 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNN-JEPA: Self-Supervised Pretraining Convolutional Neural Networks Using Joint Embedding Predictive Architecture
Aug 14, 2024



Self-supervised learning (SSL) has become an important approach in pretraining large neural networks, enabling unprecedented scaling of model and dataset sizes. While recent advances like I-JEPA have shown promising results for Vision Transformers, adapting such methods to Convolutional Neural Networks (CNNs) presents unique challenges. In this paper, we introduce CNN-JEPA, a novel SSL method that successfully applies the joint embedding predictive architecture approach to CNNs. Our method incorporates a sparse CNN encoder to handle masked inputs, a fully convolutional predictor using depthwise separable convolutions, and an improved masking strategy. We demonstrate that CNN-JEPA outperforms I-JEPA with ViT architectures on ImageNet-100, achieving 73.3% linear top-1 accuracy with a standard ResNet-50 encoder. Compared to other CNN-based SSL methods, CNN-JEPA requires 17-35% less training time for the same number of epochs and approaches the linear and k-NN top-1 accuracies of BYOL, SimCLR, and VICReg. Our approach offers a simpler, more efficient alternative to existing SSL methods for CNNs, requiring minimal augmentations and no separate projector network.
Whitening Consistently Improves Self-Supervised Learning
Aug 14, 2024



Self-supervised learning (SSL) has been shown to be a powerful approach for learning visual representations. In this study, we propose incorporating ZCA whitening as the final layer of the encoder in self-supervised learning to enhance the quality of learned features by normalizing and decorrelating them. Although whitening has been utilized in SSL in previous works, its potential to universally improve any SSL model has not been explored. We demonstrate that adding whitening as the last layer of SSL pretrained encoders is independent of the self-supervised learning method and encoder architecture, thus it improves performance for a wide range of SSL methods across multiple encoder architectures and datasets. Our experiments show that whitening is capable of improving linear and k-NN probing accuracy by 1-5%. Additionally, we propose metrics that allow for a comprehensive analysis of the learned features, provide insights into the quality of the representations and help identify collapse patterns.
Position control of an acoustic cavitation bubble by reinforcement learning
Dec 09, 2023



A control technique is developed via Reinforcement Learning that allows arbitrary controlling of the position of an acoustic cavitation bubble in a dual-frequency standing acoustic wave field. The agent must choose the optimal pressure amplitude values to manipulate the bubble position in the range of $x/\lambda_0\in[0.05, 0.25]$. To train the agent an actor-critic off-policy algorithm (Deep Deterministic Policy Gradient) was used that supports continuous action space, which allows setting the pressure amplitude values continuously within $0$ and $1\, \mathrm{bar}$. A shaped reward function is formulated that minimizes the distance between the bubble and the target position and implicitly encourages the agent to perform the position control within the shortest amount of time. In some cases, the optimal control can be 7 times faster than the solution expected from the linear theory.
Neurodevelopmental Phenotype Prediction: A State-of-the-Art Deep Learning Model
Nov 16, 2022A major challenge in medical image analysis is the automated detection of biomarkers from neuroimaging data. Traditional approaches, often based on image registration, are limited in capturing the high variability of cortical organisation across individuals. Deep learning methods have been shown to be successful in overcoming this difficulty, and some of them have even outperformed medical professionals on certain datasets. In this paper, we apply a deep neural network to analyse the cortical surface data of neonates, derived from the publicly available Developing Human Connectome Project (dHCP). Our goal is to identify neurodevelopmental biomarkers and to predict gestational age at birth based on these biomarkers. Using scans of preterm neonates acquired around the term-equivalent age, we were able to investigate the impact of preterm birth on cortical growth and maturation during late gestation. Besides reaching state-of-the-art prediction accuracy, the proposed model has much fewer parameters than the baselines, and its error stays low on both unregistered and registered cortical surfaces.
