 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain-to-Speech: Prosody Feature Engineering and Transformer-Based Reconstruction
Apr 07, 2026This chapter presents a novel approach to brain-to-speech (BTS) synthesis from intracranial electroencephalography (iEEG) data, emphasizing prosody-aware feature engineering and advanced transformer-based models for high-fidelity speech reconstruction. Driven by the increasing interest in decoding speech directly from brain activity, this work integrates neuroscience, artificial intelligence, and signal processing to generate accurate and natural speech. We introduce a novel pipeline for extracting key prosodic features directly from complex brain iEEG signals, including intonation, pitch, and rhythm. To effectively utilize these crucial features for natural-sounding speech, we employ advanced deep learning models. Furthermore, this chapter introduces a novel transformer encoder architecture specifically designed for brain-to-speech tasks. Unlike conventional models, our architecture integrates the extracted prosodic features to significantly enhance speech reconstruction, resulting in generated speech with improved intelligibility and expressiveness. A detailed evaluation demonstrates superior performance over established baseline methods, such as traditional Griffin-Lim and CNN-based reconstruction, across both quantitative and perceptual metrics. By demonstrating these advancements in feature extraction and transformer-based learning, this chapter contributes to the growing field of AI-driven neuroprosthetics, paving the way for assistive technologies that restore communication for individuals with speech impairments. Finally, we discuss promising future research directions, including the integration of diffusion models and real-time inference systems.
Prosody-Guided Harmonic Attention for Phase-Coherent Neural Vocoding in the Complex Spectrum
