 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProsody-Guided Harmonic Attention for Phase-Coherent Neural Vocoding in the Complex Spectrum
Jan 20, 2026Neural vocoders are central to speech synthesis; despite their success, most still suffer from limited prosody modeling and inaccurate phase reconstruction. We propose a vocoder that introduces prosody-guided harmonic attention to enhance voiced segment encoding and directly predicts complex spectral components for waveform synthesis via inverse STFT. Unlike mel-spectrogram-based approaches, our design jointly models magnitude and phase, ensuring phase coherence and improved pitch fidelity. To further align with perceptual quality, we adopt a multi-objective training strategy that integrates adversarial, spectral, and phase-aware losses. Experiments on benchmark datasets demonstrate consistent gains over HiFi-GAN and AutoVocoder: F0 RMSE reduced by 22 percent, voiced/unvoiced error lowered by 18 percent, and MOS scores improved by 0.15. These results show that prosody-guided attention combined with direct complex spectrum modeling yields more natural, pitch-accurate, and robust synthetic speech, setting a strong foundation for expressive neural vocoding.
Towards Parametric Speech Synthesis Using Gaussian-Markov Model of Spectral Envelope and Wavelet-Based Decomposition of F0
Aug 15, 2022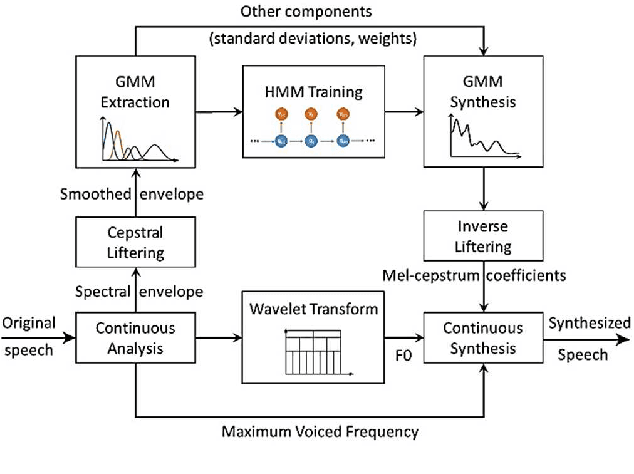

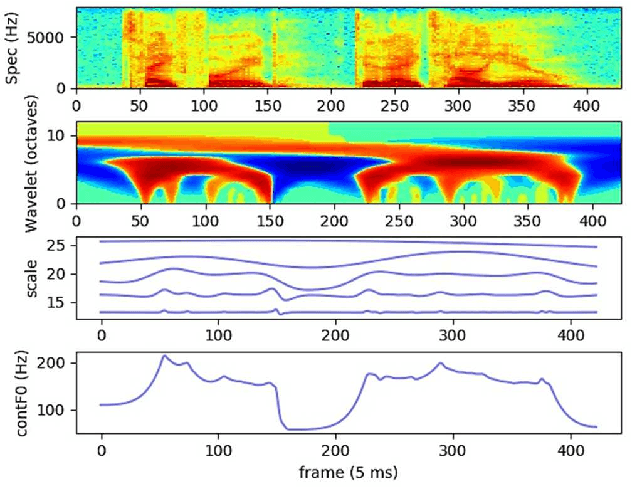
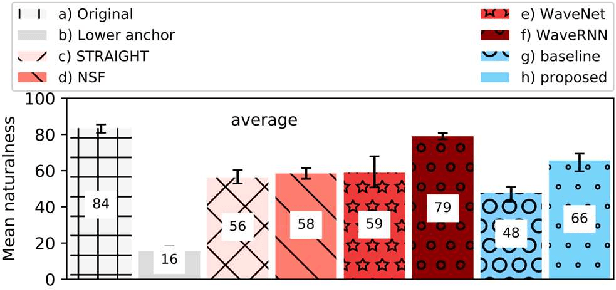
Neural network-based Text-to-Speech has significantly improved the quality of synthesized speech. Prominent methods (e.g., Tacotron2, FastSpeech, FastPitch) usually generate Mel-spectrogram from text and then synthesize speech using vocoder (e.g., WaveNet, WaveGlow, HiFiGAN). Compared with traditional parametric approaches (e.g., STRAIGHT and WORLD), neural vocoder based end-to-end models suffer from slow inference speed, and the synthesized speech is usually not robust and lack of controllability. In this work, we propose a novel updated vocoder, which is a simple signal model to train and easy to generate waveforms. We use the Gaussian-Markov model toward robust learning of spectral envelope and wavelet-based statistical signal processing to characterize and decompose F0 features. It can retain the fine spectral envelope and achieve high controllability of natural speech. The experimental results demonstrate that our proposed vocoder achieves better naturalness of reconstructed speech than the conventional STRAIGHT vocoder, slightly better than WaveNet, and somewhat worse than the WaveRNN.
