 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Parametric Speech Synthesis Using Gaussian-Markov Model of Spectral Envelope and Wavelet-Based Decomposition of F0
Aug 15, 2022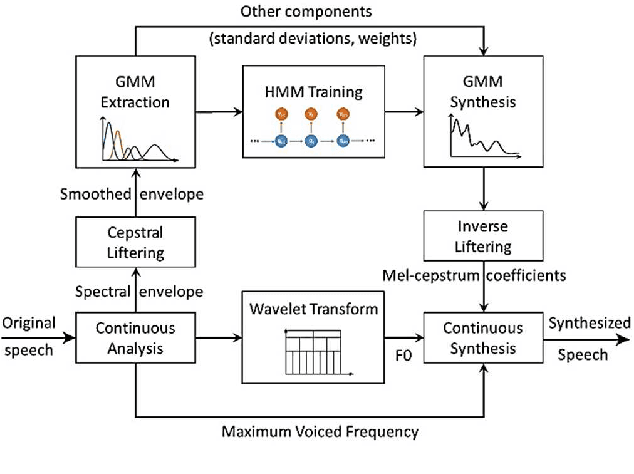

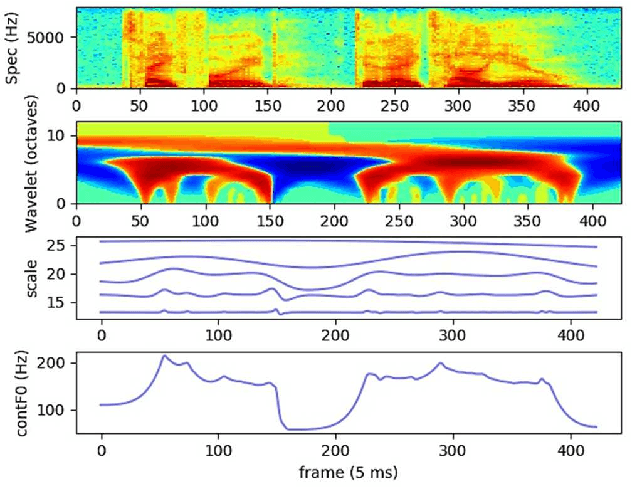
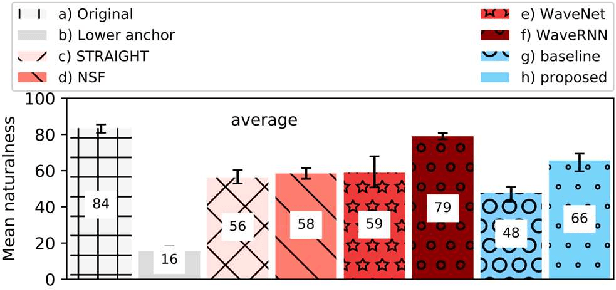
Neural network-based Text-to-Speech has significantly improved the quality of synthesized speech. Prominent methods (e.g., Tacotron2, FastSpeech, FastPitch) usually generate Mel-spectrogram from text and then synthesize speech using vocoder (e.g., WaveNet, WaveGlow, HiFiGAN). Compared with traditional parametric approaches (e.g., STRAIGHT and WORLD), neural vocoder based end-to-end models suffer from slow inference speed, and the synthesized speech is usually not robust and lack of controllability. In this work, we propose a novel updated vocoder, which is a simple signal model to train and easy to generate waveforms. We use the Gaussian-Markov model toward robust learning of spectral envelope and wavelet-based statistical signal processing to characterize and decompose F0 features. It can retain the fine spectral envelope and achieve high controllability of natural speech. The experimental results demonstrate that our proposed vocoder achieves better naturalness of reconstructed speech than the conventional STRAIGHT vocoder, slightly better than WaveNet, and somewhat worse than the WaveRNN.