Jan 20, 2026Neural vocoders are central to speech synthesis; despite their success, most still suffer from limited prosody modeling and inaccurate phase reconstruction. We propose a vocoder that introduces prosody-guided harmonic attention to enhance voiced segment encoding and directly predicts complex spectral components for waveform synthesis via inverse STFT. Unlike mel-spectrogram-based approaches, our design jointly models magnitude and phase, ensuring phase coherence and improved pitch fidelity. To further align with perceptual quality, we adopt a multi-objective training strategy that integrates adversarial, spectral, and phase-aware losses. Experiments on benchmark datasets demonstrate consistent gains over HiFi-GAN and AutoVocoder: F0 RMSE reduced by 22 percent, voiced/unvoiced error lowered by 18 percent, and MOS scores improved by 0.15. These results show that prosody-guided attention combined with direct complex spectrum modeling yields more natural, pitch-accurate, and robust synthetic speech, setting a strong foundation for expressive neural vocoding.
Towards Parametric Speech Synthesis Using Gaussian-Markov Model of Spectral Envelope and Wavelet-Based Decomposition of F0
Aug 15, 2022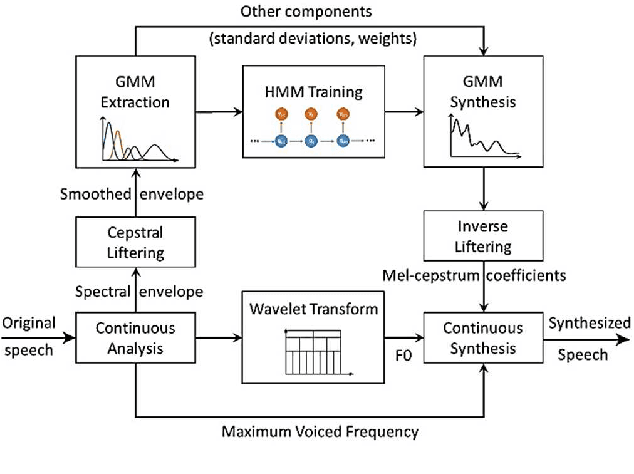

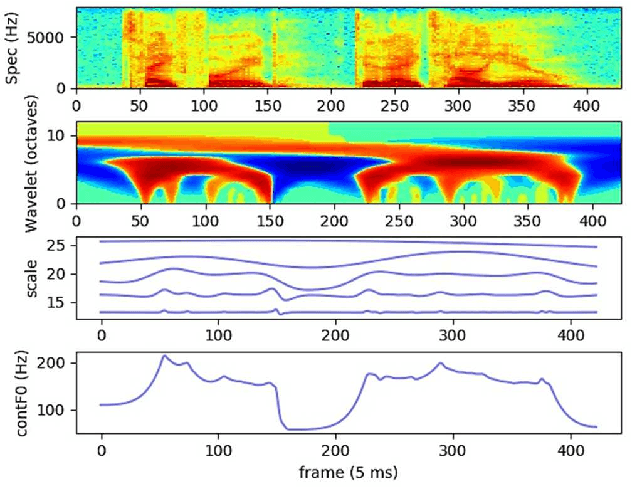
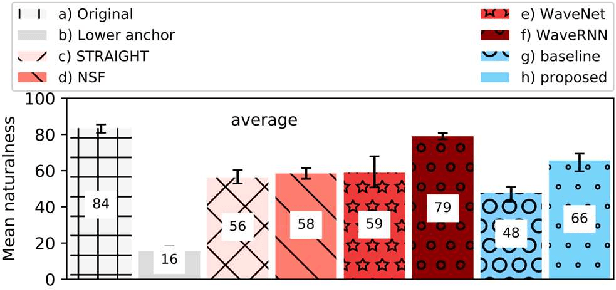
Neural network-based Text-to-Speech has significantly improved the quality of synthesized speech. Prominent methods (e.g., Tacotron2, FastSpeech, FastPitch) usually generate Mel-spectrogram from text and then synthesize speech using vocoder (e.g., WaveNet, WaveGlow, HiFiGAN). Compared with traditional parametric approaches (e.g., STRAIGHT and WORLD), neural vocoder based end-to-end models suffer from slow inference speed, and the synthesized speech is usually not robust and lack of controllability. In this work, we propose a novel updated vocoder, which is a simple signal model to train and easy to generate waveforms. We use the Gaussian-Markov model toward robust learning of spectral envelope and wavelet-based