 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformer-based Ultrasound-to-Speech Conversion
Jun 04, 2025Deep neural networks have shown promising potential for ultrasound-to-speech conversion task towards Silent Speech Interfaces. In this work, we applied two Conformer-based DNN architectures (Base and one with bi-LSTM) for this task. Speaker-specific models were trained on the data of four speakers from the Ultrasuite-Tal80 dataset, while the generated mel spectrograms were synthesized to audio waveform using a HiFi-GAN vocoder. Compared to a standard 2D-CNN baseline, objective measurements (MSE and mel cepstral distortion) showed no statistically significant improvement for either model. However, a MUSHRA listening test revealed that Conformer with bi-LSTM provided better perceptual quality, while Conformer Base matched the performance of the baseline along with a 3x faster training time due to its simpler architecture. These findings suggest that Conformer-based models, especially the Conformer with bi-LSTM, offer a promising alternative to CNNs for ultrasound-to-speech conversion.
Adaptation of Tongue Ultrasound-Based Silent Speech Interfaces Using Spatial Transformer Networks
May 31, 2023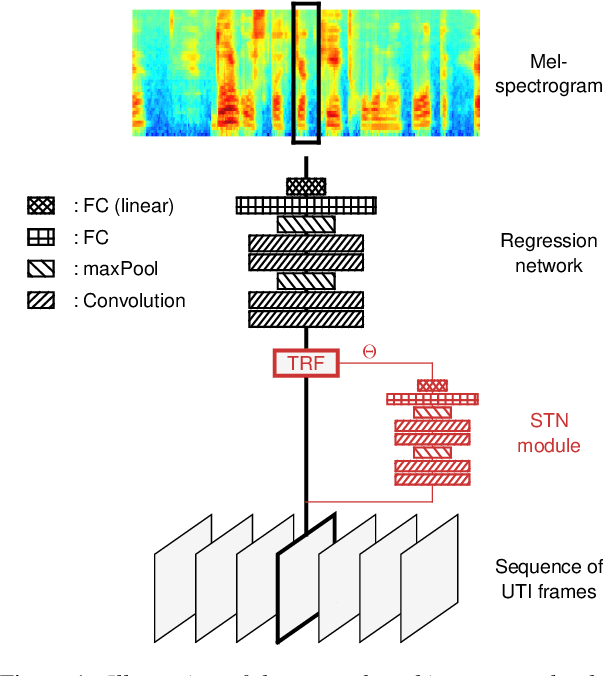
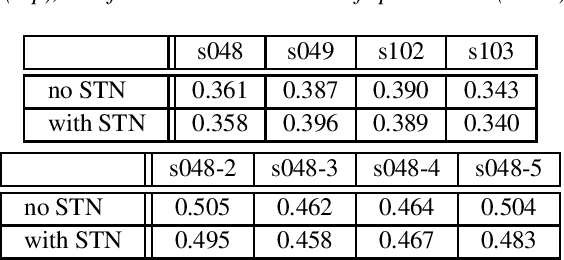
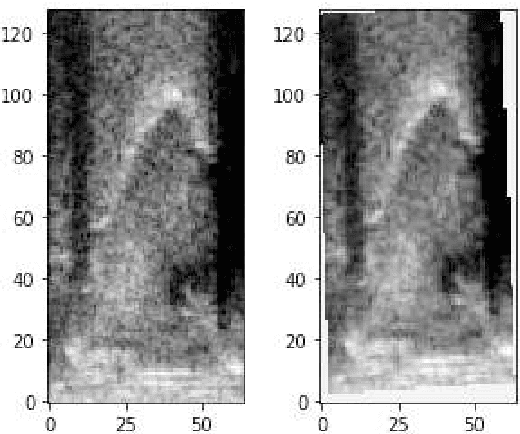
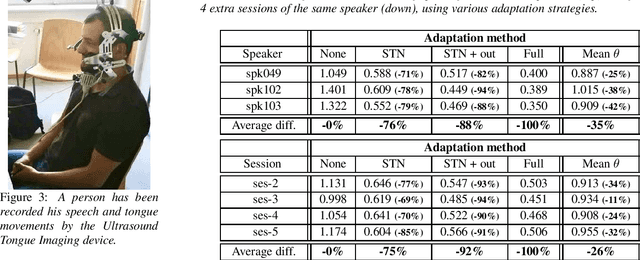
Thanks to the latest deep learning algorithms, silent speech interfaces (SSI) are now able to synthesize intelligible speech from articulatory movement data under certain conditions. However, the resulting models are rather speaker-specific, making a quick switch between users troublesome. Even for the same speaker, these models perform poorly cross-session, i.e. after dismounting and re-mounting the recording equipment. To aid quick speaker and session adaptation of ultrasound tongue imaging-based SSI models, we extend our deep networks with a spatial transformer network (STN) module, capable of performing an affine transformation on the input images. Although the STN part takes up only about 10% of the network, our experiments show that adapting just the STN module might allow to reduce MSE by 88% on the average, compared to retraining the whole network. The improvement is even larger (around 92%) when adapting the network to different recording sessions from the same speaker.
