 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Deep Learning for Subtype Classification in Breast Cancer Using Histopathological Images and Gene Expression Data
Mar 04, 2025Molecular subtyping of breast cancer is crucial for personalized treatment and prognosis. Traditional classification approaches rely on either histopathological images or gene expression profiling, limiting their predictive power. In this study, we propose a deep multimodal learning framework that integrates histopathological images and gene expression data to classify breast cancer into BRCA.Luminal and BRCA.Basal / Her2 subtypes. Our approach employs a ResNet-50 model for image feature extraction and fully connected layers for gene expression processing, with a cross-attention fusion mechanism to enhance modality interaction. We conduct extensive experiments using five-fold cross-validation, demonstrating that our multimodal integration outperforms unimodal approaches in terms of classification accuracy, precision-recall AUC, and F1-score. Our findings highlight the potential of deep learning for robust and interpretable breast cancer subtype classification, paving the way for improved clinical decision-making.
Automated Identification of Failure Cases in Organ at Risk Segmentation Using Distance Metrics: A Study on CT Data
Aug 21, 2023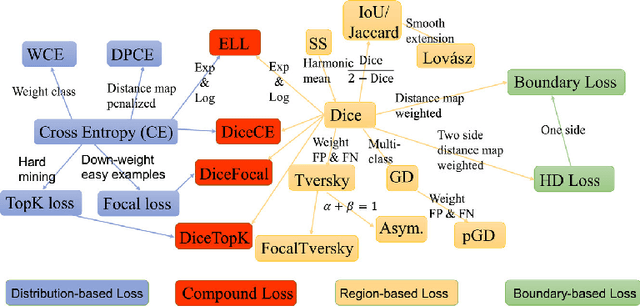
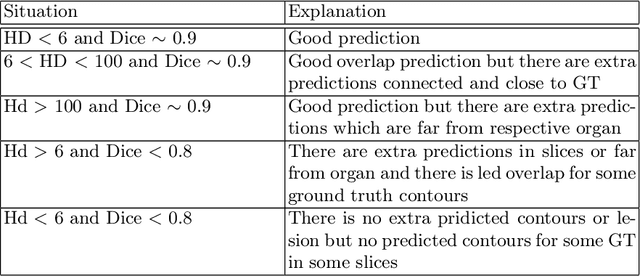
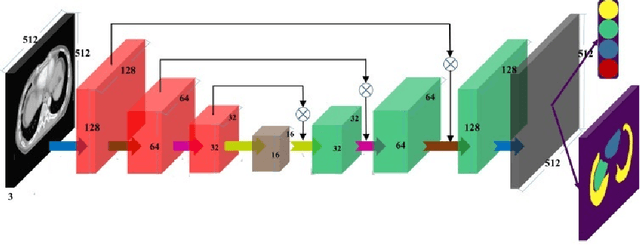
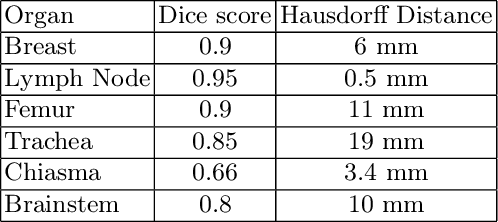
Automated organ at risk (OAR) segmentation is crucial for radiation therapy planning in CT scans, but the generated contours by automated models can be inaccurate, potentially leading to treatment planning issues. The reasons for these inaccuracies could be varied, such as unclear organ boundaries or inaccurate ground truth due to annotation errors. To improve the model's performance, it is necessary to identify these failure cases during the training process and to correct them with some potential post-processing techniques. However, this process can be time-consuming, as traditionally it requires manual inspection of the predicted output. This paper proposes a method to automatically identify failure cases by setting a threshold for the combination of Dice and Hausdorff distances. This approach reduces the time-consuming task of visually inspecting predicted outputs, allowing for faster identification of failure case candidates. The method was evaluated on 20 cases of six different organs in CT images from clinical expert curated datasets. By setting the thresholds for the Dice and Hausdorff distances, the study was able to differentiate between various states of failure cases and evaluate over 12 cases visually. This thresholding approach could be extended to other organs, leading to faster identification of failure cases and thereby improving the quality of radiation therapy planning.
