 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Bracketing Encodings Work for Dependency Graphs
Sep 11, 2025We revisit hierarchical bracketing encodings from a practical perspective in the context of dependency graph parsing. The approach encodes graphs as sequences, enabling linear-time parsing with $n$ tagging actions, and still representing reentrancies, cycles, and empty nodes. Compared to existing graph linearizations, this representation substantially reduces the label space while preserving structural information. We evaluate it on a multilingual and multi-formalism benchmark, showing competitive results and consistent improvements over other methods in exact match accuracy.
LyS at SemEval 2025 Task 8: Zero-Shot Code Generation for Tabular QA
Aug 12, 2025This paper describes our participation in SemEval 2025 Task 8, focused on Tabular Question Answering. We developed a zero-shot pipeline that leverages an Large Language Model to generate functional code capable of extracting the relevant information from tabular data based on an input question. Our approach consists of a modular pipeline where the main code generator module is supported by additional components that identify the most relevant columns and analyze their data types to improve extraction accuracy. In the event that the generated code fails, an iterative refinement process is triggered, incorporating the error feedback into a new generation prompt to enhance robustness. Our results show that zero-shot code generation is a valid approach for Tabular QA, achieving rank 33 of 53 in the test phase despite the lack of task-specific fine-tuning.
Hierarchical Bracketing Encodings for Dependency Parsing as Tagging
May 16, 2025We present a family of encodings for sequence labeling dependency parsing, based on the concept of hierarchical bracketing. We prove that the existing 4-bit projective encoding belongs to this family, but it is suboptimal in the number of labels used to encode a tree. We derive an optimal hierarchical bracketing, which minimizes the number of symbols used and encodes projective trees using only 12 distinct labels (vs. 16 for the 4-bit encoding). We also extend optimal hierarchical bracketing to support arbitrary non-projectivity in a more compact way than previous encodings. Our new encodings yield competitive accuracy on a diverse set of treebanks.
Better Benchmarking LLMs for Zero-Shot Dependency Parsing
Feb 28, 2025While LLMs excel in zero-shot tasks, their performance in linguistic challenges like syntactic parsing has been less scrutinized. This paper studies state-of-the-art open-weight LLMs on the task by comparing them to baselines that do not have access to the input sentence, including baselines that have not been used in this context such as random projective trees or optimal linear arrangements. The results show that most of the tested LLMs cannot outperform the best uninformed baselines, with only the newest and largest versions of LLaMA doing so for most languages, and still achieving rather low performance. Thus, accurate zero-shot syntactic parsing is not forthcoming with open LLMs.
Dependency Graph Parsing as Sequence Labeling
Oct 23, 2024
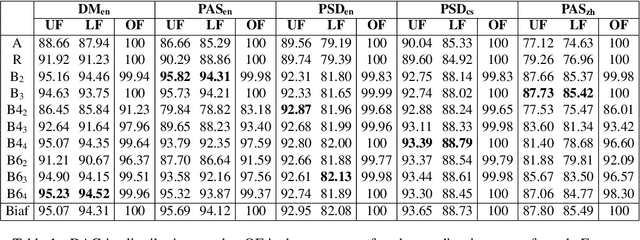
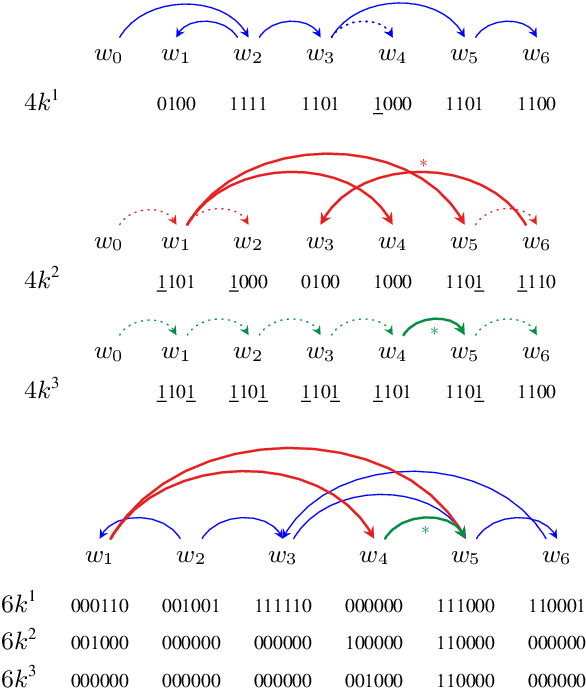

Various linearizations have been proposed to cast syntactic dependency parsing as sequence labeling. However, these approaches do not support more complex graph-based representations, such as semantic dependencies or enhanced universal dependencies, as they cannot handle reentrancy or cycles. By extending them, we define a range of unbounded and bounded linearizations that can be used to cast graph parsing as a tagging task, enlarging the toolbox of problems that can be solved under this paradigm. Experimental results on semantic dependency and enhanced UD parsing show that with a good choice of encoding, sequence-labeling dependency graph parsers combine high efficiency with accuracies close to the state of the art, in spite of their simplicity.
LyS at SemEval-2024 Task 3: An Early Prototype for End-to-End Multimodal Emotion Linking as Graph-Based Parsing
May 10, 2024This paper describes our participation in SemEval 2024 Task 3, which focused on Multimodal Emotion Cause Analysis in Conversations. We developed an early prototype for an end-to-end system that uses graph-based methods from dependency parsing to identify causal emotion relations in multi-party conversations. Our model comprises a neural transformer-based encoder for contextualizing multimodal conversation data and a graph-based decoder for generating the adjacency matrix scores of the causal graph. We ranked 7th out of 15 valid and official submissions for Subtask 1, using textual inputs only. We also discuss our participation in Subtask 2 during post-evaluation using multi-modal inputs.
From Partial to Strictly Incremental Constituent Parsing
Feb 05, 2024



We study incremental constituent parsers to assess their capacity to output trees based on prefix representations alone. Guided by strictly left-to-right generative language models and tree-decoding modules, we build parsers that adhere to a strong definition of incrementality across languages. This builds upon work that asserted incrementality, but that mostly only enforced it on either the encoder or the decoder. Finally, we conduct an analysis against non-incremental and partially incremental models.
On the Challenges of Fully Incremental Neural Dependency Parsing
Sep 28, 2023Since the popularization of BiLSTMs and Transformer-based bidirectional encoders, state-of-the-art syntactic parsers have lacked incrementality, requiring access to the whole sentence and deviating from human language processing. This paper explores whether fully incremental dependency parsing with modern architectures can be competitive. We build parsers combining strictly left-to-right neural encoders with fully incremental sequence-labeling and transition-based decoders. The results show that fully incremental parsing with modern architectures considerably lags behind bidirectional parsing, noting the challenges of psycholinguistically plausible parsing.