Adaptation of Tacotron2-based Text-To-Speech for Articulatory-to-Acoustic Mapping using Ultrasound Tongue Imaging
Jul 26, 2021
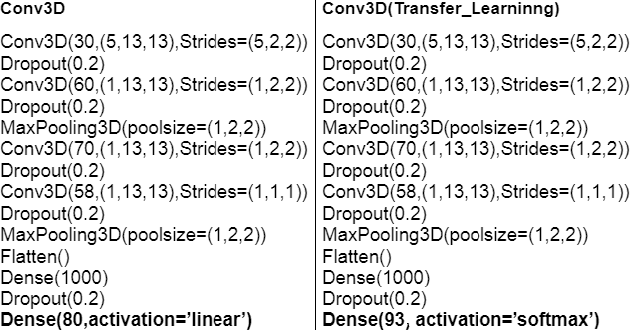
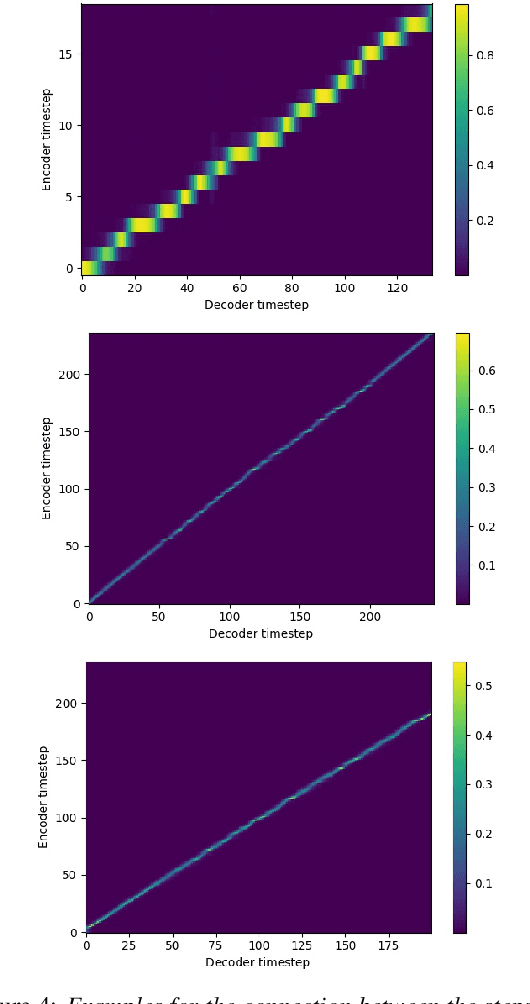
For articulatory-to-acoustic mapping, typically only limited parallel training data is available, making it impossible to apply fully end-to-end solutions like Tacotron2. In this paper, we experimented with transfer learning and adaptation of a Tacotron2 text-to-speech model to improve the final synthesis quality of ultrasound-based articulatory-to-acoustic mapping with a limited database. We use a multi-speaker pre-trained Tacotron2 TTS model and a pre-trained WaveGlow neural vocoder. The articulatory-to-acoustic conversion contains three steps: 1) from a sequence of ultrasound tongue image recordings, a 3D convolutional neural network predicts the inputs of the pre-trained Tacotron2 model, 2) the Tacotron2 model converts this intermediate representation to an 80-dimensional mel-spectrogram, and 3) the WaveGlow model is applied for final inference. This generated speech contains the timing of the original articulatory data from the ultrasound recording, but the F0 contour and the spectral information is predicted by the Tacotron2 model. The F0 values are independent of the original ultrasound images, but represent the target speaker, as they are inferred from the pre-trained Tacotron2 model. In our experiments, we demonstrated that the synthesized speech quality is more natural with the proposed solutions than with our earlier model.