Adaptation of Tongue Ultrasound-Based Silent Speech Interfaces Using Spatial Transformer Networks
May 31, 2023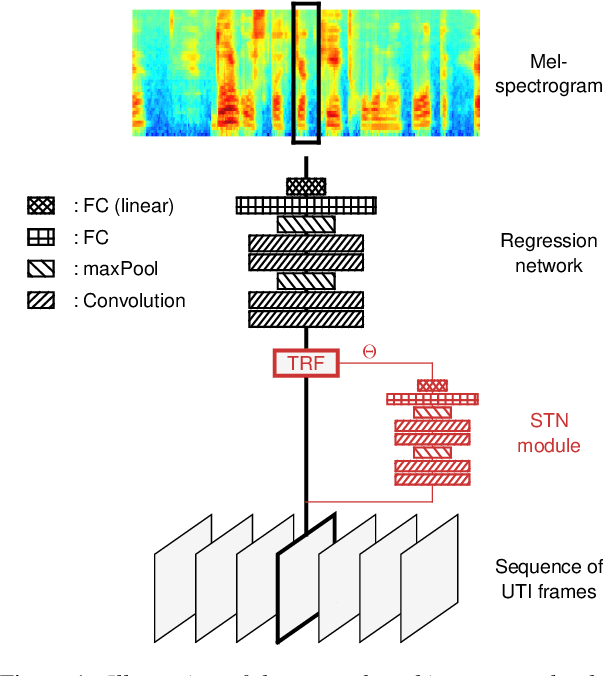
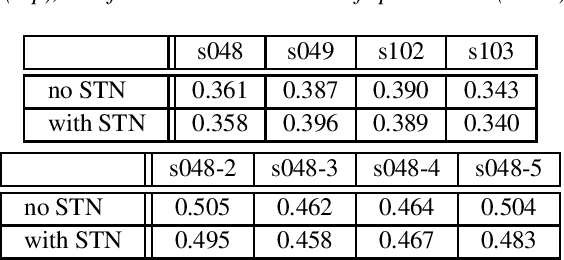
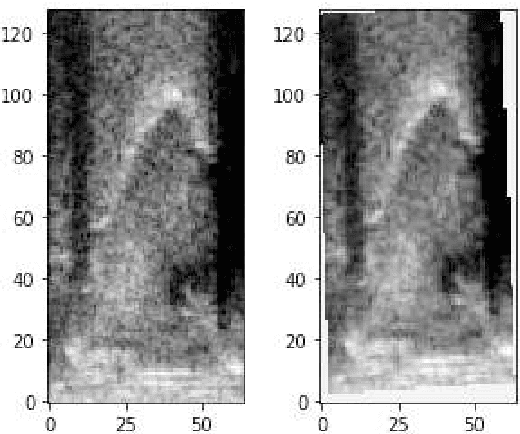
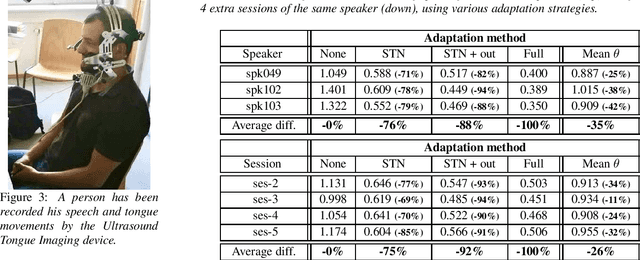
Thanks to the latest deep learning algorithms, silent speech interfaces (SSI) are now able to synthesize intelligible speech from articulatory movement data under certain conditions. However, the resulting models are rather speaker-specific, making a quick switch between users troublesome. Even for the same speaker, these models perform poorly cross-session, i.e. after dismounting and re-mounting the recording equipment. To aid quick speaker and session adaptation of ultrasound tongue imaging-based SSI models, we extend our deep networks with a spatial transformer network (STN) module, capable of performing an affine transformation on the input images. Although the STN part takes up only about 10% of the network, our experiments show that adapting just the STN module might allow to reduce MSE by 88% on the average, compared to retraining the whole network. The improvement is even larger (around 92%) when adapting the network to different recording sessions from the same speaker.
