 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamical Mechanisms for Coordinating Long-term Working Memory Based on the Precision of Spike-timing in Cortical Neurons
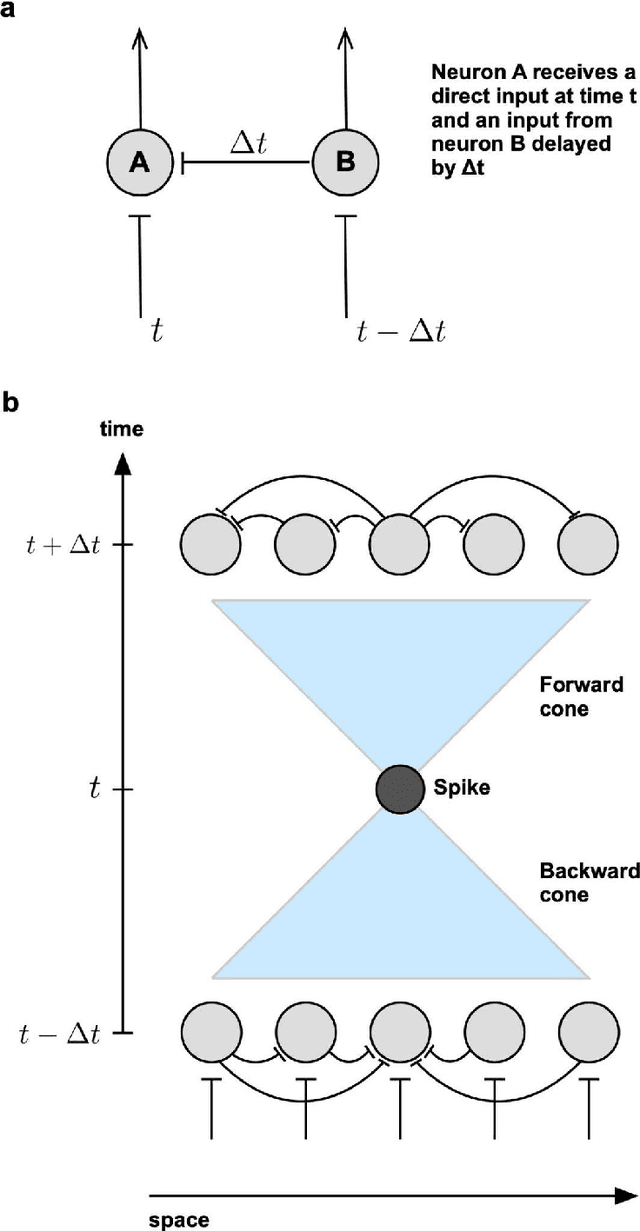
Dec 17, 2025In the last century, most sensorimotor studies of cortical neurons relied on average firing rates. Rate coding is efficient for fast sensorimotor processing that occurs within a few seconds. Much less is known about long-term working memory with a time scale of hours (Ericsson and Kintsch, 1995). The discovery of the millisecond precision of spike initiation in cortical neurons was unexpected (Mainen and Sejnowski, 1995). Even more striking was the precision of spiking in vivo, in response to rapidly fluctuating sensory inputs, suggesting that neural circuits could, in principle, preserve and manipulate sensory information through spike timing. It could support spike-timing-dependent plasticity (STDP), which is triggered by the relative timing of spikes between presynaptic and postsynaptic neurons in the millisecond range. What spike-timing mechanisms could regulate STDP in vivo? Cortical traveling waves have been observed across many frequency bands with high temporal precision. Traveling waves have wave fronts that could link spike timing to STDP. As a wave front passes through a cortical column, excitatory synapses on the dendrites of both pyramidal and basket cells are synchronously stimulated. Inhibitory basket cells form a calyx on pyramidal cell bodies, and inhibitory rebound following a strong transient hyperpolarization can trigger a backpropagating action potential, which arrives shortly after the excitatory inputs on pyramidal dendrites. STDP activated in this way could persist for hours, creating a second-tier network. This temporary network could support long-term working memory, a cognitive network riding above the long-term sensorimotor network. On their own, traveling waves and STDP have not yet yielded new insights into cortical function. Together, they could be responsible for how we think (Sejnowski, 2025).
