominences and boundaries have both been widely used in both basic research on prosody as well as in text-to-speech synthesis. However, there are no representation schemes that would provide for both estimating and modelling them in a unified fashion. Here we present an unsupervised unified account for estimating and representing prosodic prominences and boundaries using a scale-space analysis based on continuous wavelet transform. The methods are evaluated and compared to earlier work using the Boston University Radio News corpus. The results show that the proposed method is comparable with the best published supervised annotation methods.