Improved Processing of Ultrasound Tongue Videos by Combining ConvLSTM and 3D Convolutional Networks
Jun 26, 2022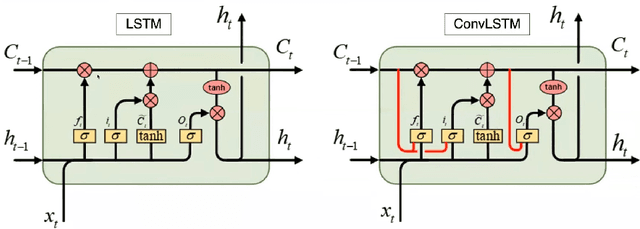
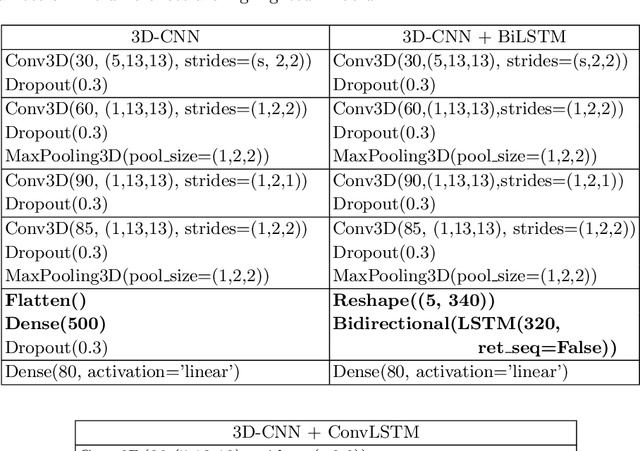
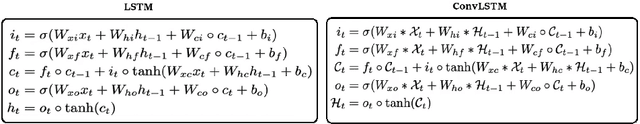
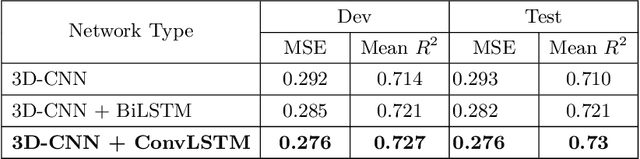
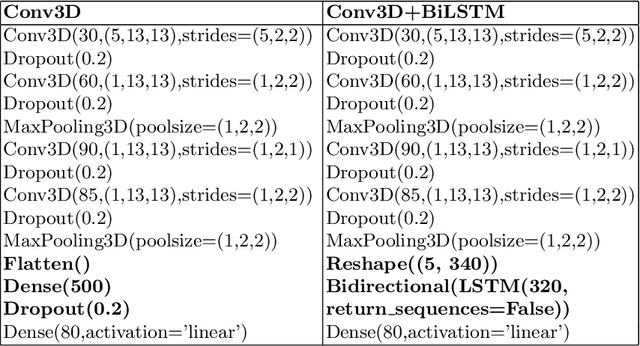
Silent Speech Interfaces aim to reconstruct the acoustic signal from a sequence of ultrasound tongue images that records the articulatory movement. The extraction of information about the tongue movement requires us to efficiently process the whole sequence of images, not just as a single image. Several approaches have been suggested to process such a sequential image data. The classic neural network structure combines two-dimensional convolutional (2D-CNN) layers that process the images separately with recurrent layers (eg. an LSTM) on top of them to fuse the information along time. More recently, it was shown that one may also apply a 3D-CNN network that can extract information along both the spatial and the temporal axes in parallel, achieving a similar accuracy while being less time consuming. A third option is to apply the less well-known ConvLSTM layer type, which combines the advantages of LSTM and CNN layers by replacing matrix multiplication with the convolution operation. In this paper, we experimentally compared various combinations of the above mentions layer types for a silent speech interface task, and we obtained the best result with a hybrid model that consists of a combination of 3D-CNN and ConvLSTM layers. This hybrid network is slightly faster, smaller and more accurate than our previous 3D-CNN model. %with combination of (2+1)D CNN.