Utility of Equivariant Message Passing in Cortical Mesh Segmentation
Jun 15, 2022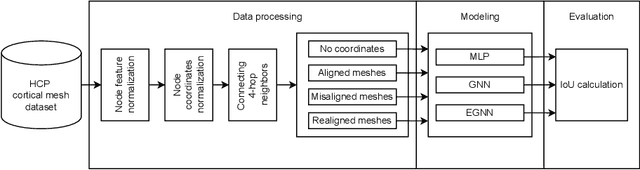
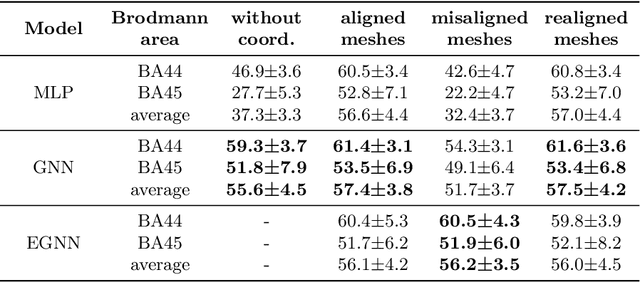
The automated segmentation of cortical areas has been a long-standing challenge in medical image analysis. The complex geometry of the cortex is commonly represented as a polygon mesh, whose segmentation can be addressed by graph-based learning methods. When cortical meshes are misaligned across subjects, current methods produce significantly worse segmentation results, limiting their ability to handle multi-domain data. In this paper, we investigate the utility of E(n)-equivariant graph neural networks (EGNNs), comparing their performance against plain graph neural networks (GNNs). Our evaluation shows that GNNs outperform EGNNs on aligned meshes, due to their ability to leverage the presence of a global coordinate system. On misaligned meshes, the performance of plain GNNs drop considerably, while E(n)-equivariant message passing maintains the same segmentation results. The best results can also be obtained by using plain GNNs on realigned data (co-registered meshes in a global coordinate system).
Improving Self-Supervised Learning-based MOS Prediction Networks
Apr 23, 2022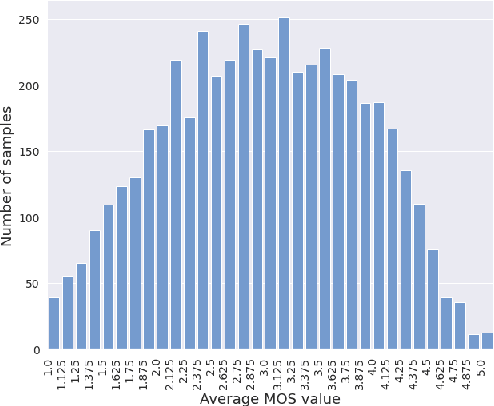
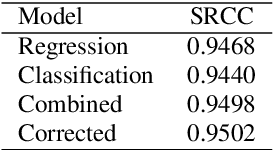
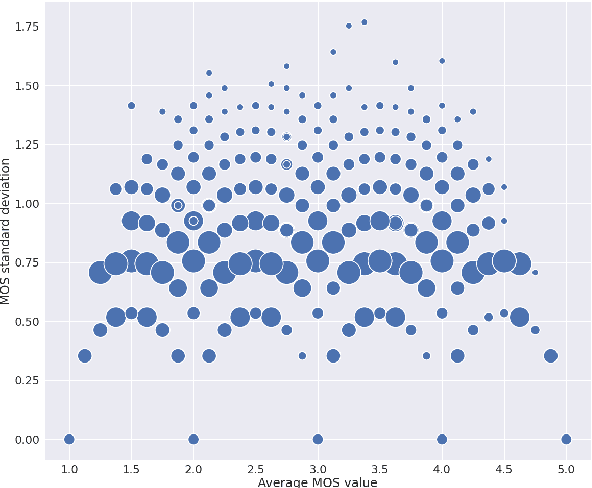
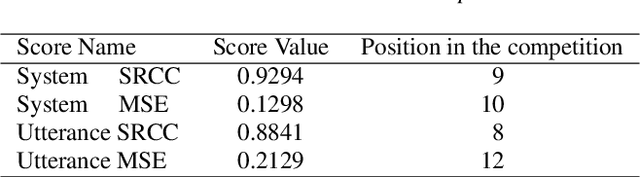
MOS (Mean Opinion Score) is a subjective method used for the evaluation of a system's quality. Telecommunications (for voice and video), and speech synthesis systems (for generated speech) are a few of the many applications of the method. While MOS tests are widely accepted, they are time-consuming and costly since human input is required. In addition, since the systems and subjects of the tests differ, the results are not really comparable. On the other hand, a large number of previous tests allow us to train machine learning models that are capable of predicting MOS value. By automatically predicting MOS values, both the aforementioned issues can be