Hidden Traveling Waves bind Working Memory Variables in Recurrent Neural Networks
Feb 17, 2024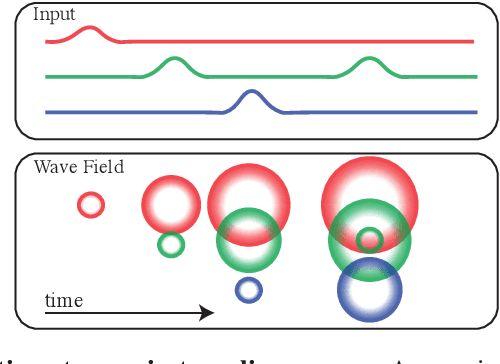
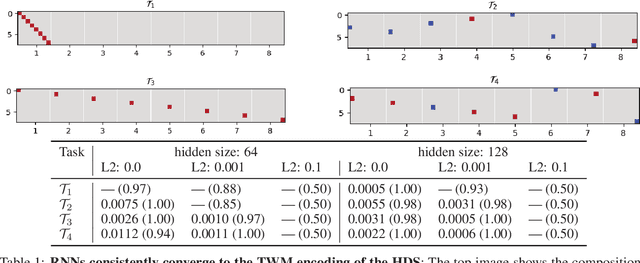
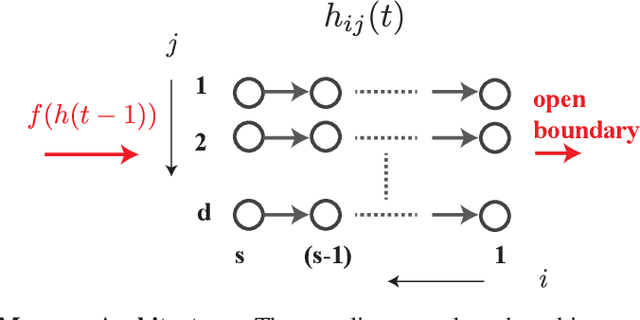
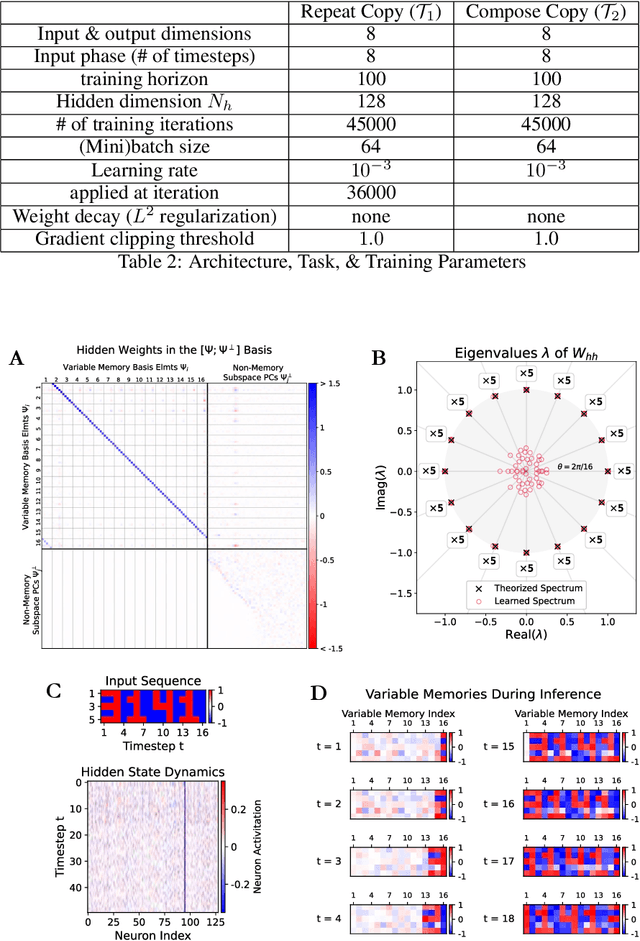
Traveling waves are a fundamental phenomenon in the brain, playing a crucial role in short-term information storage. In this study, we leverage the concept of traveling wave dynamics within a neural lattice to formulate a theoretical model of neural working memory, study its properties, and its real world implications in AI. The proposed model diverges from traditional approaches, which assume information storage in static, register-like locations updated by interference. Instead, the model stores data as waves that is updated by the wave's boundary conditions. We rigorously examine the model's capabilities in representing and learning state histories, which are vital for learning history-dependent dynamical systems. The findings reveal that the model reliably stores external information and enhances the learning process by addressing the diminishing gradient problem. To understand the model's real-world applicability, we explore two cases: linear boundary condition and non-linear, self-attention-driven boundary condition. The experiments reveal that the linear scenario is effectively learned by Recurrent Neural Networks (RNNs) through backpropagation when modeling history-dependent dynamical systems. Conversely, the non-linear scenario parallels the autoregressive loop of an attention-only transformer. Collectively, our findings suggest the broader relevance of traveling waves in AI and its potential in advancing neural network architectures.