Speech Synthesis from Text and Ultrasound Tongue Image-based Articulatory Input
Jul 05, 2021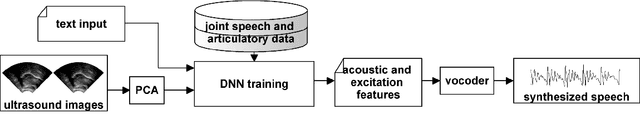
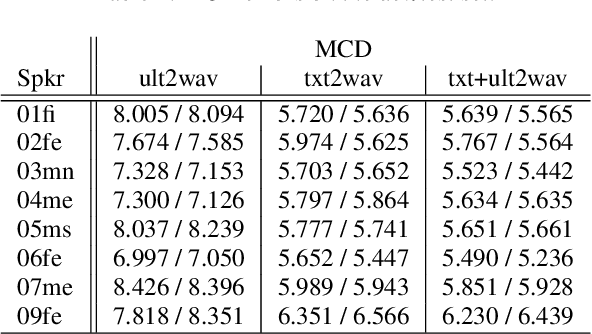
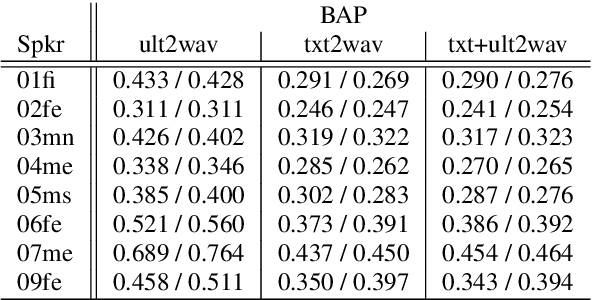
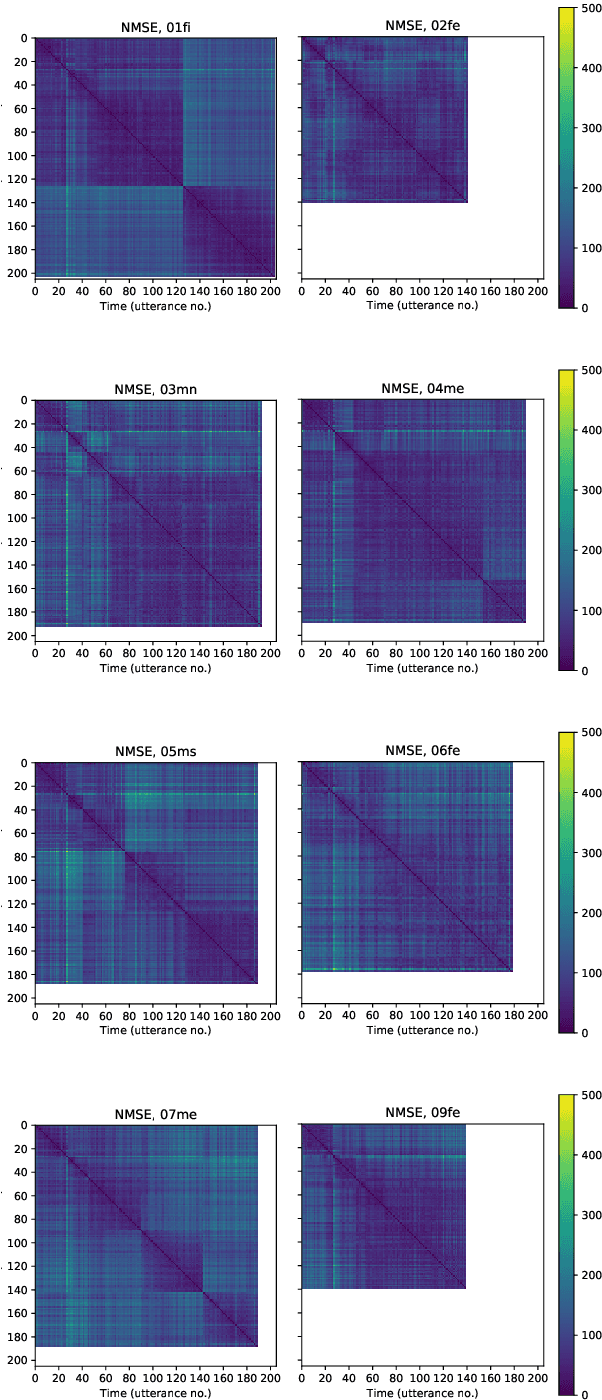
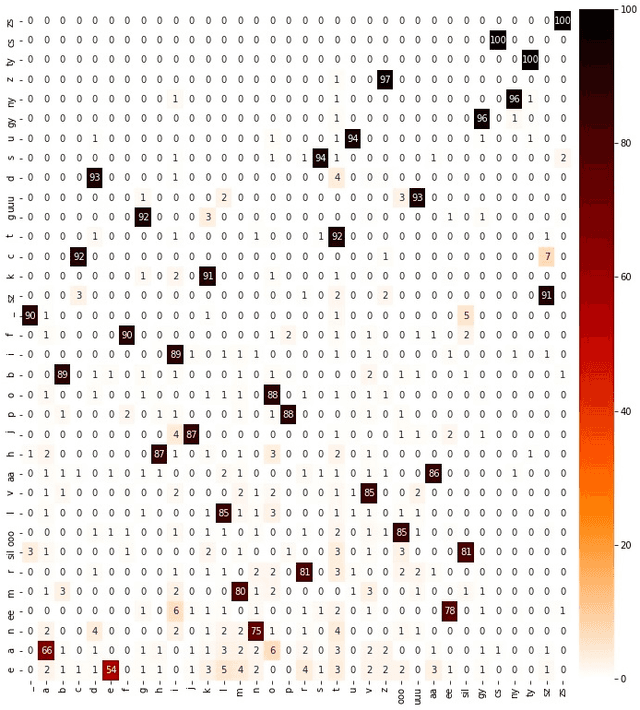
Articulatory information has been shown to be effective in improving the performance of HMM-based and DNN-based text-to-speech synthesis. Speech synthesis research focuses traditionally on text-to-speech conversion, when the input is text or an estimated linguistic representation, and the target is synthesized speech. However, a research field that has risen in the last decade is articulation-to-speech synthesis (with a target application of a Silent Speech Interface, SSI), when the goal is to synthesize speech from some representation of the movement of the articulatory organs. In this paper, we extend traditional (vocoder-based) DNN-TTS with articulatory input, estimated from ultrasound tongue images. We compare text-only, ultrasound-only, and combined inputs. Using data from eight speakers, we show that that the combined text and articulatory input can have advantages in limited-data scenarios, namely, it may increase the naturalness of synthesized speech compared to single text input. Besides, we analyze the ultrasound tongue recordings of several speakers, and show that misalignments in the ultrasound transducer positioning can have a negative effect on the final synthesis performance.