resolved. The present work introduces data-, training- and post-training specific improvements to a previous self-supervised learning-based MOS prediction model. We used a wav2vec 2.0 model pre-trained on LibriSpeech, extended with LSTM and non-linear dense layers. We introduced transfer learning, target data preprocessing a two- and three-phase training method with different batch formulations, dropout accumulation (for larger batch sizes) and quantization of the predictions. The methods are evaluated using the shared synthetic speech dataset of the first Voice MOS challenge.
Reconstructing nodal pressures in water distribution systems with graph neural networks
Apr 28, 2021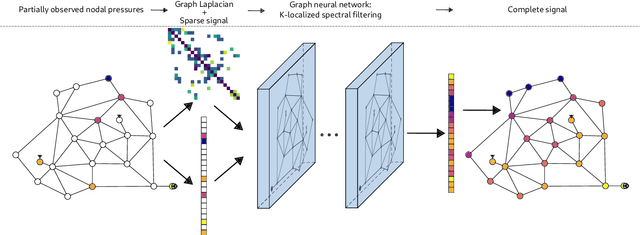
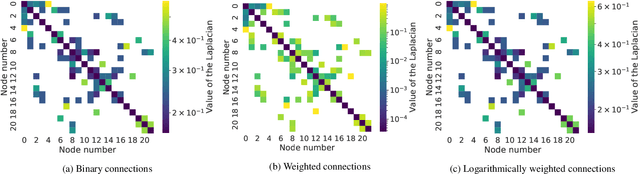

Knowing the pressure at all times in each node of a water distribution system (WDS) facilitates safe and efficient operation. Yet, complete measurement data cannot be collected due to the limited number of instruments in a real-life WDS. The data-driven methodology of reconstructing all the nodal pressures by observing only a limited number of nodes is presented in the paper. The reconstruction method is based on K-localized spectral graph filters, wherewith graph convolution on water networks is possible. The effect of the number of layers, layer depth and the degree of the Chebyshev-polynomial applied in the kernel is discussed taking into account the peculiarities of the application. In addition, a weighting method is shown, wherewith information on friction loss can be embed into the spectral graph filters through the adjacency matrix. The performance of the proposed model is presented on 3 WDSs at different number of nodes observed compared to the total number of nodes. The weighted connections prove no benefit over the binary connections, but the proposed model reconstructs the nodal pressure with at most 5% relative error on average at an observation ratio of 5% at least. The results are achieved with shallow graph neural networks by following the considerations discussed in the paper.
