 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERTGEN: Multi-task Generation through BERT
Jun 07, 2021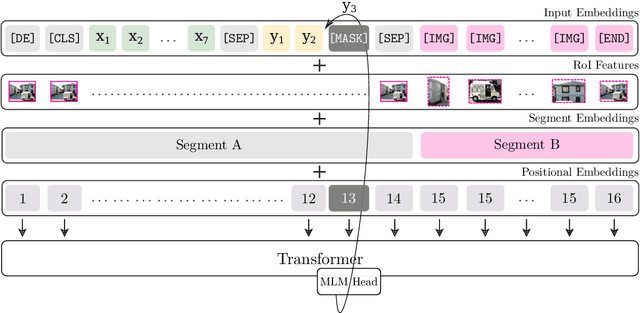

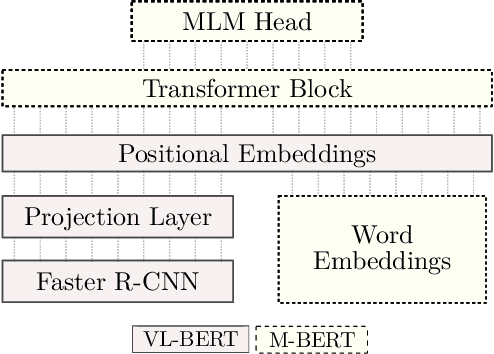

We present BERTGEN, a novel generative, decoder-only model which extends BERT by fusing multimodal and multilingual pretrained models VL-BERT and M-BERT, respectively. BERTGEN is auto-regressively trained for language generation tasks, namely image captioning, machine translation and multimodal machine translation, under a multitask setting. With a comprehensive set of evaluations, we show that BERTGEN outperforms many strong baselines across the tasks explored. We also show BERTGEN's ability for zero-shot language generation, where it exhibits competitive performance to supervised counterparts. Finally, we conduct ablation studies which demonstrate that BERTGEN substantially benefits from multi-tasking and effectively transfers relevant inductive biases from the pre-trained models.