 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptation of Tacotron2-based Text-To-Speech for Articulatory-to-Acoustic Mapping using Ultrasound Tongue Imaging
Jul 26, 2021
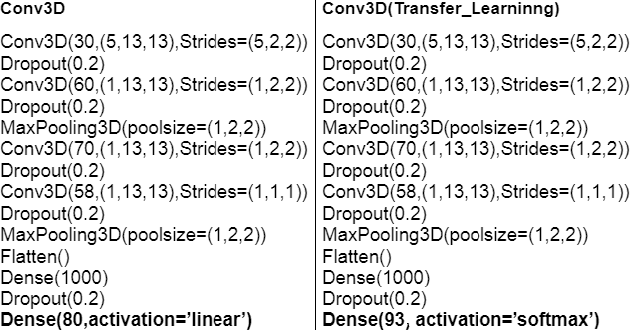
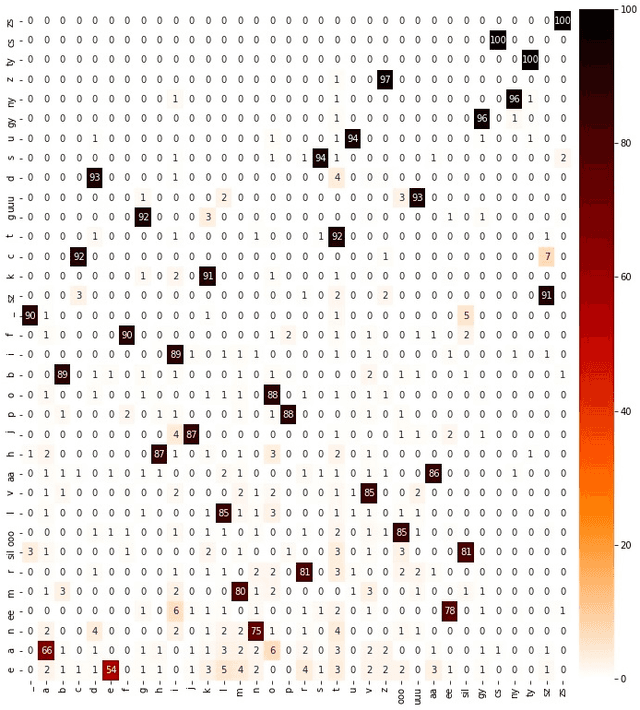
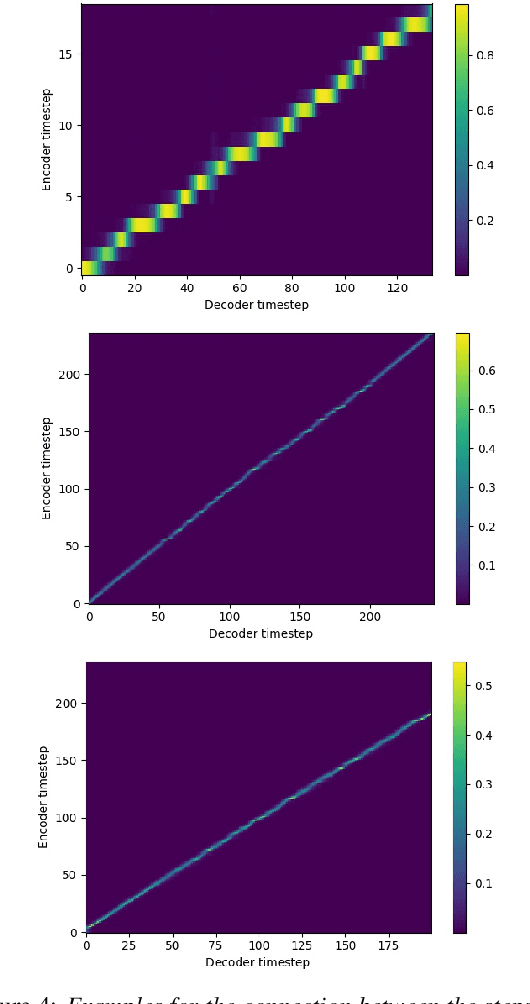
For articulatory-to-acoustic mapping, typically only limited parallel training data is available, making it impossible to apply fully end-to-end solutions like Tacotron2. In this paper, we experimented with transfer learning and adaptation of a Tacotron2 text-to-speech model to improve the final synthesis quality of ultrasound-based articulatory-to-acoustic mapping with a limited database. We use a multi-speaker pre-trained Tacotron2 TTS model and a pre-trained WaveGlow neural vocoder. The articulatory-to-acoustic conversion contains three steps: 1) from a sequence of ultrasound tongue image recordings, a 3D convolutional neural network predicts the inputs of the pre-trained Tacotron2 model, 2) the Tacotron2 model converts this intermediate representation to an 80-dimensional mel-spectrogram, and 3) the WaveGlow model is applied for final inference. This generated speech contains the timing of the original articulatory data from the ultrasound recording, but the F0 contour and the spectral information is predicted by the Tacotron2 model. The F0 values are independent of the original ultrasound images, but represent the target speaker, as they are inferred from the pre-trained Tacotron2 model. In our experiments, we demonstrated that the synthesized speech quality is more natural with the proposed solutions than with our earlier model.
