 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Bracketing Encodings for Dependency Parsing as Tagging
May 16, 2025We present a family of encodings for sequence labeling dependency parsing, based on the concept of hierarchical bracketing. We prove that the existing 4-bit projective encoding belongs to this family, but it is suboptimal in the number of labels used to encode a tree. We derive an optimal hierarchical bracketing, which minimizes the number of symbols used and encodes projective trees using only 12 distinct labels (vs. 16 for the 4-bit encoding). We also extend optimal hierarchical bracketing to support arbitrary non-projectivity in a more compact way than previous encodings. Our new encodings yield competitive accuracy on a diverse set of treebanks.
HELFI: a Hebrew-Greek-Finnish Parallel Bible Corpus with Cross-Lingual Morpheme Alignment
Mar 16, 2020
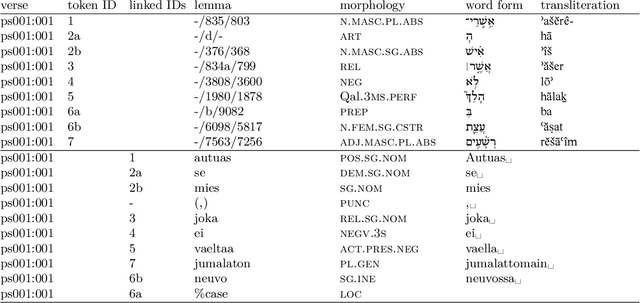
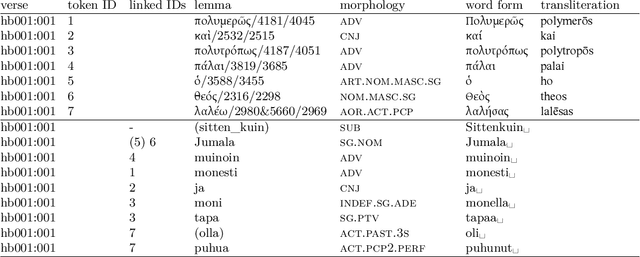
Twenty-five years ago, morphologically aligned Hebrew-Finnish and Greek-Finnish bitexts (texts accompanied by a translation) were constructed manually in order to create an analytical concordance (Luoto et al., 1997) for a Finnish Bible translation. The creators of the bitexts recently secured the publisher's permission to release its fine-grained alignment, but the alignment was still dependent on proprietary, third-party resources such as a copyrighted text edition and proprietary morphological analyses of the source texts. In this paper, we describe a nontrivial editorial process starting from the creation of the original one-purpose database and ending with its reconstruction using only freely available text editions and annotations. This process produced an openly available dataset that contains (i) the source texts and their translations, (ii) the morphological analyses, (iii) the cross-lingual morpheme alignments.
Natural Language Inference with Hierarchical BiLSTM Max Pooling Architecture
Aug 27, 2018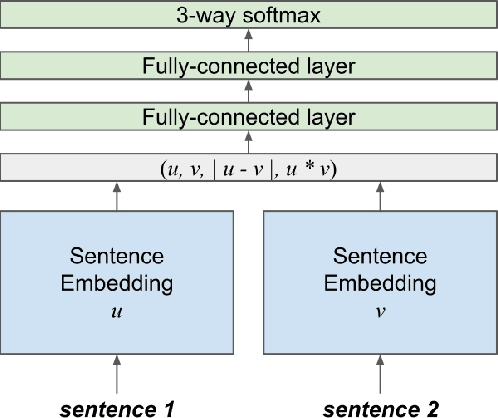

