 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Processing of Ultrasound Tongue Videos by Combining ConvLSTM and 3D Convolutional Networks
Paper and Code
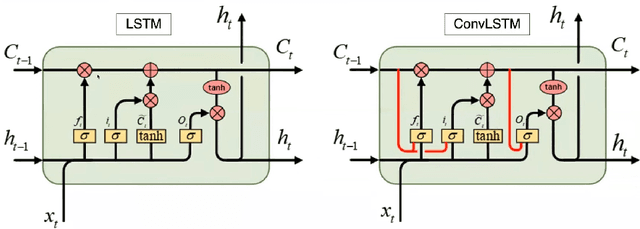
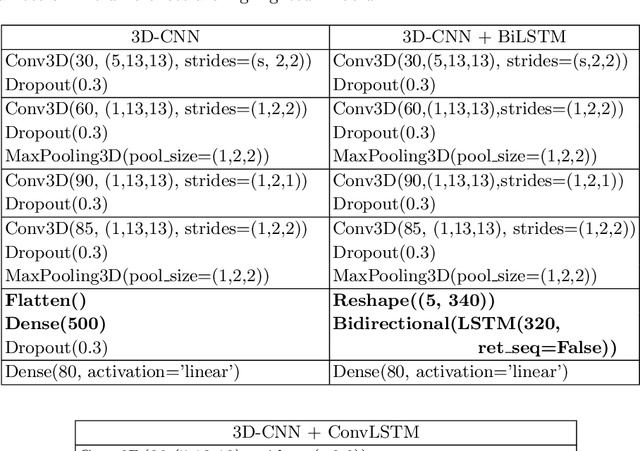
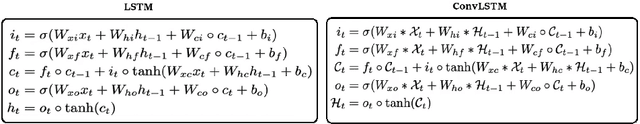
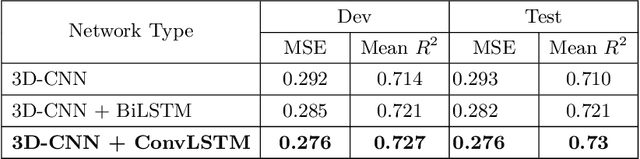
Silent Speech Interfaces aim to reconstruct the acoustic signal from a sequence of ultrasound tongue images that records the articulatory movement. The extraction of information about the tongue movement requires us to efficiently process the whole sequence of images, not just as a single image. Several approaches have been suggested to process such a sequential image data. The classic neural network structure combines two-dimensional convolutional (2D-CNN) layers that process the images separately with recurrent layers (eg. an LSTM) on top of them to fuse the information along time. More recently, it was shown that one may also apply a 3D-CNN network that can extract information along both the spatial and the temporal axes in parallel, achieving a similar accuracy while being less time consuming. A third option is to apply the less well-known ConvLSTM layer type, which combines the advantages of LSTM and CNN layers by replacing matrix multiplication with the convolution operation. In this paper, we experimentally compared various combinations of the above mentions layer types for a silent speech interface task, and we obtained the best result with a hybrid model that consists of a combination of 3D-CNN and ConvLSTM layers. This hybrid network is slightly faster, smaller and more accurate than our previous 3D-CNN model. %with combination of (2+1)D CNN.