 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Decoding Brain Activity During Passive Listening of Speech
Feb 26, 2024The aim of the study is to investigate the complex mechanisms of speech perception and ultimately decode the electrical changes in the brain accruing while listening to speech. We attempt to decode heard speech from intracranial electroencephalographic (iEEG) data using deep learning methods. The goal is to aid the advancement of brain-computer interface (BCI) technology for speech synthesis, and, hopefully, to provide an additional perspective on the cognitive processes of speech perception. This approach diverges from the conventional focus on speech production and instead chooses to investigate neural representations of perceived speech. This angle opened up a complex perspective, potentially allowing us to study more sophisticated neural patterns. Leveraging the power of deep learning models, the research aimed to establish a connection between these intricate neural activities and the corresponding speech sounds. Despite the approach not having achieved a breakthrough yet, the research sheds light on the potential of decoding neural activity during speech perception. Our current efforts can serve as a foundation, and we are optimistic about the potential of expanding and improving upon this work to move closer towards more advanced BCIs, better understanding of processes underlying perceived speech and its relation to spoken speech.
Towards Parametric Speech Synthesis Using Gaussian-Markov Model of Spectral Envelope and Wavelet-Based Decomposition of F0
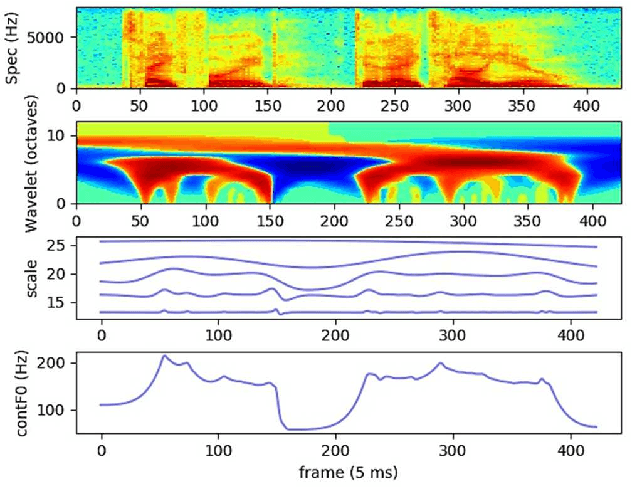
Aug 15, 2022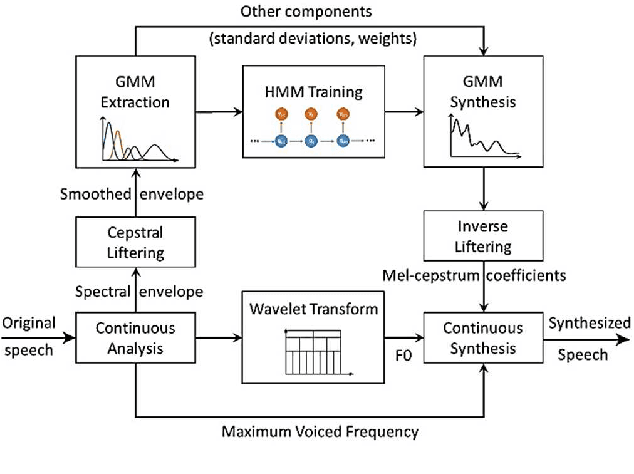

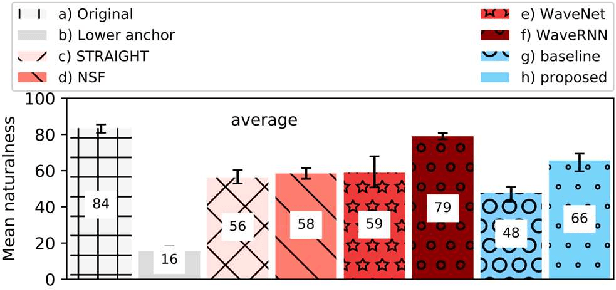
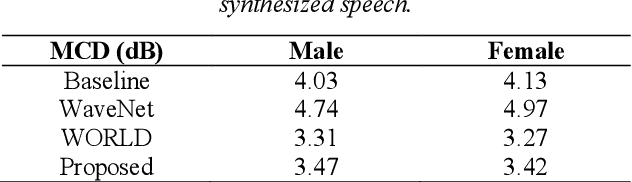
Neural network-based Text-to-Speech has significantly improved the quality of synthesized speech. Prominent methods (e.g., Tacotron2, FastSpeech, FastPitch) usually generate Mel-spectrogram from text and then synthesize speech using vocoder (e.g., WaveNet, WaveGlow, HiFiGAN). Compared with traditional parametric approaches (e.g., STRAIGHT and WORLD), neural vocoder based end-to-end models suffer from slow inference speed, and the synthesized speech is usually not robust and lack of controllability. In this work, we propose a novel updated vocoder, which is a simple signal model to train and easy to generate waveforms. We use the Gaussian-Markov model toward robust learning of spectral envelope and wavelet-based statistical signal processing to characterize and decompose F0 features. It can retain the fine spectral envelope and achieve high controllability of natural speech. The experimental results demonstrate that our proposed vocoder achieves better naturalness of reconstructed speech than the conventional STRAIGHT vocoder, slightly better than WaveNet, and somewhat worse than the WaveRNN.