statistical signal processing to characterize and decompose F0 features. It can retain the fine spectral envelope and achieve high controllability of natural speech. The experimental results demonstrate that our proposed vocoder achieves better naturalness of reconstructed speech than the conventional STRAIGHT vocoder, slightly better than WaveNet, and somewhat worse than the WaveRNN.
Adaptation of Tacotron2-based Text-To-Speech for Articulatory-to-Acoustic Mapping using Ultrasound Tongue Imaging
Jul 26, 2021
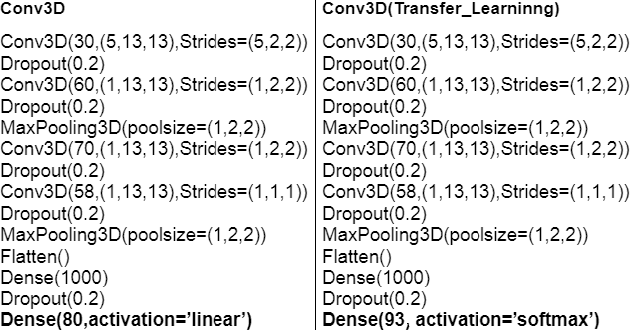
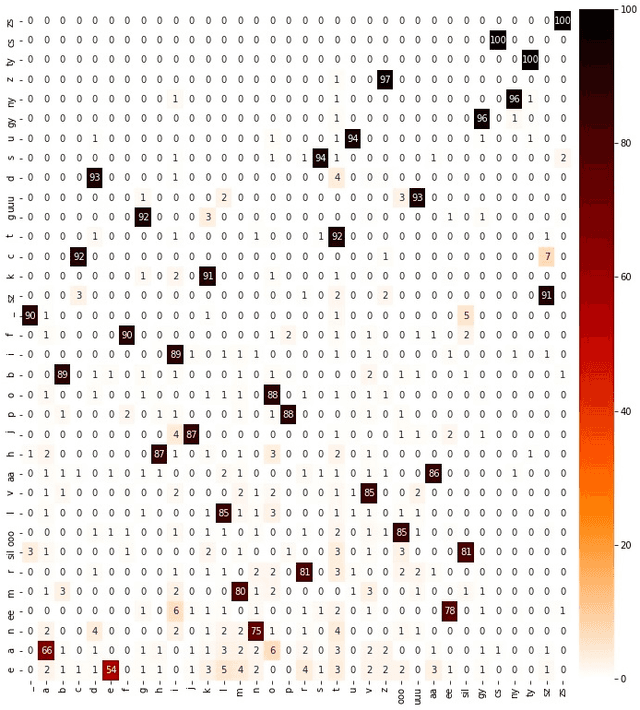
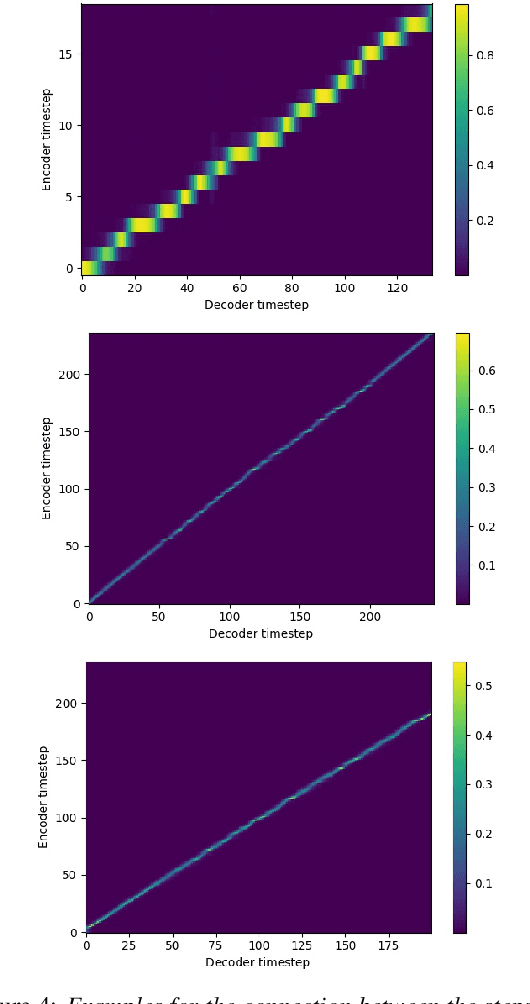
For articulatory-to-acoustic mapping, typically only limited parallel training data is available, making it impossible to apply fully end-to-end solutions like Tacotron2. In this paper, we experimented with transfer learning and adaptation of a Tacotron2 text-to-speech model to improve the final synthesis quality of ultrasound-based articulatory-to-acoustic mapping with a limited database. We use a multi-speaker pre-trained Tacotron2 TTS model and a pre-trained WaveGlow neural vocoder. The articulatory-to-acoustic conversion contains three steps: 1) from a sequence of ultrasound tongue image recordings, a 3D convolutional neural network predicts the inputs of the pre-trained Tacotron2 model, 2) the Tacotron2 model converts this intermediate representation to an 80-dimensional mel-spectrogram, and 3) the WaveGlow model is applied for final inference. This generated speech contains the timing of the original articulatory data from the ultrasound recording, but the F0 contour and the spectral information is predicted by the Tacotron2 model. The F0 values are independent of the original ultrasound images, but represent the target speaker, as they are inferred from the pre-trained Tacotron2 model. In our experiments, we demonstrated that the synthesized speech quality is more natural with the proposed solutions than with our earlier model.
