Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain-like approaches to unsupervised learning of hidden representations -- a comparative study
Paper and Code
May 06, 2020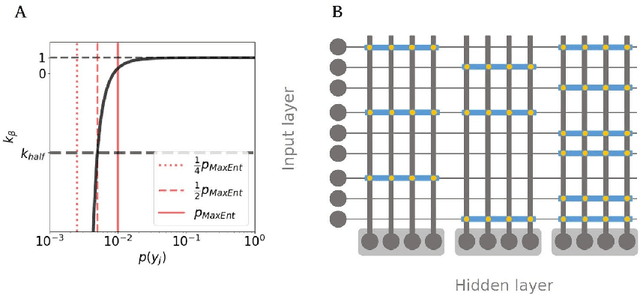
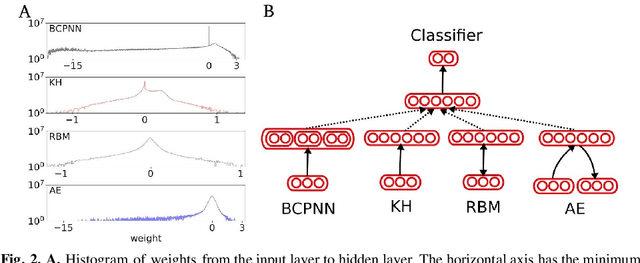
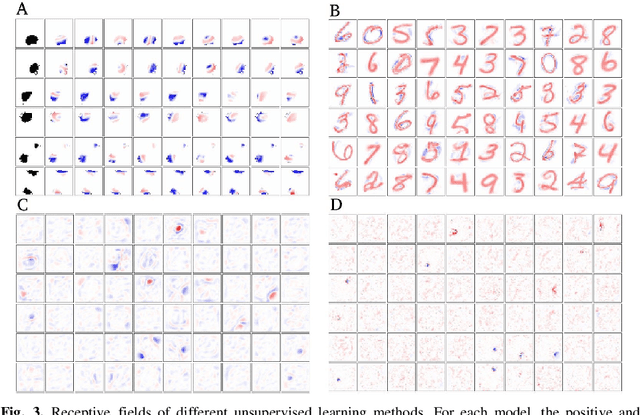
Unsupervised learning of hidden representations has been one of the most vibrant research directions in machine learning in recent years. In this work we study the brain-like Bayesian Confidence Propagating Neural Network (BCPNN) model, recently extended to extract sparse distributed high-dimensional representations. The saliency and separability of the hidden representations when trained on MNIST dataset is studied using an external classifier, and compared with other unsupervised learning methods that include restricted Boltzmann machines and autoencoders.
* arXiv admin note: text overlap with arXiv:2003.12415
View paper on