Speech Synthesis from Text and Ultrasound Tongue Image-based Articulatory Input
Jul 05, 2021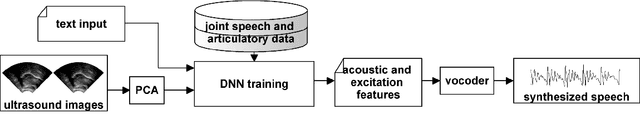
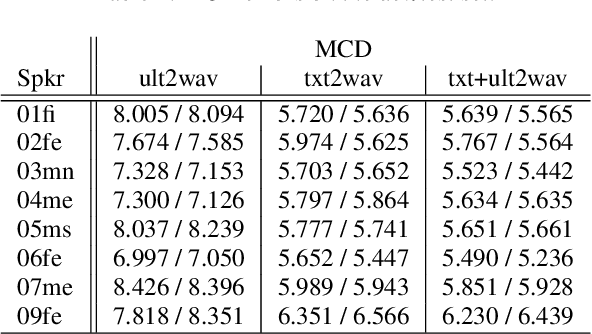
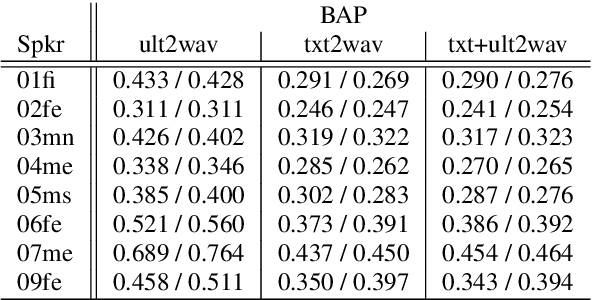
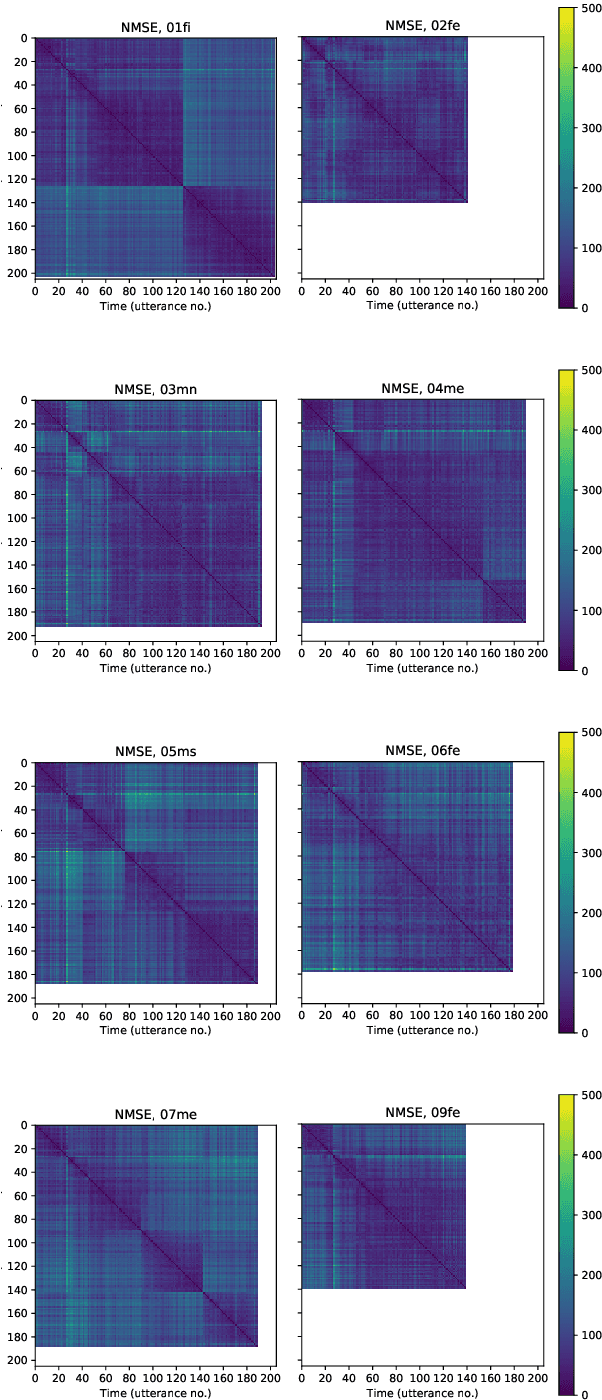
Articulatory information has been shown to be effective in improving the performance of HMM-based and DNN-based text-to-speech synthesis. Speech synthesis research focuses traditionally on text-to-speech conversion, when the input is text or an estimated linguistic representation, and the target is synthesized speech. However, a research field that has risen in the last decade is articulation-to-speech synthesis (with a target application of a Silent Speech Interface, SSI), when the goal is to synthesize speech from some representation of the movement of the articulatory organs. In this paper, we extend traditional (vocoder-based) DNN-TTS with articulatory input, estimated from ultrasound tongue images. We compare text-only, ultrasound-only, and combined inputs. Using data from eight speakers, we show that that the combined text and articulatory input can have advantages in limited-data scenarios, namely, it may increase the naturalness of synthesized speech compared to single text input. Besides, we analyze the ultrasound tongue recordings of several speakers, and show that misalignments in the ultrasound transducer positioning can have a negative effect on the final synthesis performance.