Speaker Adaptation with Continuous Vocoder-based DNN-TTS
Aug 02, 2021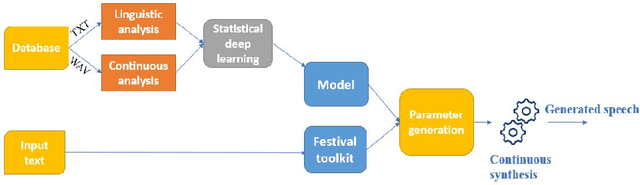
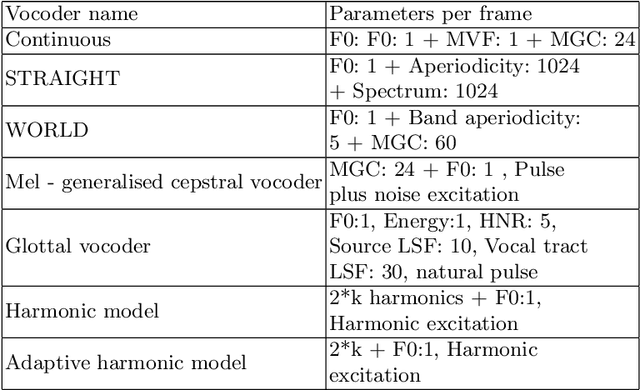
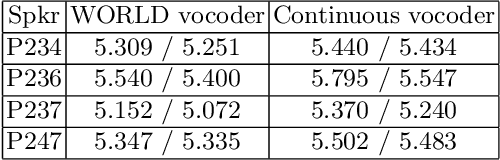

Traditional vocoder-based statistical parametric speech synthesis can be advantageous in applications that require low computational complexity. Recent neural vocoders, which can produce high naturalness, still cannot fulfill the requirement of being real-time during synthesis. In this paper, we experiment with our earlier continuous vocoder, in which the excitation is modeled with two one-dimensional parameters: continuous F0 and Maximum Voiced Frequency. We show on the data of 9 speakers that an average voice can be trained for DNN-TTS, and speaker adaptation is feasible 400 utterances (about 14 minutes). Objective experiments support that the quality of speaker adaptation with Continuous Vocoder-based DNN-TTS is similar to the quality of the speaker adaptation with a WORLD Vocoder-based baseline.