Adaptation of Tacotron2-based Text-To-Speech for Articulatory-to-Acoustic Mapping using Ultrasound Tongue Imaging
Jul 26, 2021
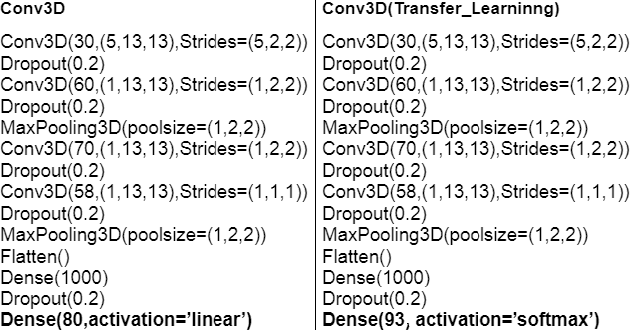
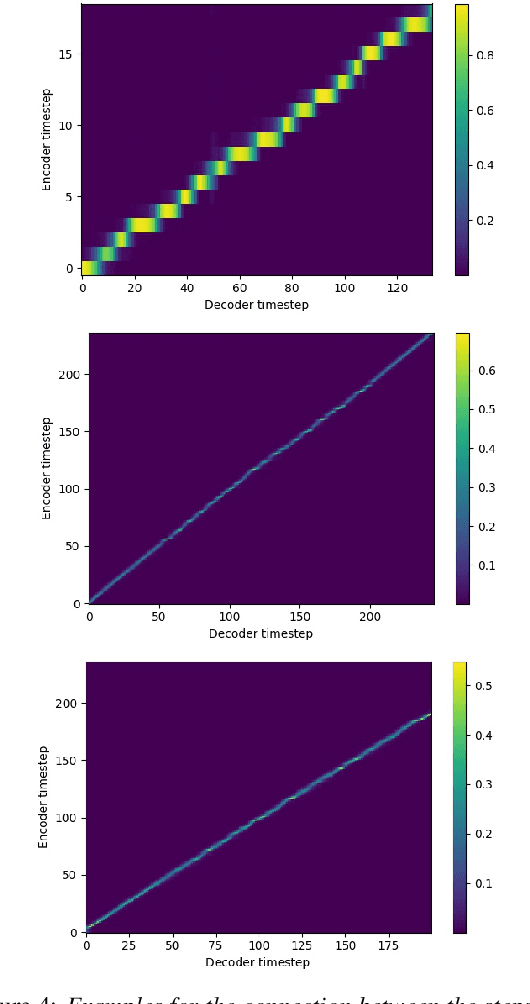
For articulatory-to-acoustic mapping, typically only limited parallel training data is available, making it impossible to apply fully end-to-end solutions like Tacotron2. In this paper, we experimented with transfer learning and adaptation of a Tacotron2 text-to-speech model to improve the final synthesis quality of ultrasound-based articulatory-to-acoustic mapping with a limited database. We use a multi-speaker pre-trained Tacotron2 TTS model and a pre-trained WaveGlow neural vocoder. The articulatory-to-acoustic conversion contains three steps: 1) from a sequence of ultrasound tongue image recordings, a 3D convolutional neural network predicts the inputs of the pre-trained Tacotron2 model, 2) the Tacotron2 model converts this intermediate representation to an 80-dimensional mel-spectrogram, and 3) the WaveGlow model is applied for final inference. This generated speech contains the timing of the original articulatory data from the ultrasound recording, but the F0 contour and the spectral information is predicted by the Tacotron2 model. The F0 values are independent of the original ultrasound images, but represent the target speaker, as they are inferred from the pre-trained Tacotron2 model. In our experiments, we demonstrated that the synthesized speech quality is more natural with the proposed solutions than with our earlier model.