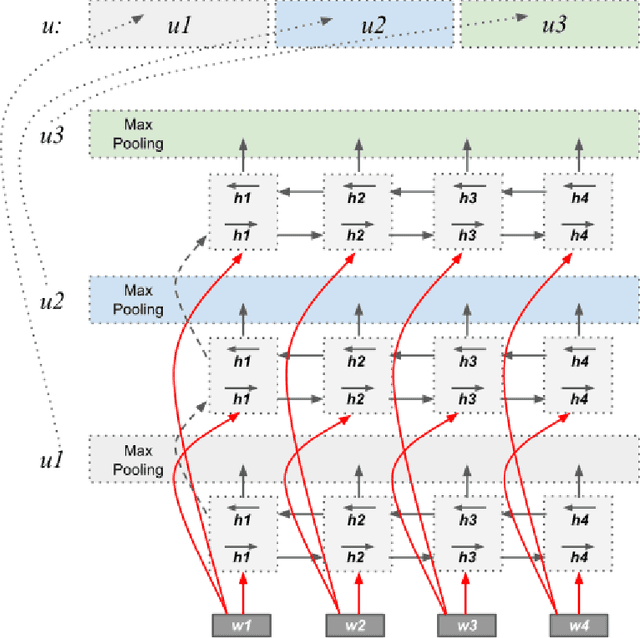

Recurrent neural networks have proven to be very effective for natural language inference tasks. We build on top of one such model, namely BiLSTM with max pooling, and show that adding a hierarchy of BiLSTM and max pooling layers yields state of the art results for the SNLI sentence encoding-based models and the SciTail dataset, as well as provides strong results for the MultiNLI dataset. We also show that our sentence embeddings can be utilized in a wide variety of transfer learning tasks, outperforming InferSent on 7 out of 10 and SkipThought on 8 out of 9 SentEval sentence embedding evaluation tasks. Furthermore, our model beats the InferSent model in 8 out of 10 recently published SentEval probing tasks designed to evaluate sentence embeddings' ability to capture some of the important linguistic properties of sentences.
The Power of Constraint Grammars Revisited
Jul 17, 2017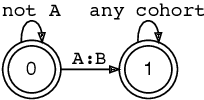
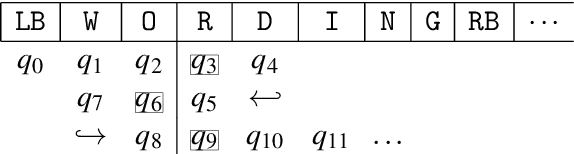
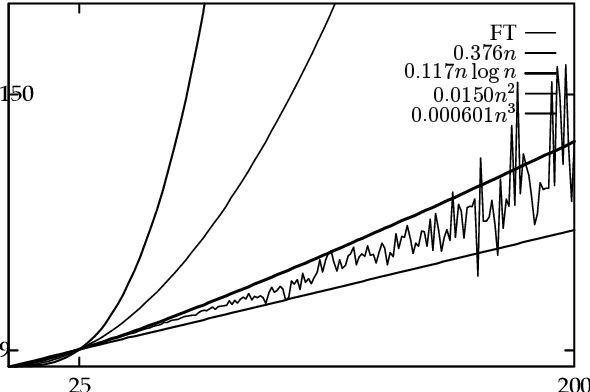
Sequential Constraint Grammar (SCG) (Karlsson, 1990) and its extensions have lacked clear connections to formal language theory. The purpose of this article is to lay a foundation for these connections by simplifying the definition of strings processed by the grammar and by showing that Nonmonotonic SCG is undecidable and that derivations similar to the Generative Phonology exist. The current investigations propose resource bounds that restrict the generative power of SCG to a subset of context sensitive languages and present a strong finite-state condition for grammars as wholes. We show that a grammar is equivalent to a finite-state transducer if it is implemented with a Turing machine that runs in o(n log n) time. This condition opens new finite-state hypotheses and avenues for deeper analysis of SCG instances in the way inspired by Finite-State Phonology.
* 9 pages, 4 figures
Generic Axiomatization of Families of Noncrossing Graphs in Dependency Parsing
Jun 11, 2017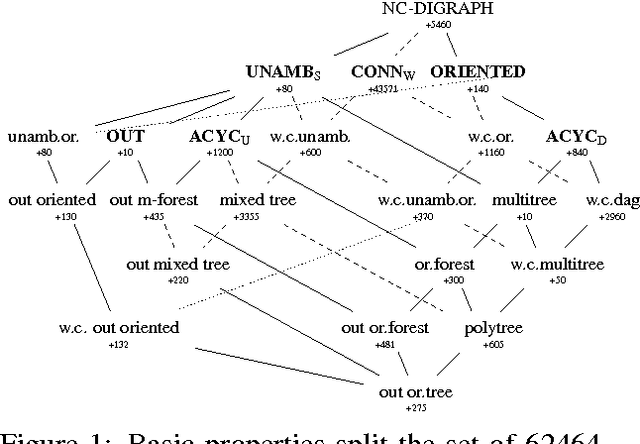


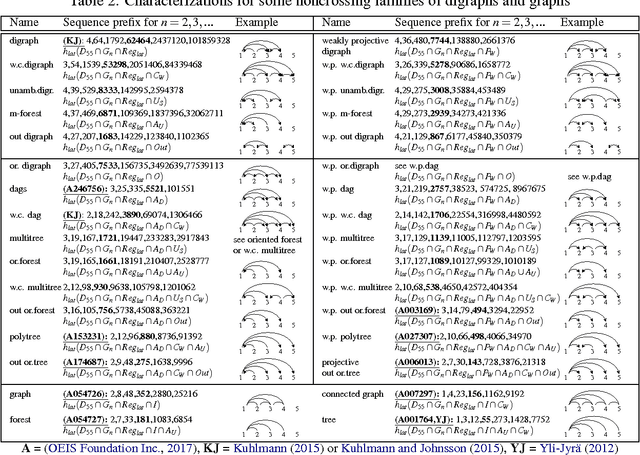
We present a simple encoding for unlabeled noncrossing graphs and show how its latent counterpart helps us to represent several families of directed and undirected graphs used in syntactic and semantic parsing of natural language as context-free languages. The families are separated purely on the basis of forbidden patterns in latent encoding, eliminating the need to differentiate the families of non-crossing graphs in inference algorithms: one algorithm works for all when the search space can be controlled in parser input.