Adaptation of Tacotron2-based Text-To-Speech for Articulatory-to-Acoustic Mapping using Ultrasound Tongue Imaging
Jul 26, 2021
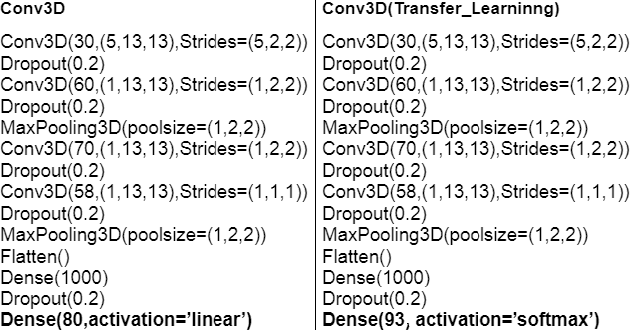
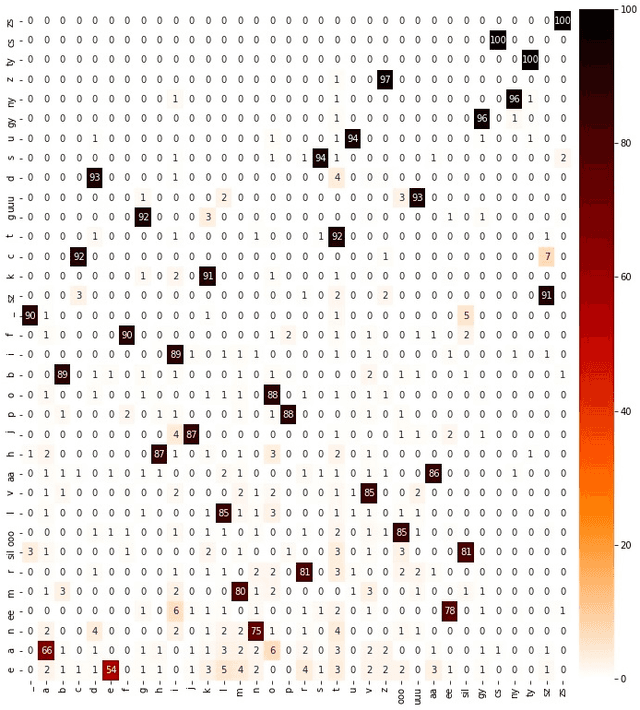
For articulatory-to-acoustic mapping, typically only limited parallel training data is available, making it impossible to apply fully end-to-end solutions like Tacotron2. In this paper, we experimented with transfer learning and adaptation of a Tacotron2 text-to-speech model to improve the final synthesis quality of ultrasound-based articulatory-to-acoustic mapping with a limited database. We use a multi-speaker pre-trained Tacotron2 TTS model and a pre-trained WaveGlow neural vocoder. The articulatory-to-acoustic conversion contains three steps: 1) from a sequence of ultrasound tongue image recordings, a 3D convolutional neural network predicts the inputs of the pre-trained Tacotron2 model, 2) the Tacotron2 model converts this intermediate representation to an 80-dimensional mel-spectrogram, and 3) the WaveGlow model is applied for final inference. This generated speech contains the timing of the original articulatory data from the ultrasound recording, but the F0 contour and the spectral information is predicted by the Tacotron2 model. The F0 values are independent of the original ultrasound images, but represent the target speaker, as they are inferred from the pre-trained Tacotron2 model. In our experiments, we demonstrated that the synthesized speech quality is more natural with the proposed solutions than with our earlier model.