Improving Self-Supervised Learning-based MOS Prediction Networks
Apr 23, 2022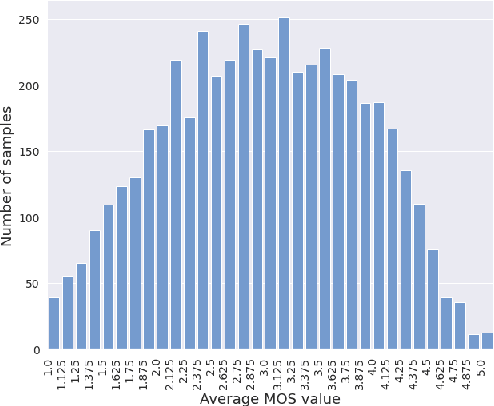
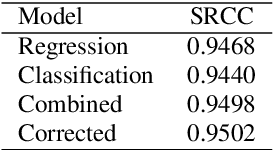
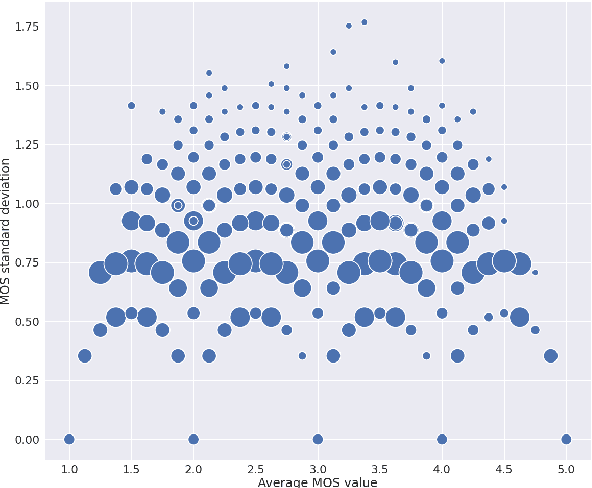
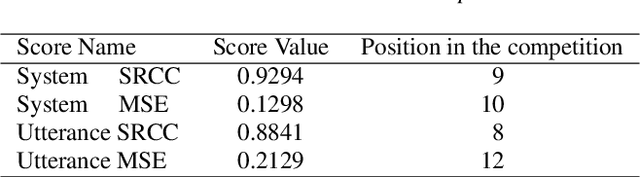
MOS (Mean Opinion Score) is a subjective method used for the evaluation of a system's quality. Telecommunications (for voice and video), and speech synthesis systems (for generated speech) are a few of the many applications of the method. While MOS tests are widely accepted, they are time-consuming and costly since human input is required. In addition, since the systems and subjects of the tests differ, the results are not really comparable. On the other hand, a large number of previous tests allow us to train machine learning models that are capable of predicting MOS value. By automatically predicting MOS values, both the aforementioned issues can be resolved. The present work introduces data-, training- and post-training specific improvements to a previous self-supervised learning-based MOS prediction model. We used a wav2vec 2.0 model pre-trained on LibriSpeech, extended with LSTM and non-linear dense layers. We introduced transfer learning, target data preprocessing a two- and three-phase training method with different batch formulations, dropout accumulation (for larger batch sizes) and quantization of the predictions. The methods are evaluated using the shared synthetic speech dataset of the first Voice MOS challenge.
Adaptation of Tacotron2-based Text-To-Speech for Articulatory-to-Acoustic Mapping using Ultrasound Tongue Imaging
Jul 26, 2021
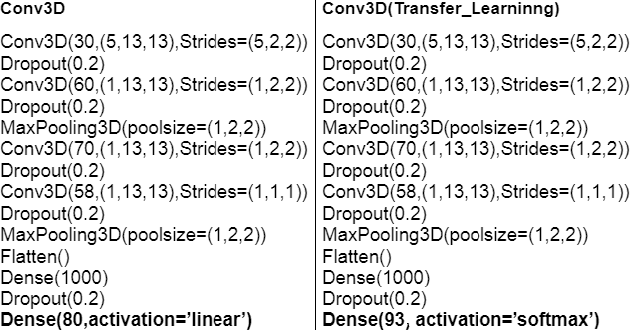
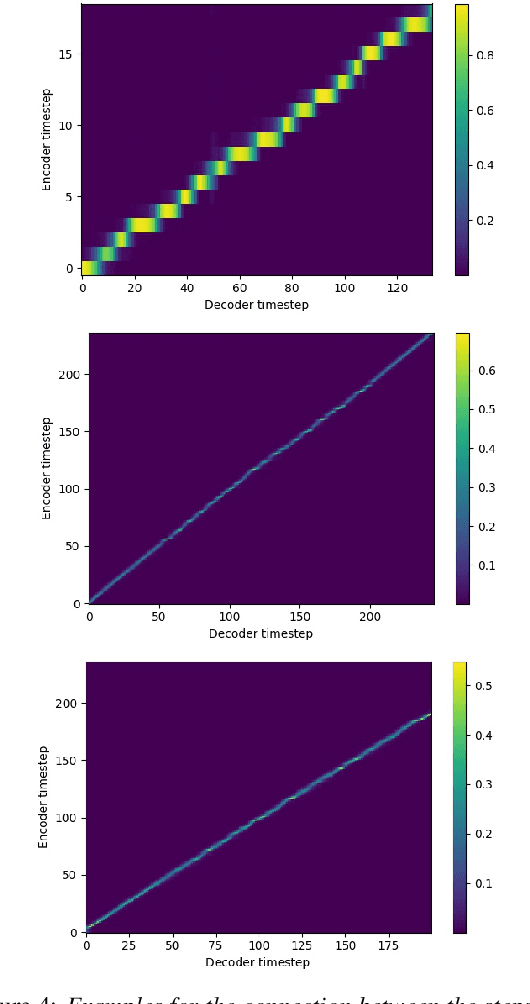