Improving Neural Silent Speech Interface Models by Adversarial Training
Apr 23, 2021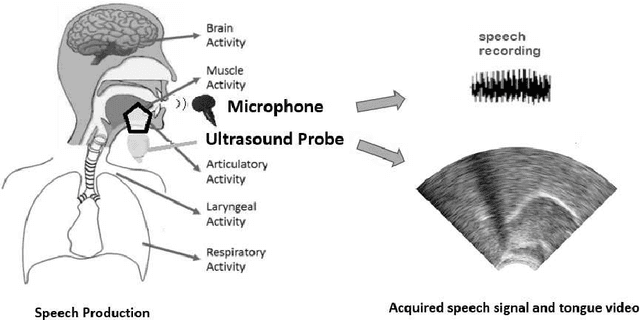
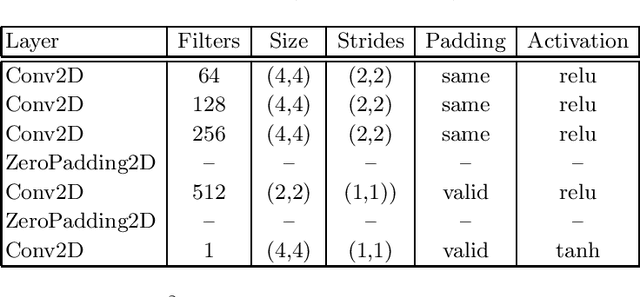
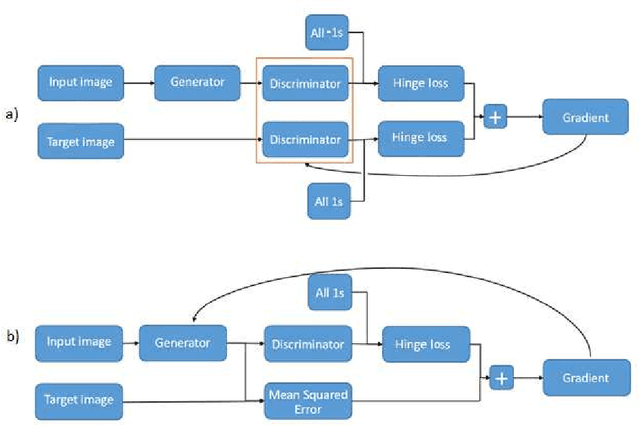

Besides the well-known classification task, these days neural networks are frequently being applied to generate or transform data, such as images and audio signals. In such tasks, the conventional loss functions like the mean squared error (MSE) may not give satisfactory results. To improve the perceptual quality of the generated signals, one possibility is to increase their similarity to real signals, where the similarity is evaluated via a discriminator network. The combination of the generator and discriminator nets is called a Generative Adversarial Network (GAN). Here, we evaluate this adversarial training framework in the articulatory-to-acoustic mapping task, where the goal is to reconstruct the speech signal from a recording of the movement of articulatory organs. As the generator, we apply a 3D convolutional network that gave us good results in an earlier study. To turn it into a GAN, we extend the conventional MSE training loss with an adversarial loss component provided by a discriminator network. As for the evaluation, we report various objective speech quality metrics such as the Perceptual Evaluation of Speech Quality (PESQ), and the Mel-Cepstral Distortion (MCD). Our results indicate that the application of the adversarial training loss brings about a slight, but consistent improvement in all these metrics.