Advances in Speech Vocoding for Text-to-Speech with Continuous Parameters
Jun 19, 2021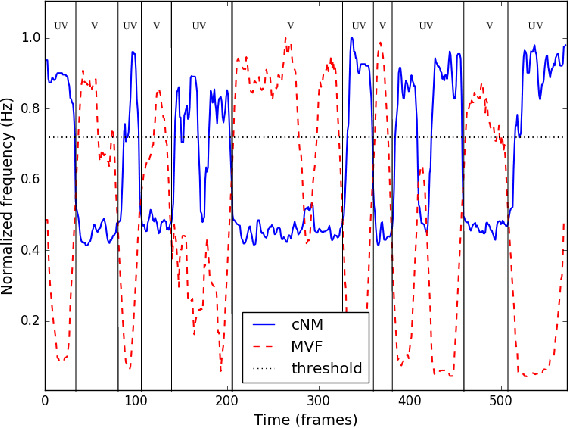
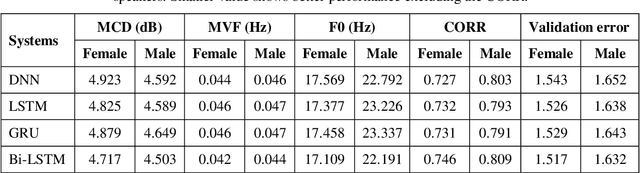
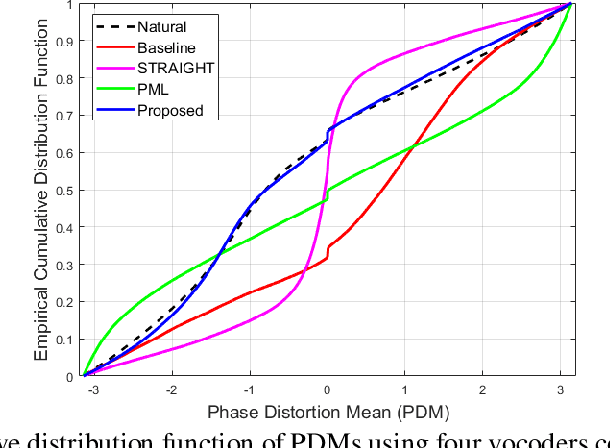
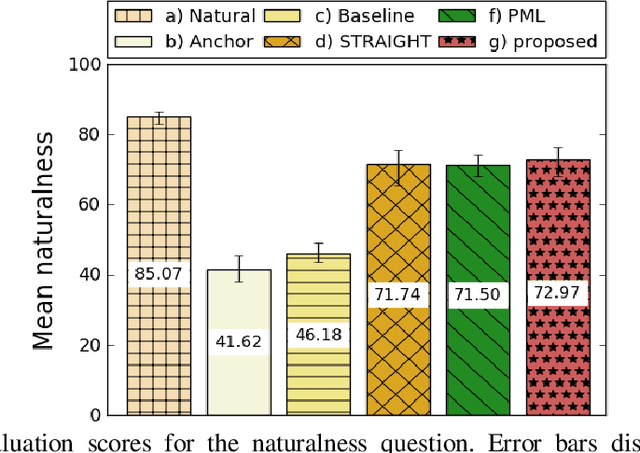
Vocoders received renewed attention as main components in statistical parametric text-to-speech (TTS) synthesis and speech transformation systems. Even though there are vocoding techniques give almost accepted synthesized speech, their high computational complexity and irregular structures are still considered challenging concerns, which yield a variety of voice quality degradation. Therefore, this paper presents new techniques in a continuous vocoder, that is all features are continuous and presents a flexible speech synthesis system. First, a new continuous noise masking based on the phase distortion is proposed to eliminate the perceptual impact of the residual noise and letting an accurate reconstruction of noise characteristics. Second, we addressed the need of neural sequence to sequence modeling approach for the task of TTS based on recurrent networks. Bidirectional long short-term memory (LSTM) and gated recurrent unit (GRU) are studied and applied to model continuous parameters for more natural-sounding like a human. The evaluation results proved that the proposed model achieves the state-of-the-art performance of the speech synthesis compared with the other traditional methods.
