 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a practical lip-to-speech conversion system using deep neural networks and mobile application frontend
Paper and Code
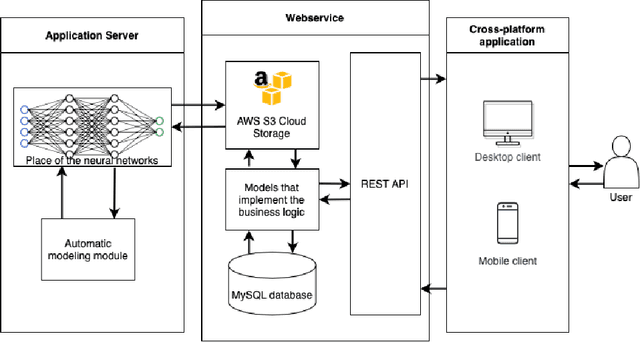
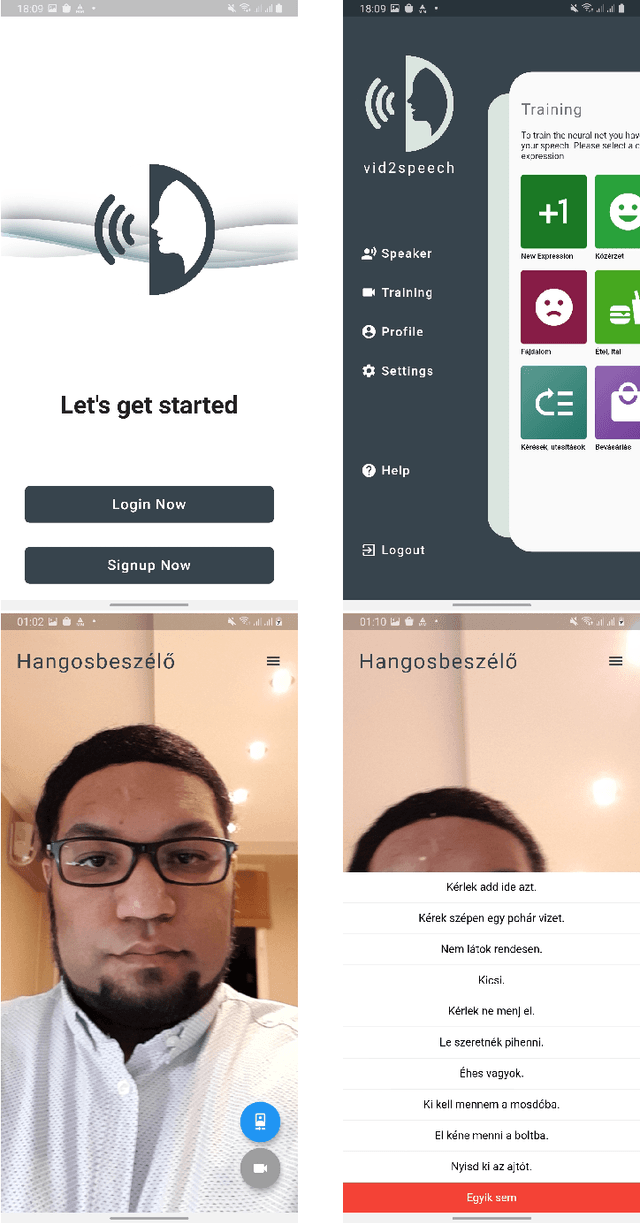
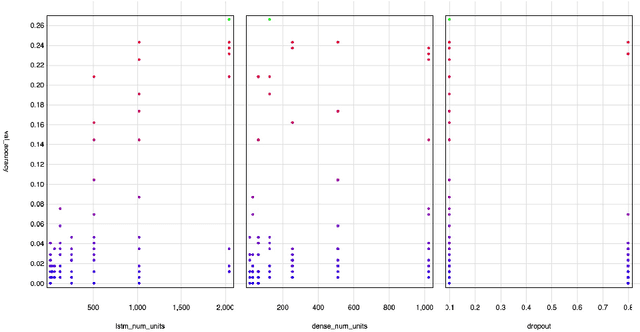
Articulatory-to-acoustic (forward) mapping is a technique to predict speech using various articulatory acquisition techniques as input (e.g. ultrasound tongue imaging, MRI, lip video). The advantage of lip video is that it is easily available and affordable: most modern smartphones have a front camera. There are already a few solutions for lip-to-speech synthesis, but they mostly concentrate on offline training and inference. In this paper, we propose a system built from a backend for deep neural network training and inference and a fronted as a form of a mobile application. Our initial evaluation shows that the scenario is feasible: a top-5 classification accuracy of 74% is combined with feedback from the mobile application user, making sure that the speaking impaired might be able to communicate with this solution.