Improving Neural Silent Speech Interface Models by Adversarial Training
Apr 23, 2021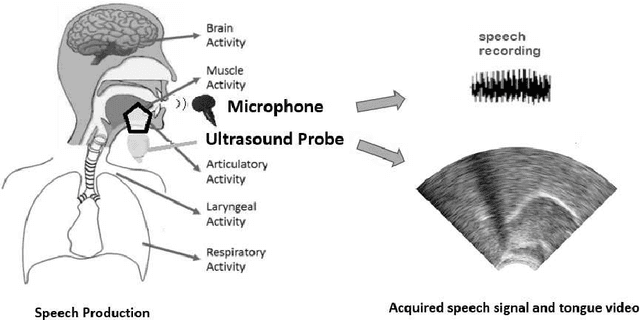
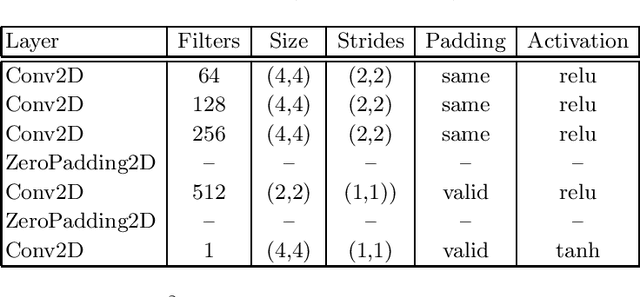
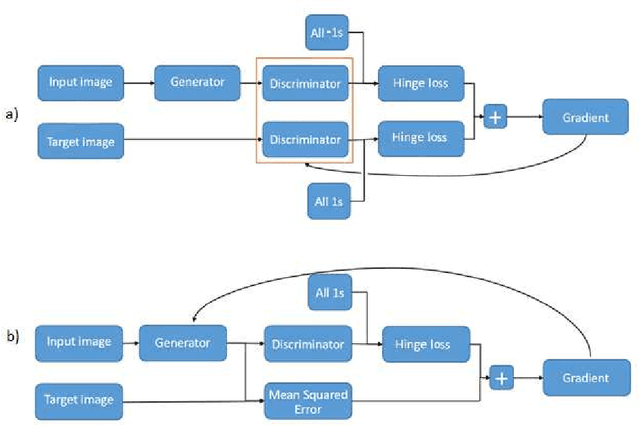

Besides the well-known classification task, these days neural networks are frequently being applied to generate or transform data, such as images and audio signals. In such tasks, the conventional loss functions like the mean squared error (MSE) may not give satisfactory results. To improve the perceptual quality of the generated signals, one possibility is to increase their similarity to real signals, where the similarity is evaluated via a discriminator network. The combination of the generator and discriminator nets is called a Generative Adversarial Network (GAN). Here, we evaluate this adversarial training framework in the articulatory-to-acoustic mapping task, where the goal is to reconstruct the speech signal from a recording of the movement of articulatory organs. As the generator, we apply a 3D convolutional network that gave us good results in an earlier study. To turn it into a GAN, we extend the conventional MSE training loss with an adversarial loss component provided by a discriminator network. As for the evaluation, we report various objective speech quality metrics such as the Perceptual Evaluation of Speech Quality (PESQ), and the Mel-Cepstral Distortion (MCD). Our results indicate that the application of the adversarial training loss brings about a slight, but consistent improvement in all these metrics.
