 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison and Analysis of New Curriculum Criteria for End-to-End ASR
Paper and Code
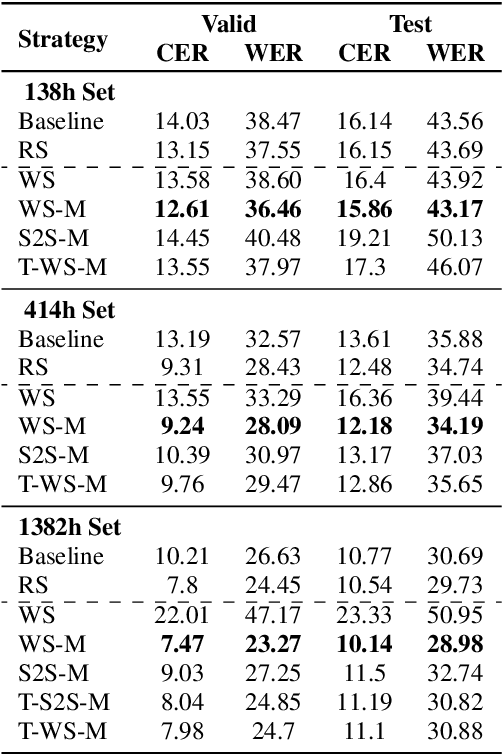
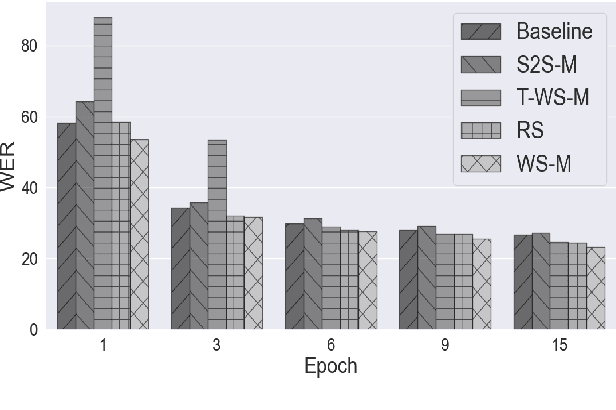
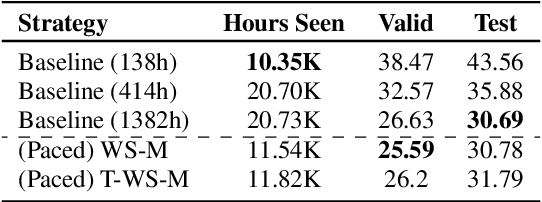
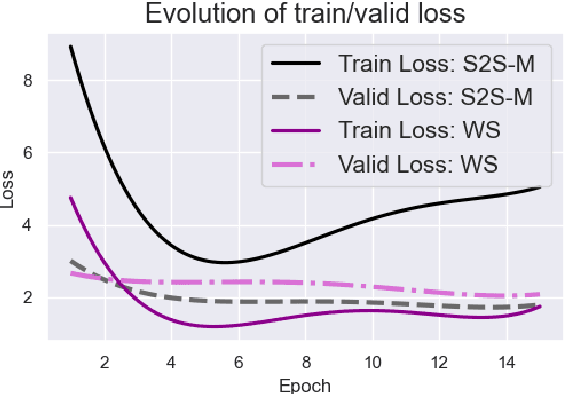
It is common knowledge that the quantity and quality of the training data play a significant role in the creation of a good machine learning model. In this paper, we take it one step further and demonstrate that the way the training examples are arranged is also of crucial importance. Curriculum Learning is built on the observation that organized and structured assimilation of knowledge has the ability to enable faster training and better comprehension. When humans learn to speak, they first try to utter basic phones and then gradually move towards more complex structures such as words and sentences. This methodology is known as Curriculum Learning, and we employ it in the context of Automatic Speech Recognition. We hypothesize that end-to-end models can achieve better performance when provided with an organized training set consisting of examples that exhibit an increasing level of difficulty (i.e. a curriculum). To impose structure on the training set and to define the notion of an easy example, we explored multiple scoring functions that either use feedback from an external neural network or incorporate feedback from the model itself. Empirical results show that with different curriculums we can balance the training times and the network's performance.