Extending Text-to-Speech Synthesis with Articulatory Movement Prediction using Ultrasound Tongue Imaging
Jul 12, 2021
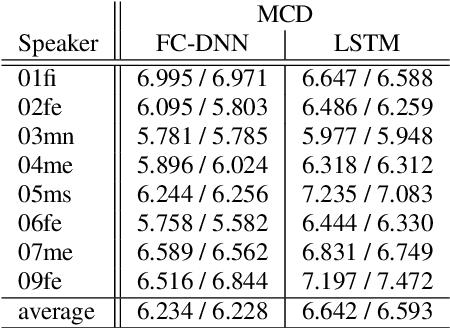
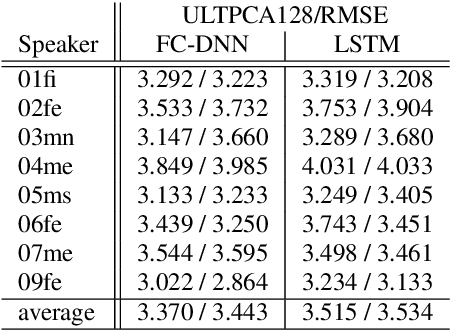

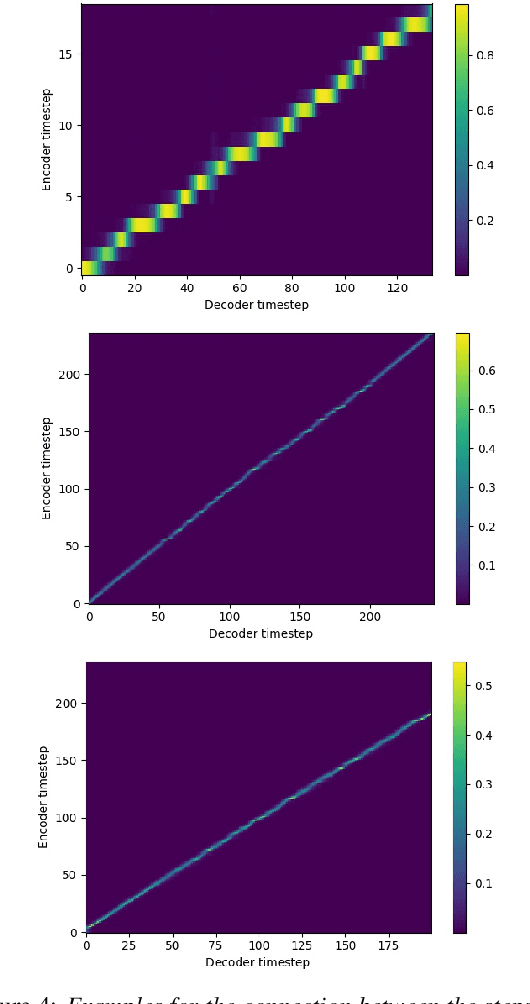
In this paper, we present our first experiments in text-to-articulation prediction, using ultrasound tongue image targets. We extend a traditional (vocoder-based) DNN-TTS framework with predicting PCA-compressed ultrasound images, of which the continuous tongue motion can be reconstructed in synchrony with synthesized speech. We use the data of eight speakers, train fully connected and recurrent neural networks, and show that FC-DNNs are more suitable for the prediction of sequential data than LSTMs, in case of limited training data. Objective experiments and visualized predictions show that the proposed solution is feasible and the generated ultrasound videos are close to natural tongue movement. Articulatory movement prediction from text input can be useful for audiovisual speech synthesis or computer-assisted pronunciation training.
Speech Synthesis from Text and Ultrasound Tongue Image-based Articulatory Input
Jul 05, 2021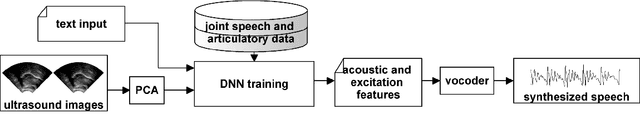
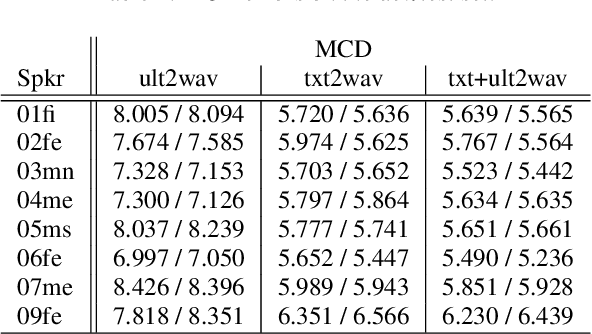
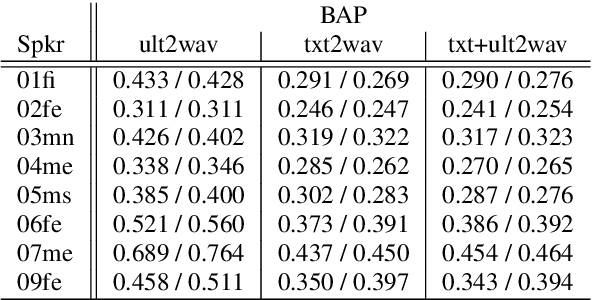
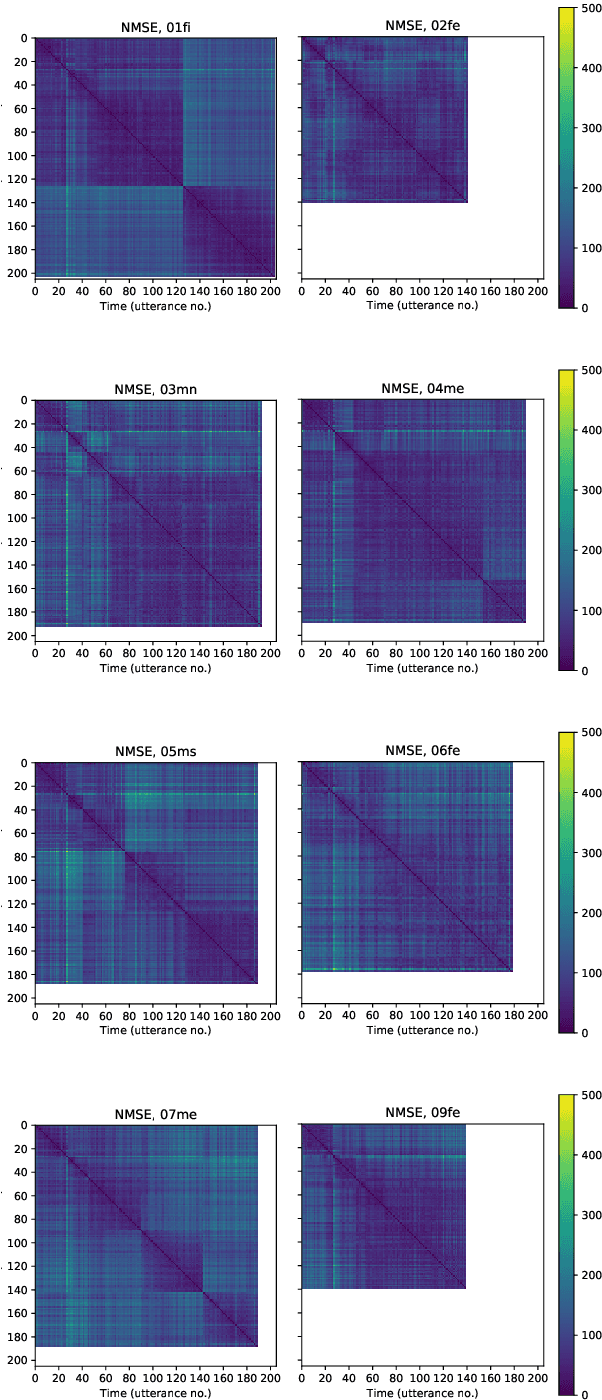