Continuous Wavelet Vocoder-based Decomposition of Parametric Speech Waveform Synthesis
Jun 12, 2021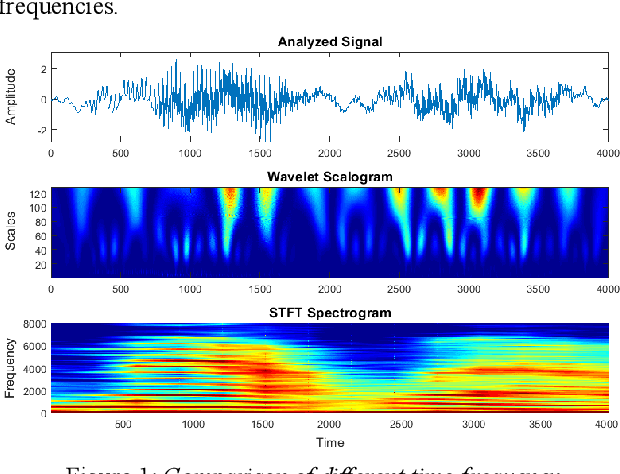
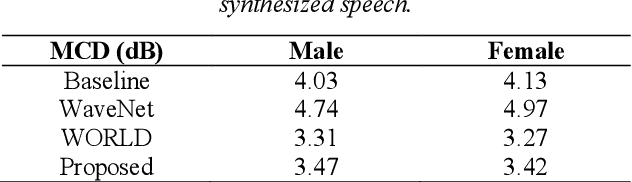
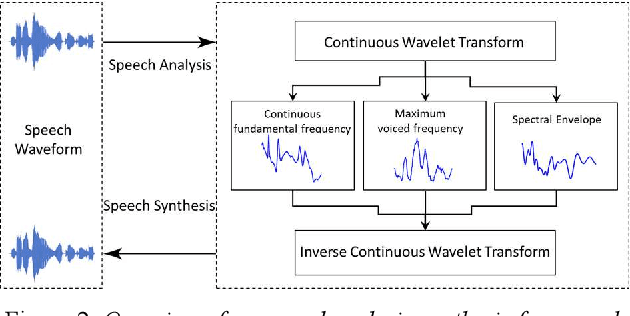

To date, various speech technology systems have adopted the vocoder approach, a method for synthesizing speech waveform that shows a major role in the performance of statistical parametric speech synthesis. WaveNet one of the best models that nearly resembles the human voice, has to generate a waveform in a time consuming sequential manner with an extremely complex structure of its neural networks.
Self-Attention Networks for Intent Detection
Jun 28, 2020
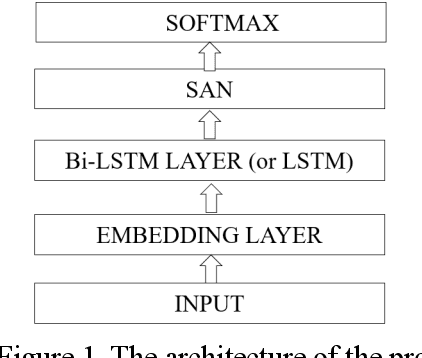
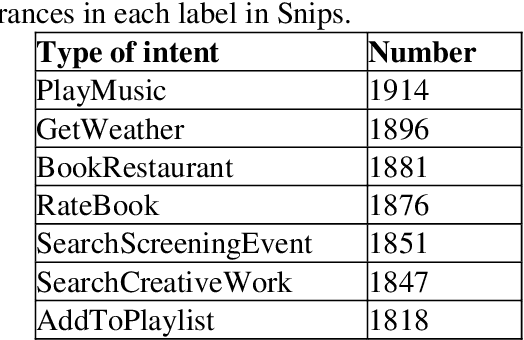
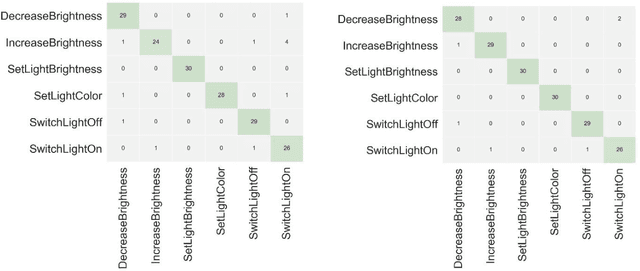
Self-attention networks (SAN) have shown promising performance in various Natural Language Processing (NLP) scenarios, especially in machine translation. One of the main points of SANs is the strength of capturing long-range and multi-scale dependencies from the data. In this paper, we present a novel intent detection system which is based on a self-attention network and a Bi-LSTM. Our approach shows improvement by using a transformer model and deep averaging network-based universal sentence encoder compared to previous solutions. We evaluate the system on Snips, Smart Speaker, Smart Lights, and ATIS datasets by different evaluation metrics. The performance of the proposed model is compared with LSTM with the same datasets.