Deep Reinforcement Learning for Real-Time Optimization of Pumps in Water Distribution Systems
Oct 13, 2020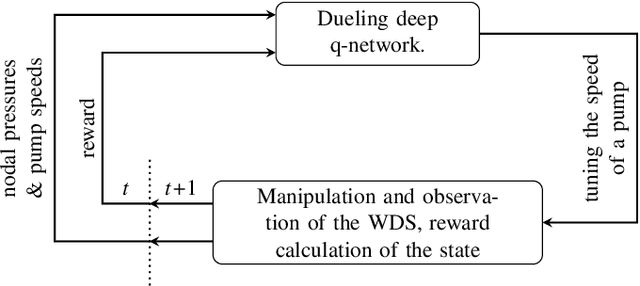

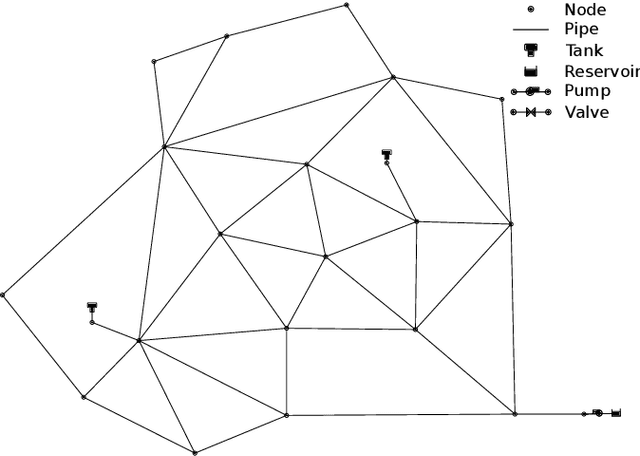

Real-time control of pumps can be an infeasible task in water distribution systems (WDSs) because the calculation to find the optimal pump speeds is resource-intensive. The computational need cannot be lowered even with the capabilities of smart water networks when conventional optimization techniques are used. Deep reinforcement learning (DRL) is presented here as a controller of pumps in two WDSs. An agent based on a dueling deep q-network is trained to maintain the pump speeds based on instantaneous nodal pressure data. General optimization techniques (e.g., Nelder-Mead method, differential evolution) serve as baselines. The total efficiency achieved by the DRL agent compared to the best performing baseline is above 0.98, whereas the speedup is around 2x compared to that. The main contribution of the presented approach is that the agent can run the pumps in real-time because it depends only on measurement data. If the WDS is replaced with a hydraulic simulation, the agent still outperforms conventional techniques in search speed.
Predicting the flow field in a U-bend with deep neural networks
Oct 01, 2020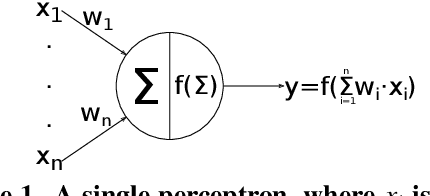
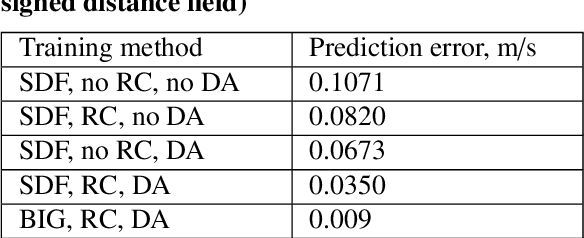
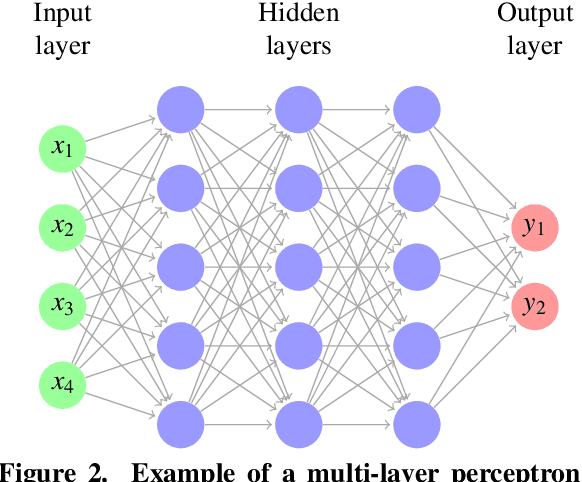
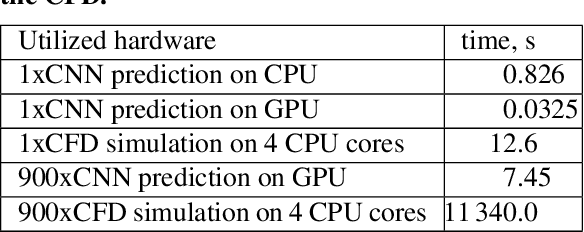
This paper describes a study based on computational fluid dynamics (CFD) and deep neural networks that focusing on predicting the flow field in differently distorted U-shaped pipes. The main motivation of this work was to get an insight about the justification of the deep learning paradigm in hydrodynamic hull optimisation processes that heavily depend on computing turbulent flow fields and that could be accelerated with models like the one presented. The speed-up can be even several orders of magnitude