Articulatory information has been shown to be effective in improving the performance of HMM-based and DNN-based text-to-speech synthesis. Speech synthesis research focuses traditionally on text-to-speech conversion, when the input is text or an estimated linguistic representation, and the target is synthesized speech. However, a research field that has risen in the last decade is articulation-to-speech synthesis (with a target application of a Silent Speech Interface, SSI), when the goal is to synthesize speech from some representation of the movement of the articulatory organs. In this paper, we extend traditional (vocoder-based) DNN-TTS with articulatory input, estimated from ultrasound tongue images. We compare text-only, ultrasound-only, and combined inputs. Using data from eight speakers, we show that that the combined text and articulatory input can have advantages in limited-data scenarios, namely, it may increase the naturalness of synthesized speech compared to single text input. Besides, we analyze the ultrasound tongue recordings of several speakers, and show that misalignments in the ultrasound transducer positioning can have a negative effect on the final synthesis performance.
Advances in Speech Vocoding for Text-to-Speech with Continuous Parameters
Jun 19, 2021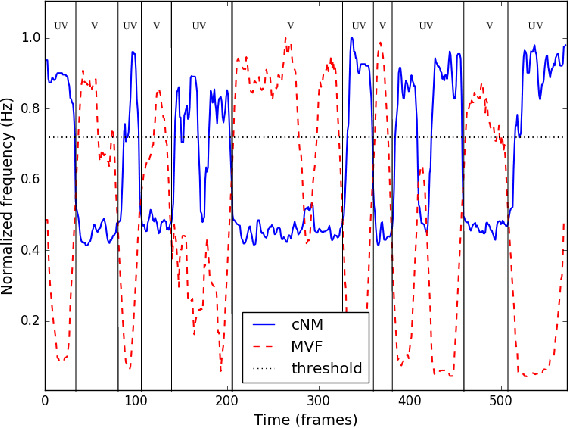
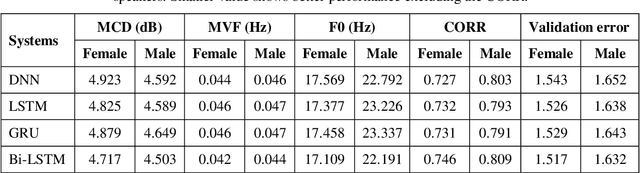
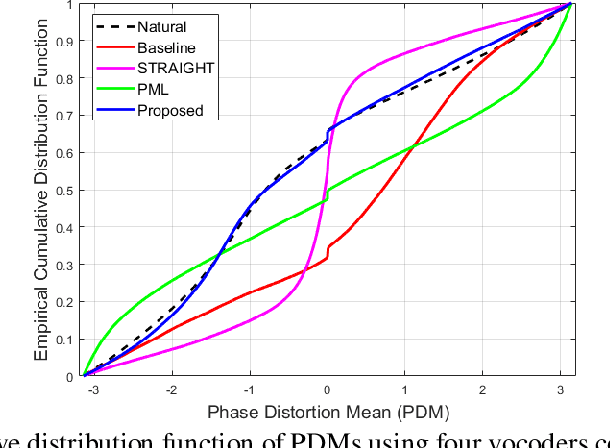
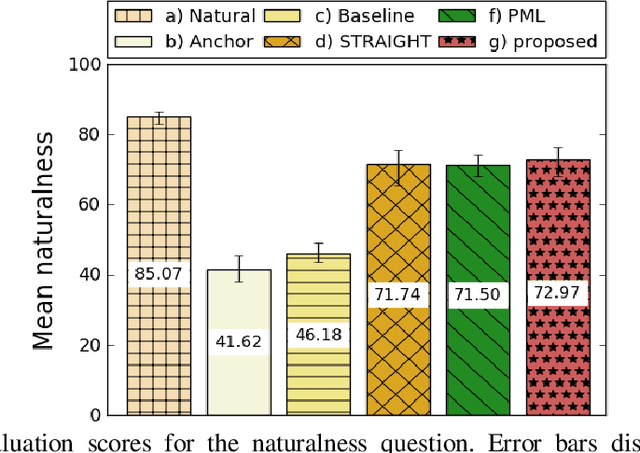
Vocoders received renewed attention as main components in statistical parametric text-to-speech (TTS) synthesis and speech transformation systems. Even though there are vocoding techniques give almost accepted synthesized speech, their high computational