Speaker Adaptation with Continuous Vocoder-based DNN-TTS
Aug 02, 2021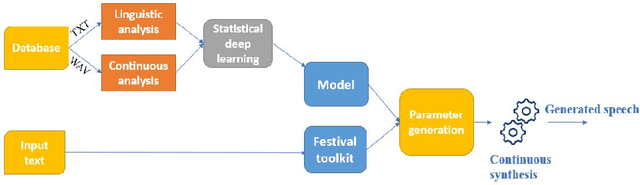
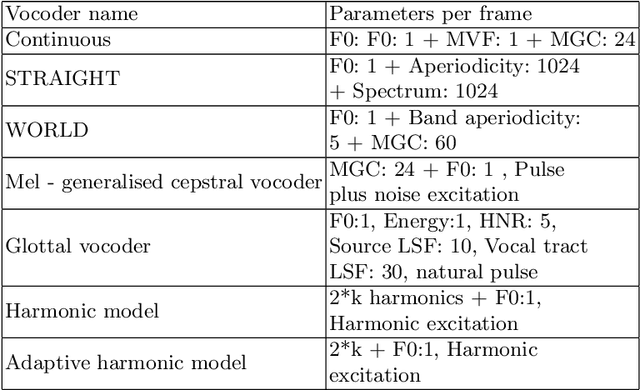
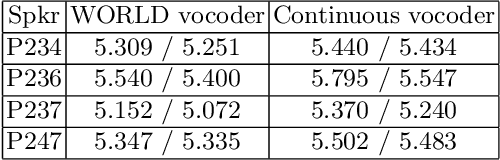

Traditional vocoder-based statistical parametric speech synthesis can be advantageous in applications that require low computational complexity. Recent neural vocoders, which can produce high naturalness, still cannot fulfill the requirement of being real-time during synthesis. In this paper, we experiment with our earlier continuous vocoder, in which the excitation is modeled with two one-dimensional parameters: continuous F0 and Maximum Voiced Frequency. We show on the data of 9 speakers that an average voice can be trained for DNN-TTS, and speaker adaptation is feasible 400 utterances (about 14 minutes). Objective experiments support that the quality of speaker adaptation with Continuous Vocoder-based DNN-TTS is similar to the quality of the speaker adaptation with a WORLD Vocoder-based baseline.