Applying Speech Tempo-Derived Features, BoAW and Fisher Vectors to Detect Elderly Emotion and Speech in Surgical Masks
Aug 07, 2020
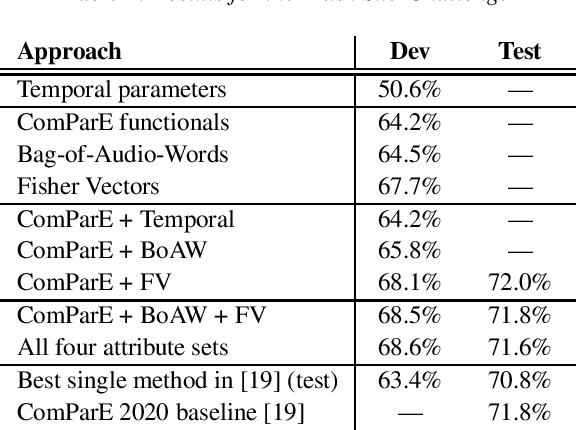
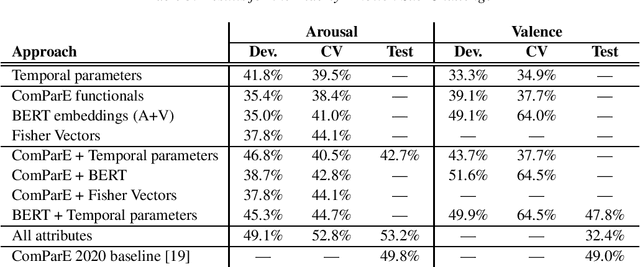
The 2020 INTERSPEECH Computational Paralinguistics Challenge (ComParE) consists of three Sub-Challenges, where the tasks are to identify the level of arousal and valence of elderly speakers, determine whether the actual speaker wearing a surgical mask, and estimate the actual breathing of the speaker. In our contribution to the Challenge, we focus on the Elderly Emotion and the Mask sub-challenges. Besides utilizing standard or close-to-standard features such as ComParE functionals, Bag-of-Audio-Words and Fisher vectors, we exploit that emotion is related to the velocity of speech (i.e. speech rate). To utilize this, we perform phone-level recognition using an ASR system, and extract features from the output such as articulation tempo, speech tempo, and various attributes measuring the amount of pauses. We also hypothesize that wearing a surgical mask makes the speaker feel uneasy, leading to a slower speech rate and more hesitations; hence, we experiment with the same features in the Mask sub-challenge as well. Although this theory was not justified by the experimental results on the Mask Sub-Challenge, in the Elderly Emotion Sub-Challenge we got significantly improved arousal and valence values with this feature type both on the development set and in cross-validation.
GMM-Free Flat Start Sequence-Discriminative DNN Training
Oct 11, 2016


Recently, attempts have been made to remove Gaussian mixture models (GMM) from the training process of deep neural network-based hidden Markov models (HMM/DNN). For the GMM-free training of a HMM/DNN hybrid we have to solve two problems, namely the initial alignment of the frame-level state labels and the creation of context-dependent states. Although flat-start training via iteratively realigning and retraining the DNN using a frame-level error function is viable, it is quite cumbersome. Here, we propose to use a sequence-discriminative training criterion for flat start. While sequence-discriminative training is routinely applied only in the final phase of model training, we show that with proper caution it is also suitable for getting an alignment of context-independent DNN models. For the construction of tied states we apply a recently proposed KL-divergence-based state clustering method, hence our whole training process is GMM-free. In the experimental evaluation we found that the sequence-discriminative flat start training method is not only significantly faster than the straightforward approach of iterative retraining and realignment, but the word error rates attained are slightly better as well.