complexity and irregular structures are still considered challenging concerns, which yield a variety of voice quality degradation. Therefore, this paper presents new techniques in a continuous vocoder, that is all features are continuous and presents a flexible speech synthesis system. First, a new continuous noise masking based on the phase distortion is proposed to eliminate the perceptual impact of the residual noise and letting an accurate reconstruction of noise characteristics. Second, we addressed the need of neural sequence to sequence modeling approach for the task of TTS based on recurrent networks. Bidirectional long short-term memory (LSTM) and gated recurrent unit (GRU) are studied and applied to model continuous parameters for more natural-sounding like a human. The evaluation results proved that the proposed model achieves the state-of-the-art performance of the speech synthesis compared with the other traditional methods.
Continuous Wavelet Vocoder-based Decomposition of Parametric Speech Waveform Synthesis
Jun 12, 2021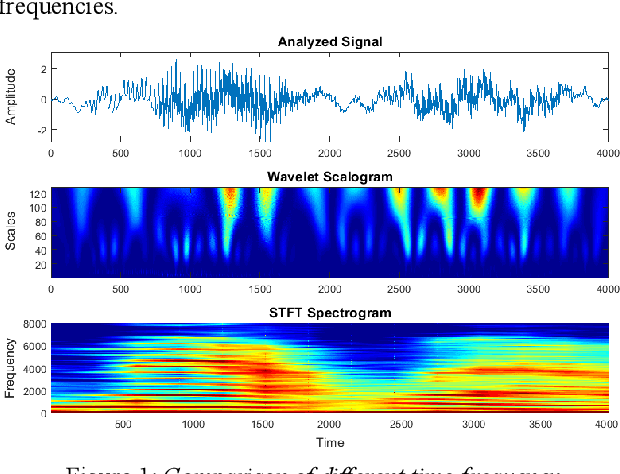
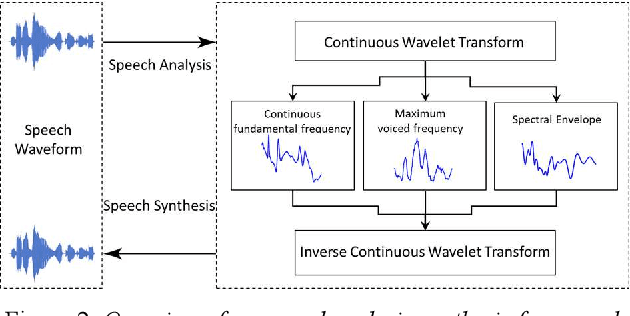

To date, various speech technology systems have adopted the vocoder approach, a method for synthesizing speech waveform that shows a major role in the performance of statistical parametric speech synthesis. WaveNet one of the best models that nearly resembles the human voice, has to generate a waveform in a time consuming sequential manner with an extremely complex structure of its neural networks.