Advances in Speech Vocoding for Text-to-Speech with Continuous Parameters
Jun 19, 2021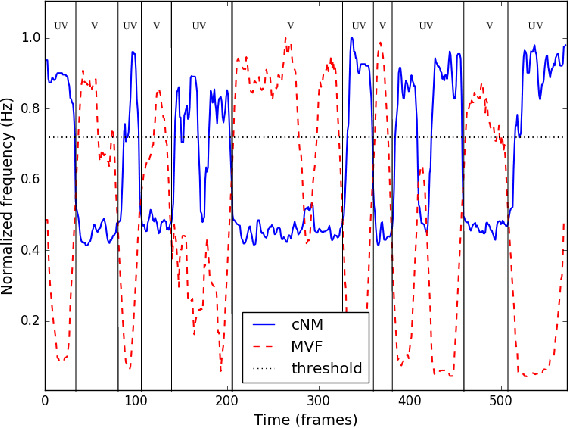
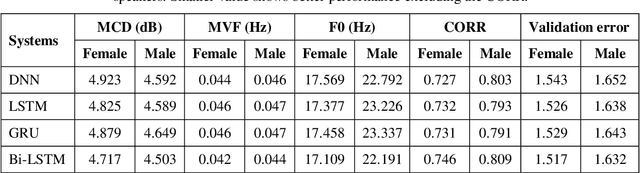
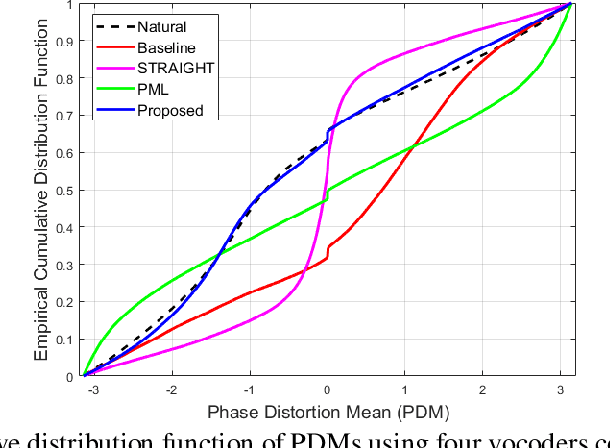
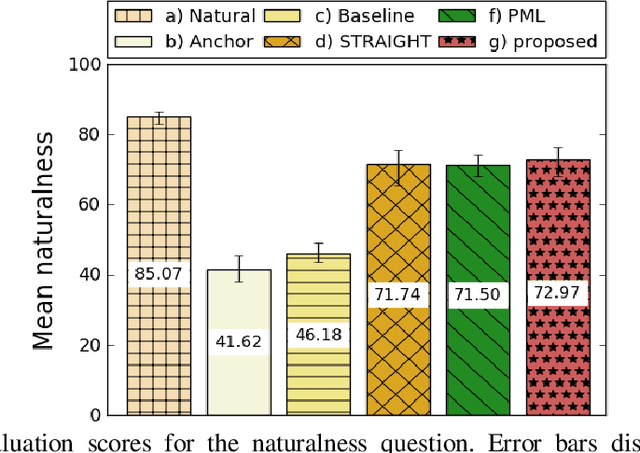
Vocoders received renewed attention as main components in statistical parametric text-to-speech (TTS) synthesis and speech transformation systems. Even though there are vocoding techniques give almost accepted synthesized speech, their high computational complexity and irregular structures are still considered challenging concerns, which yield a variety of voice quality degradation. Therefore, this paper presents new techniques in a continuous vocoder, that is all features are continuous and presents a flexible speech synthesis system. First, a new continuous noise masking based on the phase distortion is proposed to eliminate the perceptual impact of the residual noise and letting an accurate reconstruction of noise characteristics. Second, we addressed the need of neural sequence to sequence modeling approach for the task of TTS based on recurrent networks. Bidirectional long short-term memory (LSTM) and gated recurrent unit (GRU) are studied and applied to model continuous parameters for more natural-sounding like a human. The evaluation results proved that the proposed model achieves the state-of-the-art performance of the speech synthesis compared with the other traditional methods.