Transformers and Cortical Waves: Encoders for Pulling In Context Across Time
Jan 25, 2024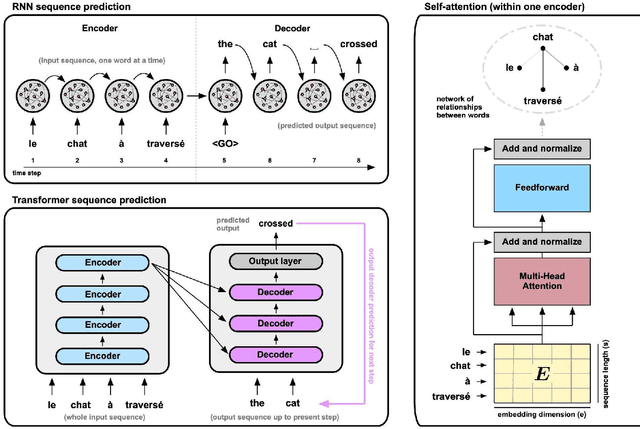
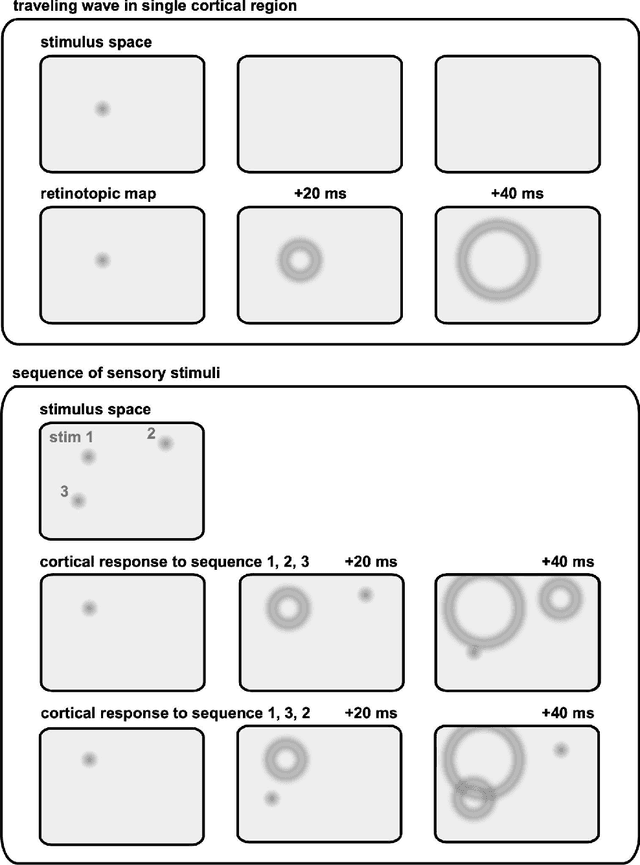
The capabilities of transformer networks such as ChatGPT and other Large Language Models (LLMs) have captured the world's attention. The crucial computational mechanism underlying their performance relies on transforming a complete input sequence - for example, all the words in a sentence into a long "encoding vector" - that allows transformers to learn long-range temporal dependencies in naturalistic sequences. Specifically, "self-attention" applied to this encoding vector enhances temporal context in transformers by computing associations between pairs of words in the input sequence. We suggest that waves of neural activity, traveling across single cortical regions or across multiple regions at the whole-brain scale, could implement a similar encoding principle. By encapsulating recent input history into a single spatial pattern at each moment in time, cortical waves may enable temporal context to be extracted from sequences of sensory inputs, the same computational principle used in transformers.