Towards a practical lip-to-speech conversion system using deep neural networks and mobile application frontend
Apr 29, 2021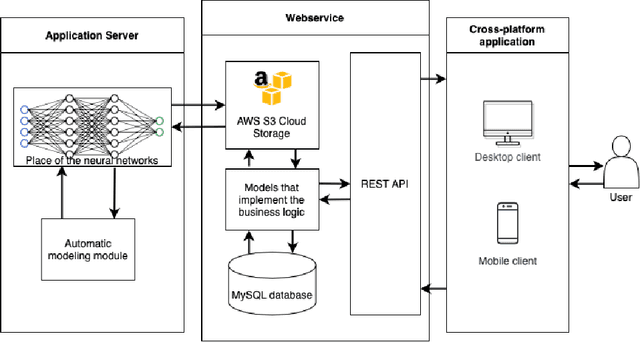
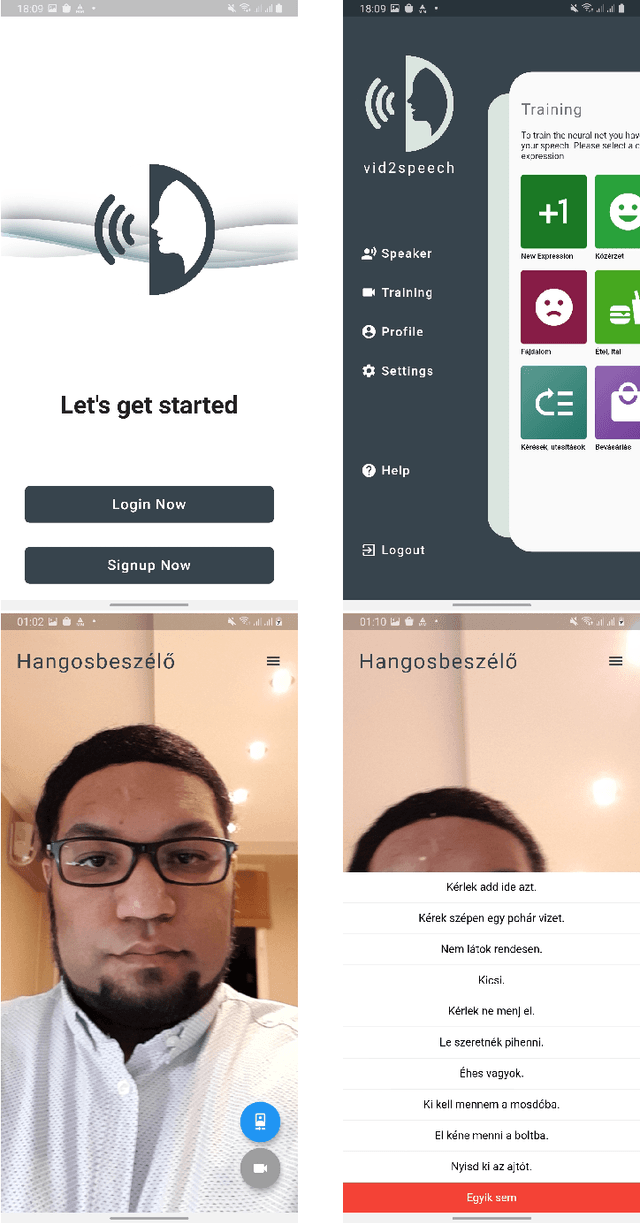
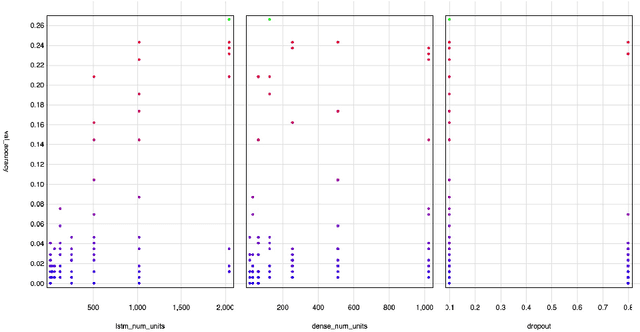
Articulatory-to-acoustic (forward) mapping is a technique to predict speech using various articulatory acquisition techniques as input (e.g. ultrasound tongue imaging, MRI, lip video). The advantage of lip video is that it is easily available and affordable: most modern smartphones have a front camera. There are already a few solutions for lip-to-speech synthesis, but they mostly concentrate on offline training and inference. In this paper, we propose a system built from a backend for deep neural network training and inference and a fronted as a form of a mobile application. Our initial evaluation shows that the scenario is feasible: a top-5 classification accuracy of 74% is combined with feedback from the mobile application user, making sure that the speaking impaired might be able to communicate with this solution.
