 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Visual Attention for Simultaneous Multimodal Machine Translation
Jan 23, 2022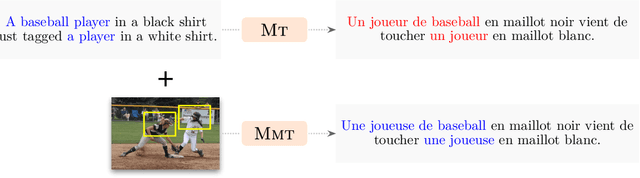
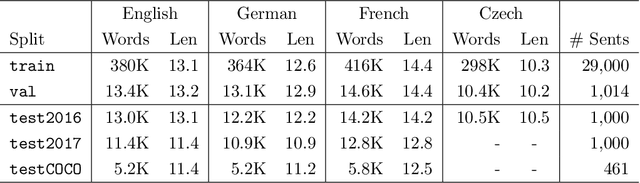
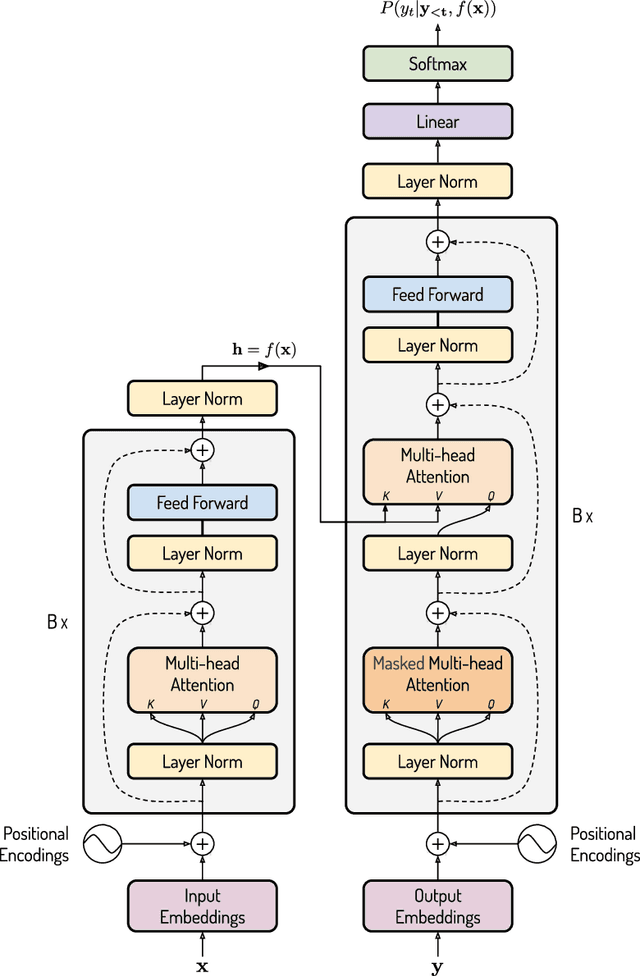
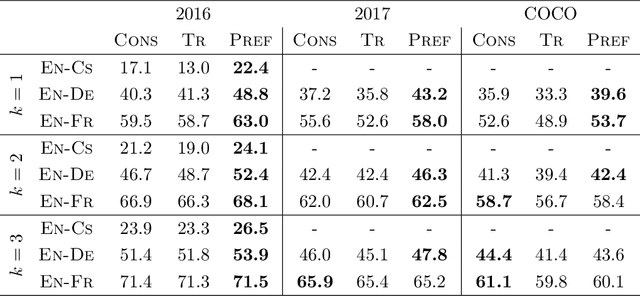
Recently, there has been a surge in research in multimodal machine translation (MMT), where additional modalities such as images are used to improve translation quality of textual systems. A particular use for such multimodal systems is the task of simultaneous machine translation, where visual context has been shown to complement the partial information provided by the source sentence, especially in the early phases of translation (Caglayanet al., 2020a; Imankulova et al., 2020). In this paper, we propose the first Transformer-based simultaneous MMT architecture, which has not been previously explored in the field. Additionally, we extend this model with an auxiliary supervision signal that guides its visual attention mechanism using labelled phrase-region alignments. We perform comprehensive experiments on three language directions and conduct thorough quantitative and qualitative analyses using both automatic metrics and manual inspection. Our results show that (i) supervised visual attention consistently improves the translation quality of the MMT models, and (ii) fine-tuning the MMT with supervision loss enabled leads to better performance than training the MMT from scratch. Compared to the state-of-the-art, our proposed model achieves improvements of up to 2.3 BLEU and 3.5 METEOR points.
