 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Self-Supervised Learning-based MOS Prediction Networks
Paper and Code
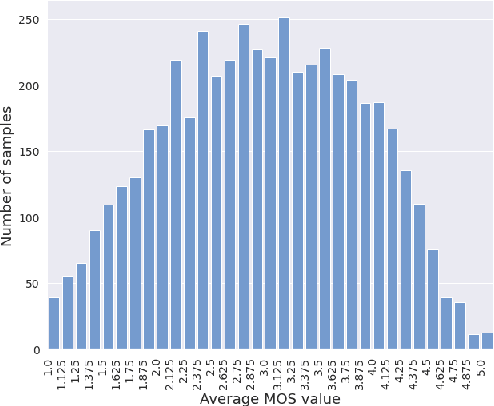
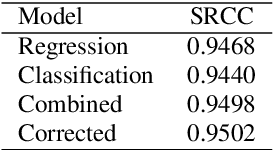
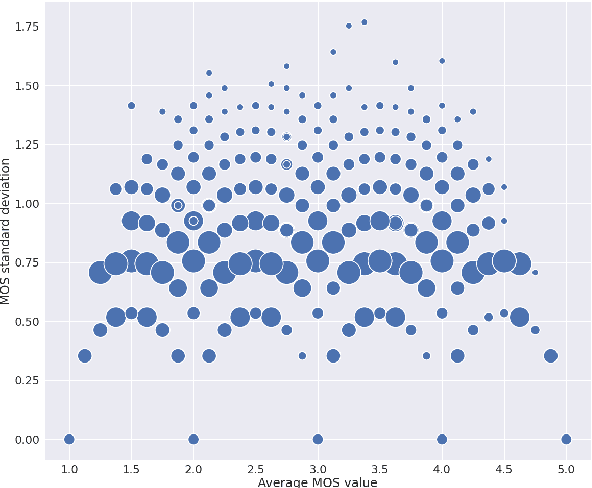
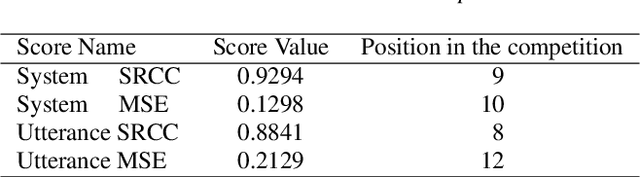
MOS (Mean Opinion Score) is a subjective method used for the evaluation of a system's quality. Telecommunications (for voice and video), and speech synthesis systems (for generated speech) are a few of the many applications of the method. While MOS tests are widely accepted, they are time-consuming and costly since human input is required. In addition, since the systems and subjects of the tests differ, the results are not really comparable. On the other hand, a large number of previous tests allow us to train machine learning models that are capable of predicting MOS value. By automatically predicting MOS values, both the aforementioned issues can be resolved. The present work introduces data-, training- and post-training specific improvements to a previous self-supervised learning-based MOS prediction model. We used a wav2vec 2.0 model pre-trained on LibriSpeech, extended with LSTM and non-linear dense layers. We introduced transfer learning, target data preprocessing a two- and three-phase training method with different batch formulations, dropout accumulation (for larger batch sizes) and quantization of the predictions. The methods are evaluated using the shared synthetic speech dataset of the first Voice MOS challenge.