Improving Neural Silent Speech Interface Models by Adversarial Training
Apr 23, 2021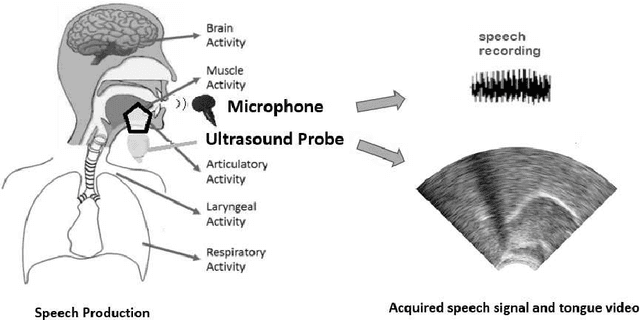
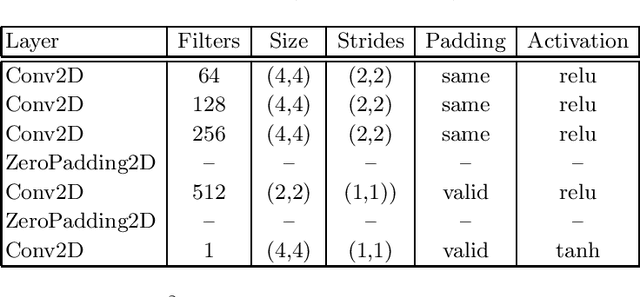
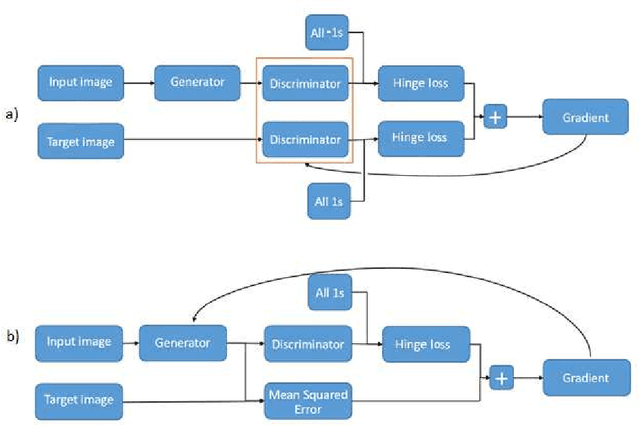

Besides the well-known classification task, these days neural networks are frequently being applied to generate or transform data, such as images and audio signals. In such tasks, the conventional loss functions like the mean squared error (MSE) may not give satisfactory results. To improve the perceptual quality of the generated signals, one possibility is to increase their similarity to real signals, where the similarity is evaluated via a discriminator network. The combination of the generator and discriminator nets is called a Generative Adversarial Network (GAN). Here, we evaluate this adversarial training framework in the articulatory-to-acoustic mapping task, where the goal is to reconstruct the speech signal from a recording of the movement of articulatory organs. As the generator, we apply a 3D convolutional network that gave us good results in an earlier study. To turn it into a GAN, we extend the conventional MSE training loss with an adversarial loss component provided by a discriminator network. As for the evaluation, we report various objective speech quality metrics such as the Perceptual Evaluation of Speech Quality (PESQ), and the Mel-Cepstral Distortion (MCD). Our results indicate that the application of the adversarial training loss brings about a slight, but consistent improvement in all these metrics.