 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Adaptation with Continuous Vocoder-based DNN-TTS
Aug 02, 2021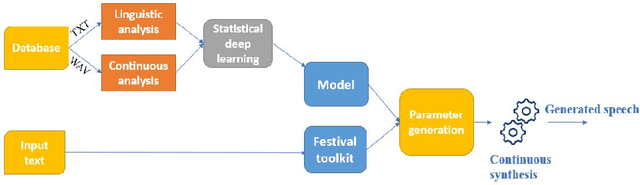
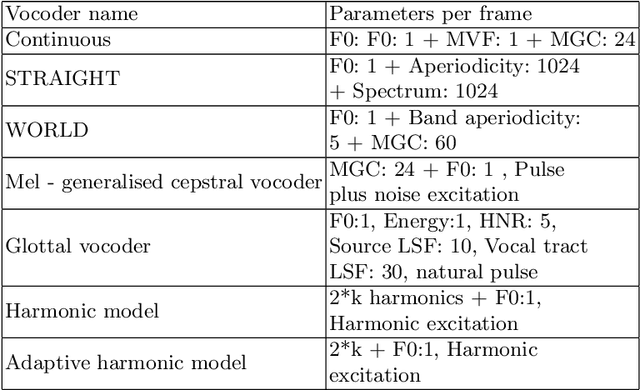
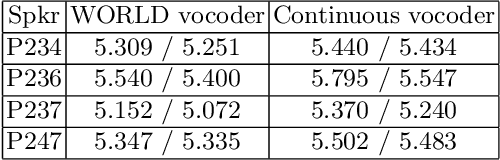

Traditional vocoder-based statistical parametric speech synthesis can be advantageous in applications that require low computational complexity. Recent neural vocoders, which can produce high naturalness, still cannot fulfill the requirement of being real-time during synthesis. In this paper, we experiment with our earlier continuous vocoder, in which the excitation is modeled with two one-dimensional parameters: continuous F0 and Maximum Voiced Frequency. We show on the data of 9 speakers that an average voice can be trained for DNN-TTS, and speaker adaptation is feasible 400 utterances (about 14 minutes). Objective experiments support that the quality of speaker adaptation with Continuous Vocoder-based DNN-TTS is similar to the quality of the speaker adaptation with a WORLD Vocoder-based baseline.