Replay in Deep Learning: Current Approaches and Missing Biological Elements
Apr 01, 2021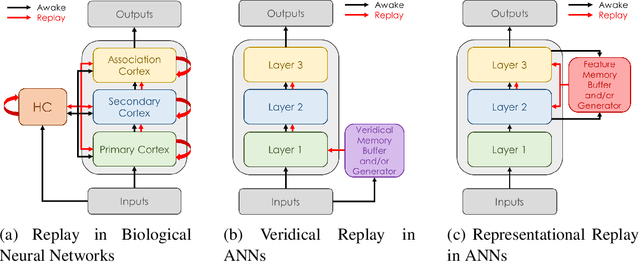
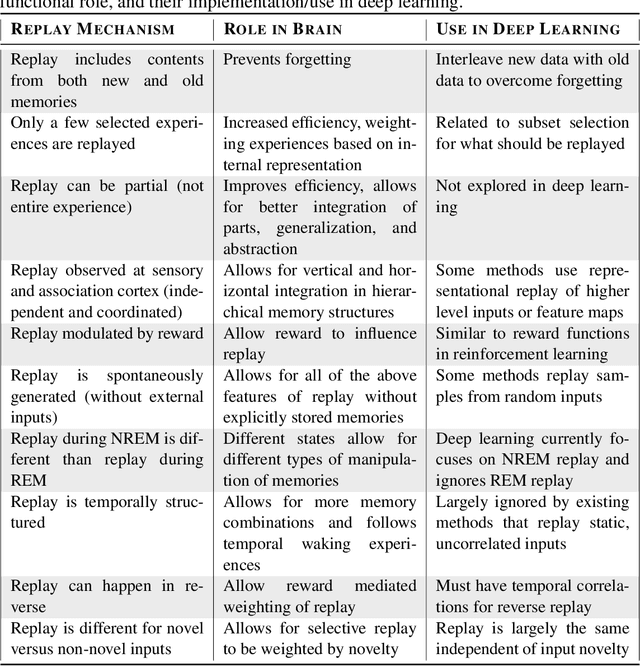
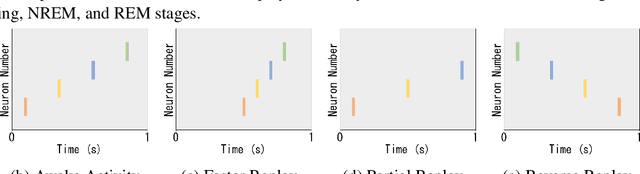
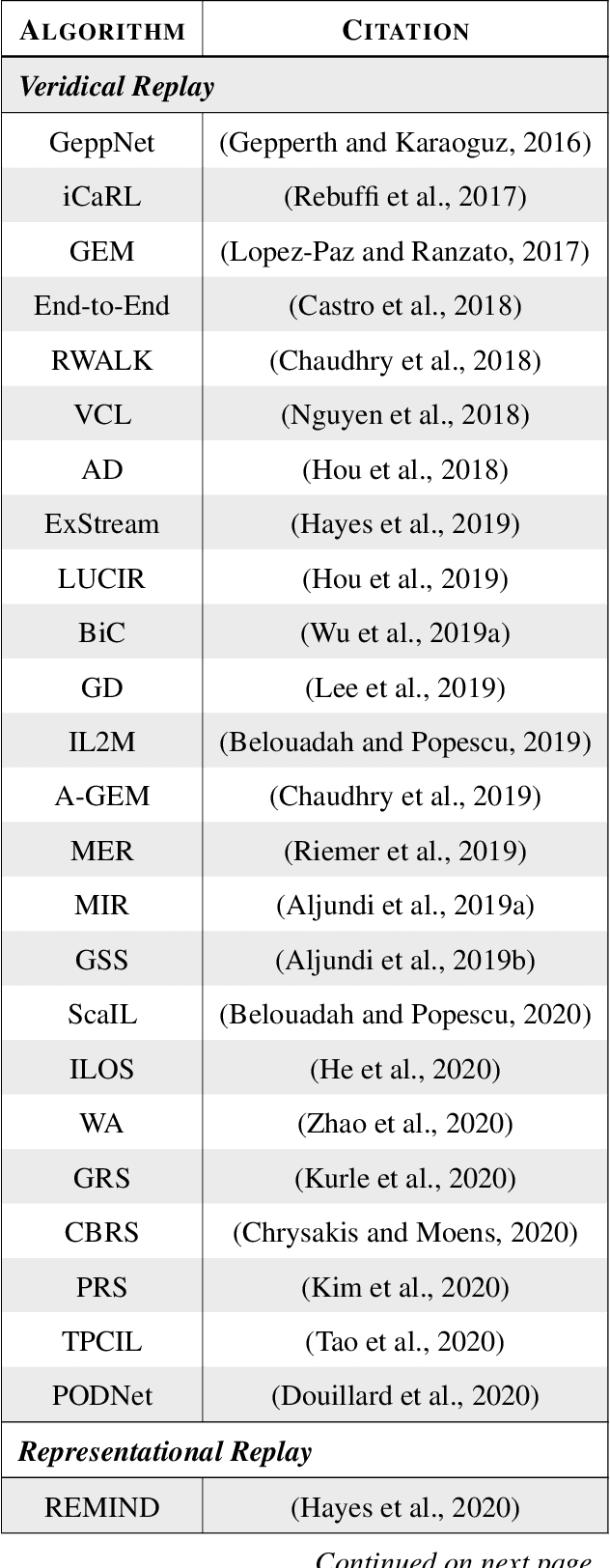
Replay is the reactivation of one or more neural patterns, which are similar to the activation patterns experienced during past waking experiences. Replay was first observed in biological neural networks during sleep, and it is now thought to play a critical role in memory formation, retrieval, and consolidation. Replay-like mechanisms have been incorporated into deep artificial neural networks that learn over time to avoid catastrophic forgetting of previous knowledge. Replay algorithms have been successfully used in a wide range of deep learning methods within supervised, unsupervised, and reinforcement learning paradigms. In this paper, we provide the first comprehensive comparison between replay in the mammalian brain and replay in artificial neural networks. We identify multiple aspects of biological replay that are missing in deep learning systems and hypothesize how they could be utilized to improve artificial neural networks.