A Systematic Comparison of Encrypted Machine Learning Solutions for Image Classification
Nov 11, 2020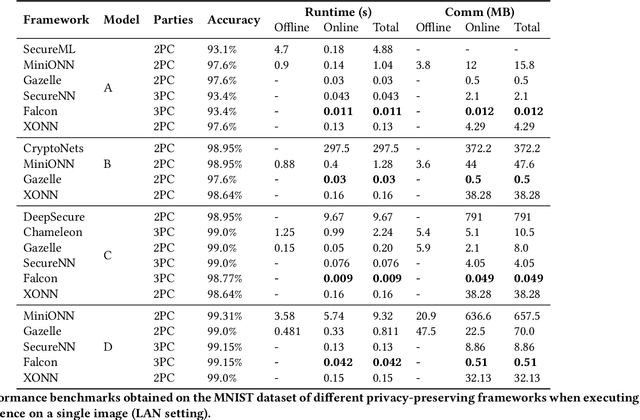

This work provides a comprehensive review of existing frameworks based on secure computing techniques in the context of private image classification. The in-depth analysis of these approaches is followed by careful examination of their performance costs, in particular runtime and communication overhead. To further illustrate the practical considerations when using different privacy-preserving technologies, experiments were conducted using four state-of-the-art libraries implementing secure computing at the heart of the data science stack: PySyft and CrypTen supporting private inference via Secure Multi-Party Computation, TF-Trusted utilising Trusted Execution Environments and HE- Transformer relying on Homomorphic encryption. Our work aims to evaluate the suitability of these frameworks from a usability, runtime requirements and accuracy point of view. In order to better understand the gap between state-of-the-art protocols and what is currently available in practice for a data scientist, we designed three neural network architecture to obtain secure predictions via each of the four aforementioned frameworks. Two networks were evaluated on the MNIST dataset and one on the Malaria Cell image dataset. We observed satisfying performances for TF-Trusted and CrypTen and noted that all frameworks perfectly preserved the accuracy of the corresponding plaintext model.
Simultaneous Machine Translation with Visual Context
Oct 13, 2020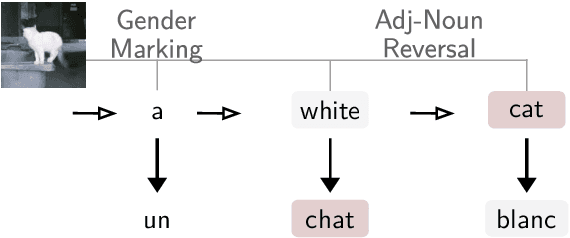
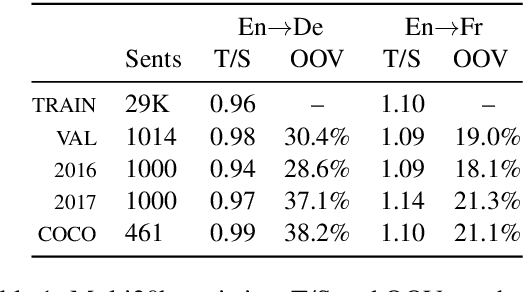
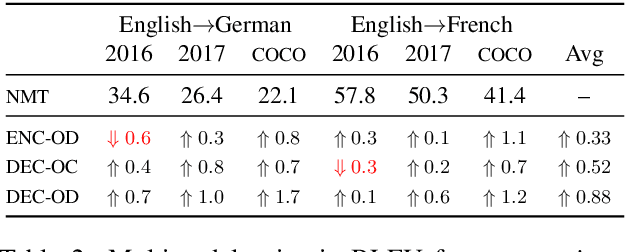
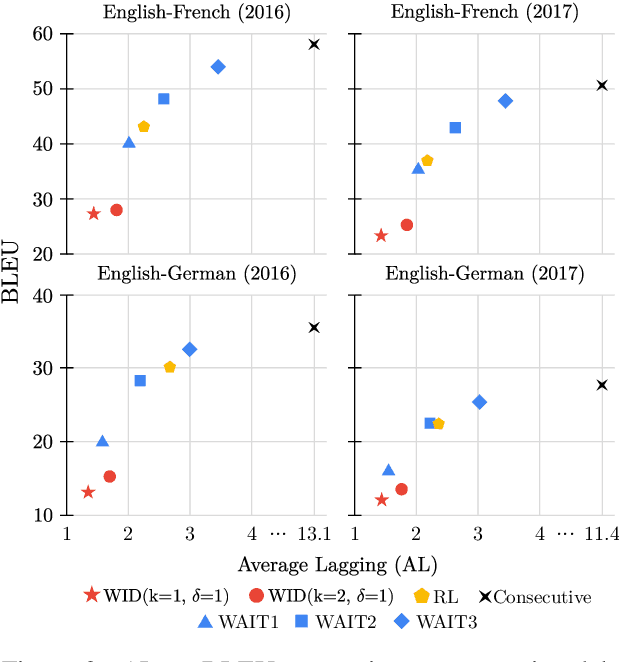
Simultaneous machine translation (SiMT) aims to translate a continuous input text stream into another language with the lowest latency and highest quality possible. The translation thus has to start with an incomplete source text, which is read progressively, creating the need for anticipation. In this paper, we seek to understand whether the addition of visual information can compensate for the missing source context. To this end, we analyse the impact of different multimodal approaches and visual features on state-of-the-art SiMT frameworks. Our results show that visual context is helpful and that visually-grounded models based on explicit object region information are much better than commonly used global features, reaching up to 3 BLEU points improvement under low latency scenarios. Our qualitative analysis illustrates cases where only the multimodal systems are able to translate correctly from English into gender-marked languages, as well as deal with differences in word order, such as adjective-noun placement between English and French.