 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Attention Networks for Intent Detection
Jun 28, 2020
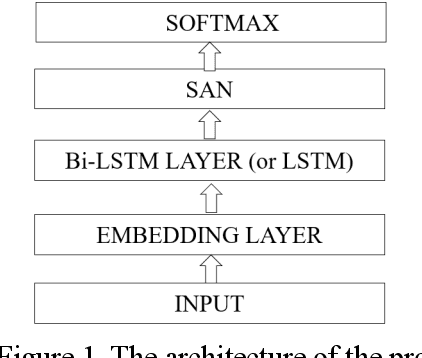
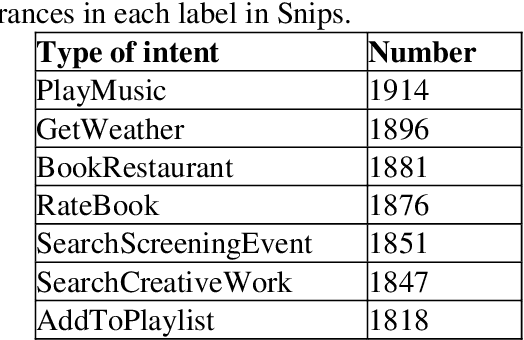
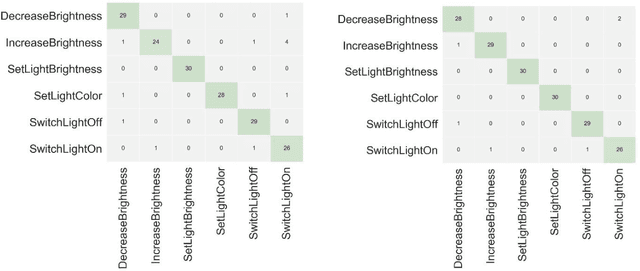
Self-attention networks (SAN) have shown promising performance in various Natural Language Processing (NLP) scenarios, especially in machine translation. One of the main points of SANs is the strength of capturing long-range and multi-scale dependencies from the data. In this paper, we present a novel intent detection system which is based on a self-attention network and a Bi-LSTM. Our approach shows improvement by using a transformer model and deep averaging network-based universal sentence encoder compared to previous solutions. We evaluate the system on Snips, Smart Speaker, Smart Lights, and ATIS datasets by different evaluation metrics. The performance of the proposed model is compared with LSTM with the same datasets.
Transformer based Grapheme-to-Phoneme Conversion
Apr 14, 2020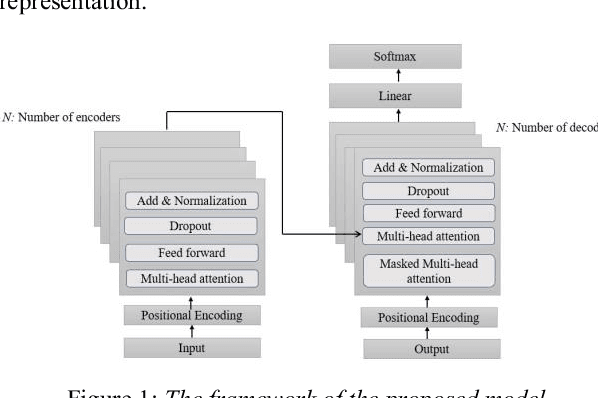
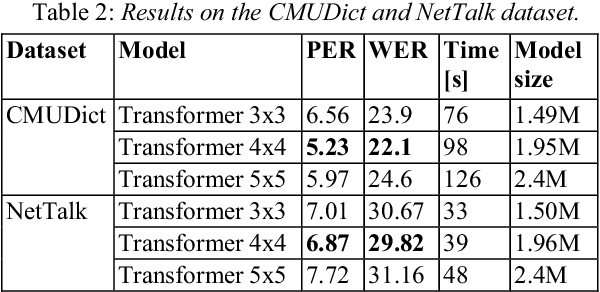

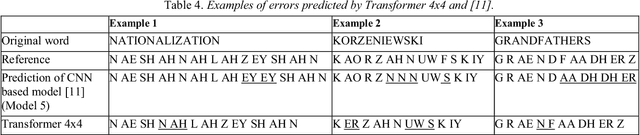
Attention mechanism is one of the most successful techniques in deep learning based Natural Language Processing (NLP). The transformer network architecture is completely based on attention mechanisms, and it outperforms sequence-to-sequence models in neural machine translation without recurrent and convolutional layers. Grapheme-to-phoneme (G2P) conversion is a task of converting letters (grapheme sequence) to their pronunciations (phoneme sequence). It plays a significant role in text-to-speech (TTS) and automatic speech recognition (ASR) systems. In this paper, we investigate the application of transformer architecture to G2P conversion and compare its performance with recurrent and convolutional neural network based approaches. Phoneme and word error rates are evaluated on the CMUDict dataset for US English and the NetTalk dataset. The results show that transformer based G2P outperforms the convolutional-based approach in terms of word error rate and our results significantly exceeded previous recurrent approaches (without attention) regarding word and phoneme error rates on both datasets. Furthermore, the size of the proposed model is much smaller than the size of the previous approaches.