Voice Activity Detection for Ultrasound-based Silent Speech Interfaces using Convolutional Neural Networks
Jun 03, 2021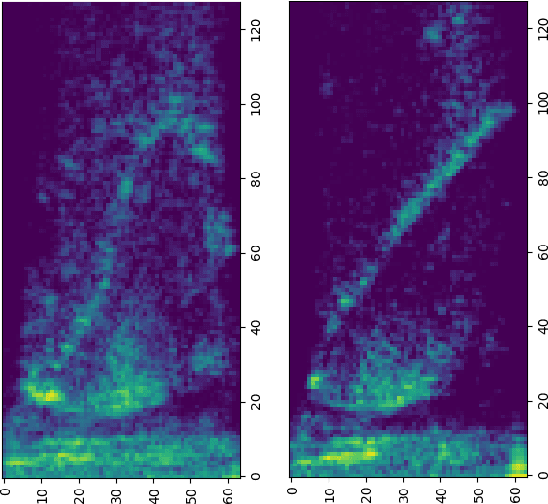

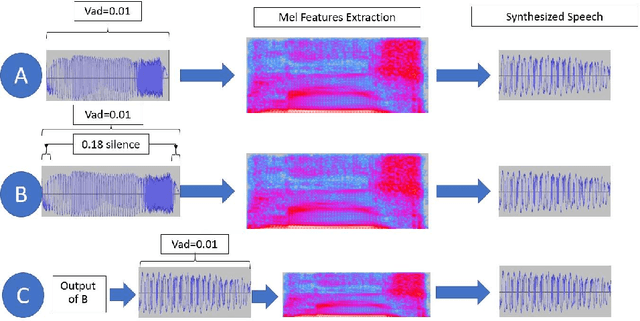
Voice Activity Detection (VAD) is not easy task when the input audio signal is noisy, and it is even more complicated when the input is not even an audio recording. This is the case with Silent Speech Interfaces (SSI) where we record the movement of the articulatory organs during speech, and we aim to reconstruct the speech signal from this recording. Our SSI system synthesizes speech from ultrasonic videos of the tongue movement, and the quality of the resulting speech signals are evaluated by metrics such as the mean squared error loss function of the underlying neural network and the Mel-Cepstral Distortion (MCD) of the reconstructed speech compared to the original. Here, we first demonstrate that the amount of silence in the training data can have an influence both on the MCD evaluation metric and on the performance of the neural network model. Then, we train a convolutional neural network classifier to separate silent and speech-containing ultrasound tongue images, using a conventional VAD algorithm to create the training labels from the corresponding speech signal. In the experiments our ultrasound-based speech/silence separator achieved a classification accuracy of about 85\% and an AUC score around 86\%.
Improving Neural Silent Speech Interface Models by Adversarial Training
Apr 23, 2021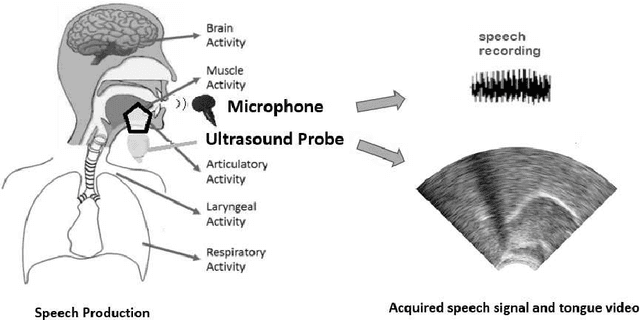
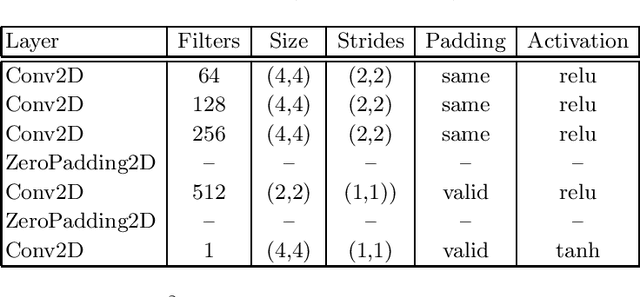
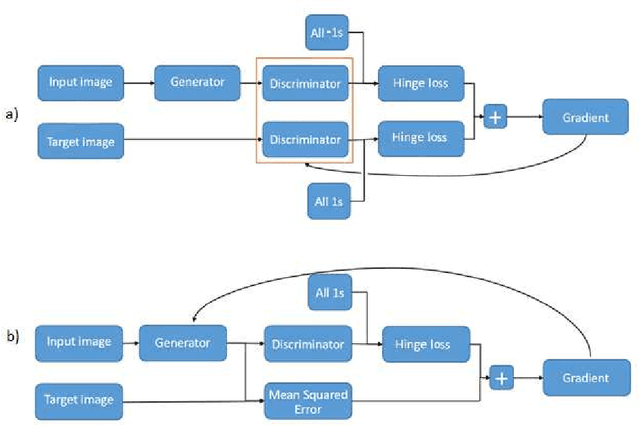

Besides the well-known classification task, these days neural networks are frequently being applied to generate or transform data, such as images and audio signals. In such tasks, the conventional loss functions like the mean squared error (MSE) may not give satisfactory results. To improve the perceptual quality of the generated signals, one possibility is to increase their similarity to real signals, where the similarity is evaluated via a discriminator network. The combination of the generator and discriminator nets is called a Generative Adversarial Network (GAN). Here, we evaluate this adversarial training framework in the