Transformer based Grapheme-to-Phoneme Conversion
Apr 14, 2020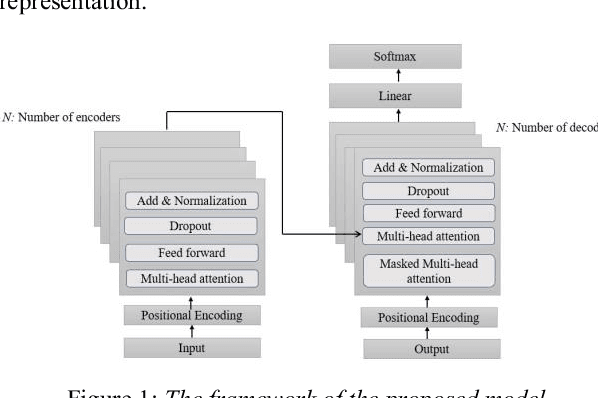
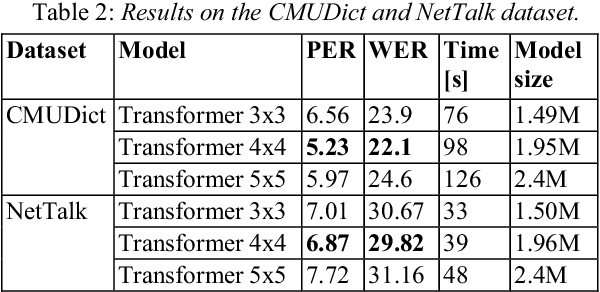

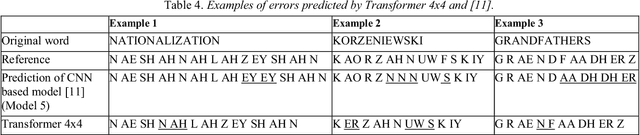
Attention mechanism is one of the most successful techniques in deep learning based Natural Language Processing (NLP). The transformer network architecture is completely based on attention mechanisms, and it outperforms sequence-to-sequence models in neural machine translation without recurrent and convolutional layers. Grapheme-to-phoneme (G2P) conversion is a task of converting letters (grapheme sequence) to their pronunciations (phoneme sequence). It plays a significant role in text-to-speech (TTS) and automatic speech recognition (ASR) systems. In this paper, we investigate the application of transformer architecture to G2P conversion and compare its performance with recurrent and convolutional neural network based approaches. Phoneme and word error rates are evaluated on the CMUDict dataset for US English and the NetTalk dataset. The results show that transformer based G2P outperforms the convolutional-based approach in terms of word error rate and our results significantly exceeded previous recurrent approaches (without attention) regarding word and phoneme error rates on both datasets. Furthermore, the size of the proposed model is much smaller than the size of the previous approaches.