 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Quality Vocoding Design with Signal Processing for Speech Synthesis and Voice Conversion
Paper and Code

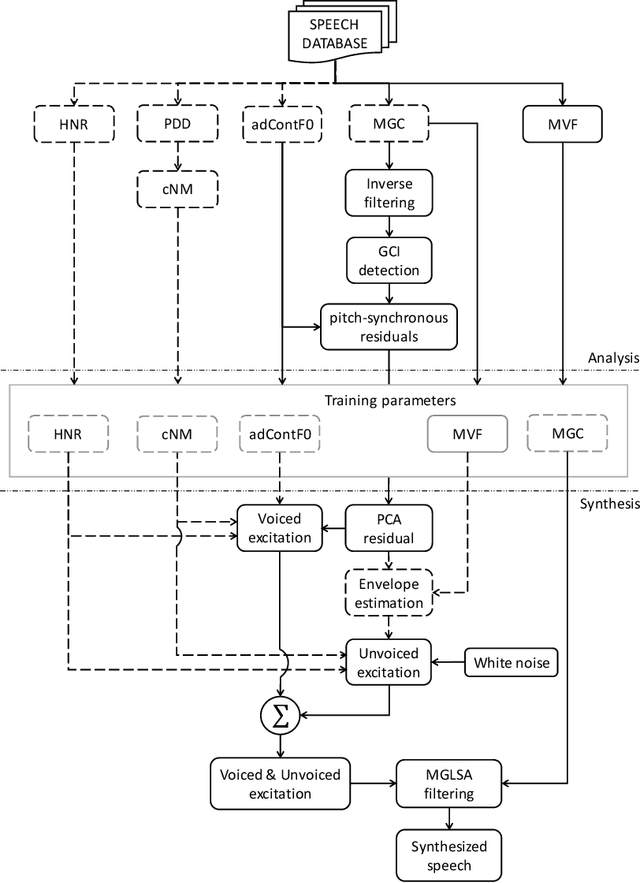

This Ph.D. thesis focuses on developing a system for high-quality speech synthesis and voice conversion. Vocoder-based speech analysis, manipulation, and synthesis plays a crucial role in various kinds of statistical parametric speech research. Although there are vocoding methods which yield close to natural synthesized speech, they are typically computationally expensive, and are thus not suitable for real-time implementation, especially in embedded environments. Therefore, there is a need for simple and computationally feasible digital signal processing algorithms for generating high-quality and natural-sounding synthesized speech. In this dissertation, I propose a solution to extract optimal acoustic features and a new waveform generator to achieve higher sound quality and conversion accuracy by applying advances in deep learning. The approach remains computationally efficient. This challenge resulted in five thesis groups, which are briefly summarized below.