For articulatory-to-acoustic mapping, typically only limited parallel training data is available, making it impossible to apply fully end-to-end solutions like Tacotron2. In this paper, we experimented with transfer learning and adaptation of a Tacotron2 text-to-speech model to improve the final synthesis quality of ultrasound-based articulatory-to-acoustic mapping with a limited database. We use a multi-speaker pre-trained Tacotron2 TTS model and a pre-trained WaveGlow neural vocoder. The articulatory-to-acoustic conversion contains three steps: 1) from a sequence of ultrasound tongue image recordings, a 3D convolutional neural network predicts the inputs of the pre-trained Tacotron2 model, 2) the Tacotron2 model converts this intermediate representation to an 80-dimensional mel-spectrogram, and 3) the WaveGlow model is applied for final inference. This generated speech contains the timing of the original articulatory data from the ultrasound recording, but the F0 contour and the spectral information is predicted by the Tacotron2 model. The F0 values are independent of the original ultrasound images, but represent the target speaker, as they are inferred from the pre-trained Tacotron2 model. In our experiments, we demonstrated that the synthesized speech quality is more natural with the proposed solutions than with our earlier model.
Continuous Wavelet Vocoder-based Decomposition of Parametric Speech Waveform Synthesis
Jun 12, 2021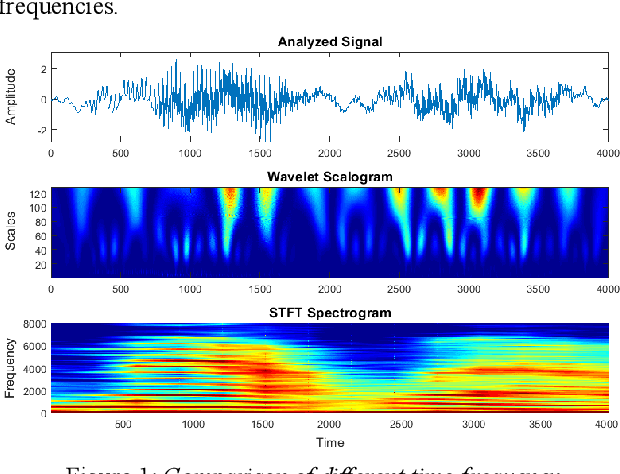
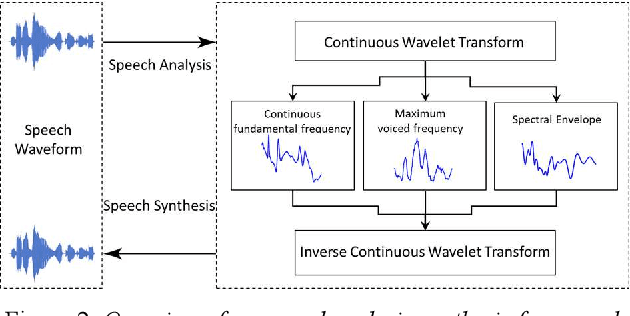

To date, various speech technology systems have adopted the vocoder approach, a method for synthesizing speech waveform that shows a major role in the performance of statistical parametric speech synthesis. WaveNet one of the best models that nearly resembles the human voice, has to generate a waveform in a time consuming sequential manner with an extremely complex structure of its neural networks.