by surrogating the CFD model with a deep convolutional neural network. An automated geometry creation and evaluation process was set up to generate differently shaped two-dimensional U-bends and to carry out CFD simulation on them. This process resulted in a database with different geometries and the corresponding flow fields (2-dimensional velocity distribution), both represented on 128x128 equidistant grids. This database was used to train an encoder-decoder style deep convolutional neural network to predict the velocity distribution from the geometry. The effect of two different representations of the geometry (binary image and signed distance function) on the predictions was examined, both models gave acceptable predictions with a speed-up of two orders of magnitude.
* Conference paper, 8 pages, 10 figures
Robust Reinforcement Learning-based Autonomous Driving Agent for Simulation and Real World
Sep 23, 2020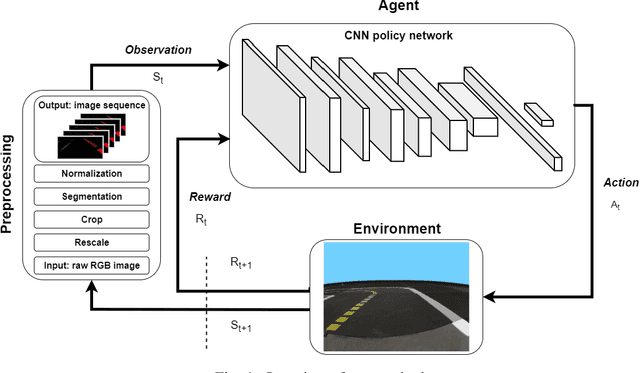

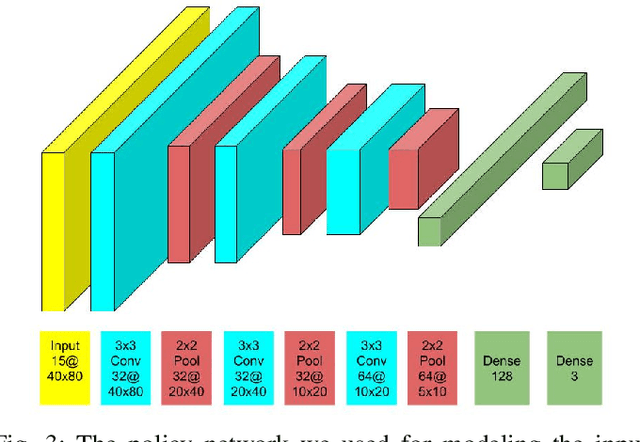

Deep Reinforcement Learning (DRL) has been successfully used to solve different challenges, e.g. complex board and computer games, recently. However, solving real-world robotics tasks with DRL seems to be a more difficult challenge. The desired approach would be to train the agent in a simulator and transfer it to the real world. Still, models trained in a simulator tend to perform poorly in real-world environments due to the differences. In this paper, we present a DRL-based algorithm that is capable of performing autonomous robot control using Deep Q-Networks (DQN). In our approach, the agent is trained in a simulated environment and it is able to navigate both in a simulated and real-world environment. The method is evaluated in the Duckietown environment, where the agent has to follow the lane based on a monocular camera input. The trained agent is able to run on limited hardware resources and its performance is comparable to state-of-the-art approaches.