articulatory-to-acoustic mapping task, where the goal is to reconstruct the speech signal from a recording of the movement of articulatory organs. As the generator, we apply a 3D convolutional network that gave us good results in an earlier study. To turn it into a GAN, we extend the conventional MSE training loss with an adversarial loss component provided by a discriminator network. As for the evaluation, we report various objective speech quality metrics such as the Perceptual Evaluation of Speech Quality (PESQ), and the Mel-Cepstral Distortion (MCD). Our results indicate that the application of the adversarial training loss brings about a slight, but consistent improvement in all these metrics.
Reconstructing Speech from Real-Time Articulatory MRI Using Neural Vocoders
Apr 23, 2021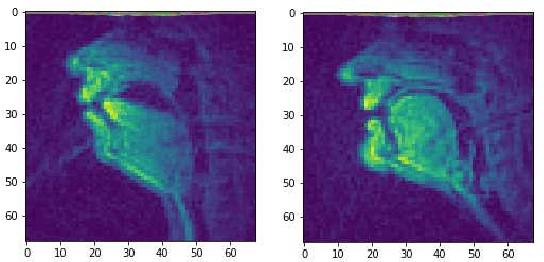
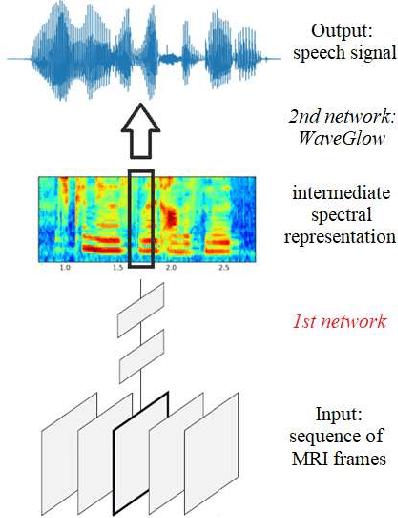
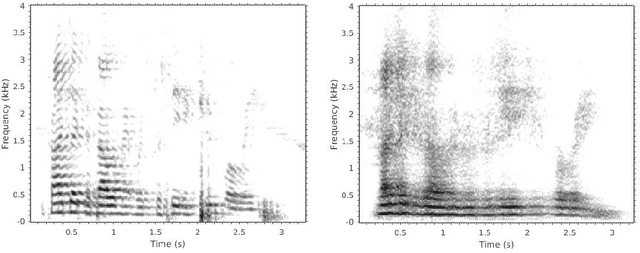

Several approaches exist for the recording of articulatory movements, such as eletromagnetic and permanent magnetic articulagraphy, ultrasound tongue imaging and surface electromyography. Although magnetic resonance imaging (MRI) is more costly than the above approaches, the recent developments in this area now allow the recording of real-time MRI videos of the articulators with an acceptable resolution. Here, we experiment with the reconstruction of the speech signal from a real-time MRI recording using deep neural networks. Instead of estimating speech directly, our networks are trained to output a spectral vector, from which we reconstruct the speech signal using the WaveGlow neural vocoder. We compare the performance of three deep neural architectures for the estimation task, combining convolutional (CNN) and recurrence-based (LSTM) neural layers. Besides the mean absolute error (MAE) of our networks, we also evaluate our models by comparing the speech signals obtained using several objective speech quality metrics like the mean cepstral distortion (MCD), Short-Time Objective Intelligibility (STOI), Perceptual Evaluation of Speech Quality (PESQ) and Signal-to-Distortion Ratio (SDR). The results indicate that our approach can successfully reconstruct the gross spectral shape, but more improvements are needed to reproduce the fine spectral details.