Continuous Wavelet Vocoder-based Decomposition of Parametric Speech Waveform Synthesis
Jun 12, 2021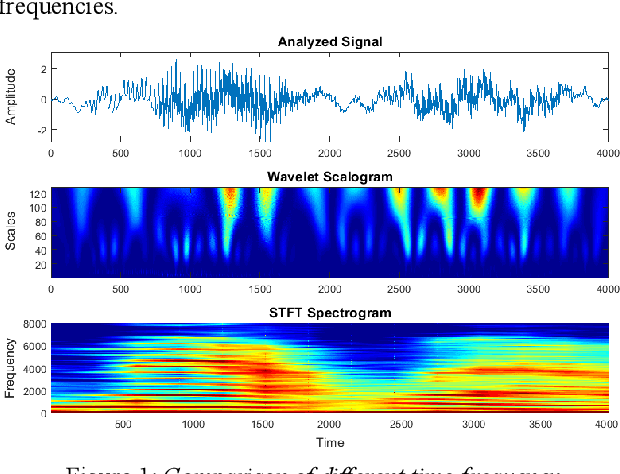
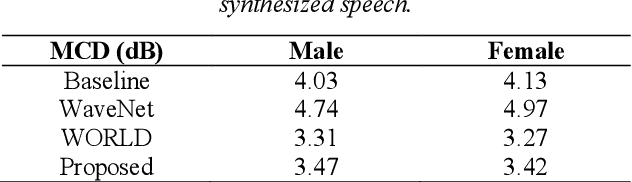
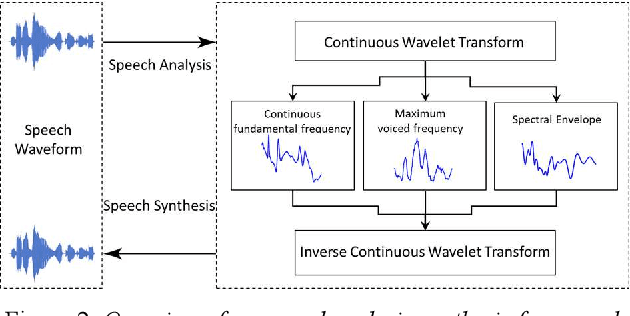

To date, various speech technology systems have adopted the vocoder approach, a method for synthesizing speech waveform that shows a major role in the performance of statistical parametric speech synthesis. WaveNet one of the best models that nearly resembles the human voice, has to generate a waveform in a time consuming sequential manner with an extremely complex structure of its neural networks.
High-Quality Vocoding Design with Signal Processing for Speech Synthesis and Voice Conversion
Jan 25, 2021

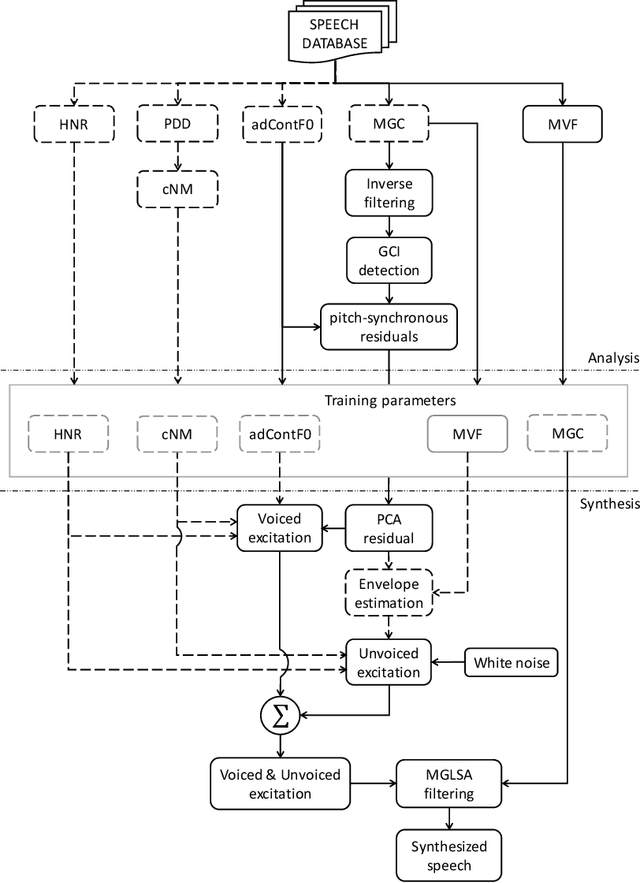

This Ph.D. thesis focuses on developing a system for high-quality speech synthesis and voice conversion. Vocoder-based speech analysis, manipulation, and synthesis plays a crucial role in various kinds of statistical parametric speech research. Although there are vocoding methods which yield close to natural synthesized speech, they are typically computationally expensive, and are thus not suitable for real-time implementation, especially in embedded environments. Therefore, there is a need for simple and computationally feasible digital signal processing algorithms for generating high-quality and natural-sounding synthesized speech. In this dissertation, I propose a solution to extract optimal acoustic features and a new waveform generator to achieve higher sound quality and conversion accuracy by applying advances in deep learning. The approach remains computationally efficient. This challenge resulted in five thesis groups, which are briefly summarized below.