3D Convolutional Neural Networks for Ultrasound-Based Silent Speech Interfaces
Apr 23, 2021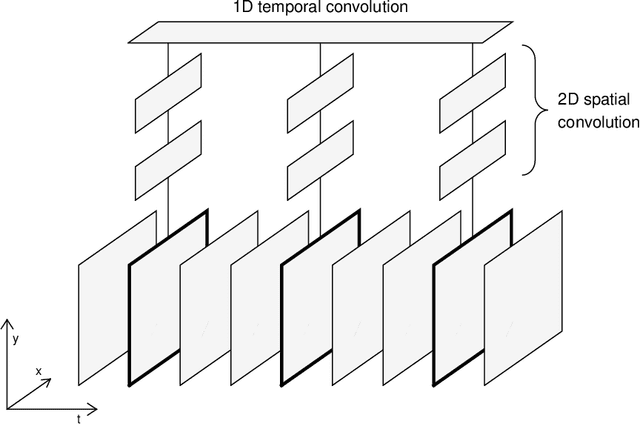
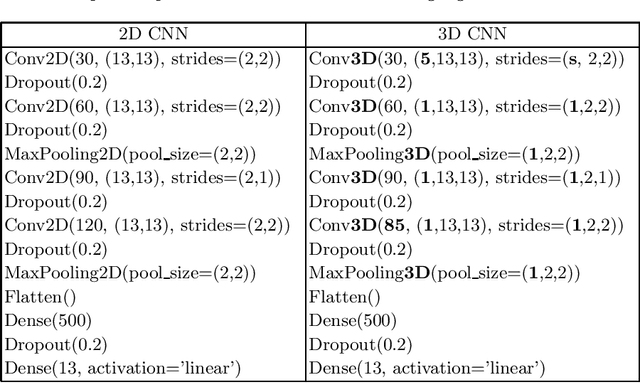
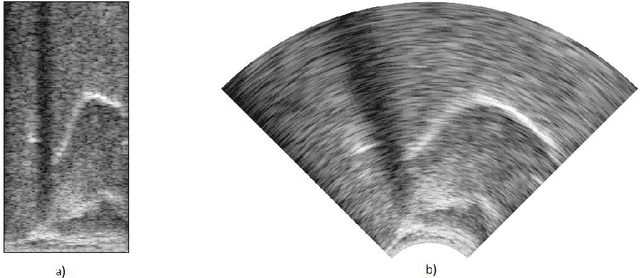
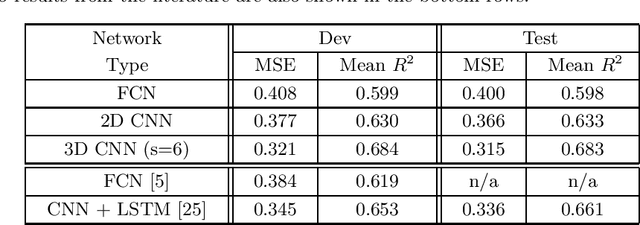
Silent speech interfaces (SSI) aim to reconstruct the speech signal from a recording of the articulatory movement, such as an ultrasound video of the tongue. Currently, deep neural networks are the most successful technology for this task. The efficient solution requires methods that do not simply process single images, but are able to extract the tongue movement information from a sequence of video frames. One option for this is to apply recurrent neural structures such as the long short-term memory network (LSTM) in combination with 2D convolutional neural networks (CNNs). Here, we experiment with another approach that extends the CNN to perform 3D convolution, where the extra dimension corresponds to time. In particular, we apply the spatial and temporal convolutions in a decomposed form, which proved very successful recently in video action recognition. We find experimentally that our 3D network outperforms the CNN+LSTM model, indicating that 3D CNNs may be a feasible alternative to CNN+LSTM networks in SSI systems.