The Unreasonable Effectiveness of Deep Learning in Artificial Intelligence
Feb 12, 2020



Deep learning networks have been trained to recognize speech, caption photographs and translate text between languages at high levels of performance. Although applications of deep learning networks to real world problems have become ubiquitous, our understanding of why they are so effective is lacking. These empirical results should not be possible according to sample complexity in statistics and non-convex optimization theory. However, paradoxes in the training and effectiveness of deep learning networks are being investigated and insights are being found in the geometry of high-dimensional spaces. A mathematical theory of deep learning would illuminate how they function, allow us to assess the strengths and weaknesses of different network architectures and lead to major improvements. Deep learning has provided natural ways for humans to communicate with digital devices and is foundational for building artificial general intelligence. Deep learning was inspired by the architecture of the cerebral cortex and insights into autonomy and general intelligence may be found in other brain regions that are essential for planning and survival, but major breakthroughs will be needed to achieve these goals.
Utilizing Deep Learning Towards Multi-modal Bio-sensing and Vision-based Affective Computing
May 16, 2019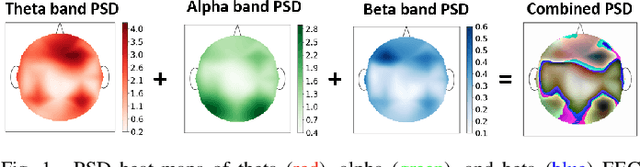
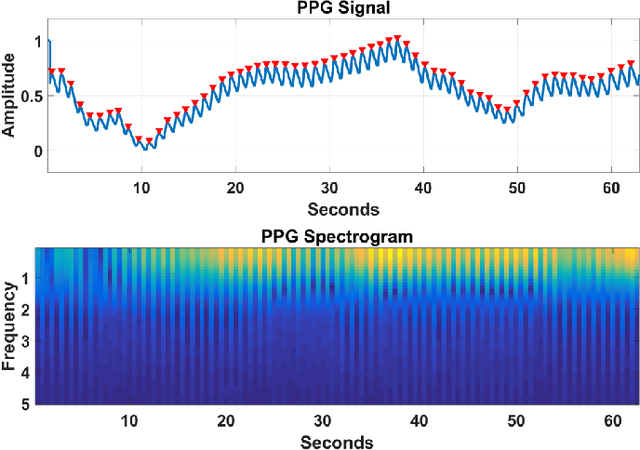
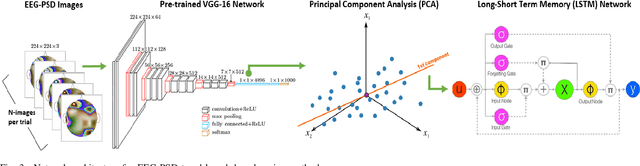

In recent years, the use of bio-sensing signals such as electroencephalogram (EEG), electrocardiogram (ECG), etc. have garnered interest towards applications in affective computing. The parallel trend of deep-learning has led to a huge leap in performance towards solving various vision-based research problems such as object detection. Yet, these advances in deep-learning have not adequately translated into bio-sensing research. This work applies novel deep-learning-based methods to various bio-sensing and video data of four publicly available multi-modal emotion datasets. For each dataset, we first individually evaluate the emotion-classification performance obtained by each modality. We then evaluate the performance obtained by fusing the features from these modalities. We show that our algorithms outperform the results reported by other studies for emotion/valence/arousal/liking classification on DEAP and MAHNOB-HCI datasets and set up benchmarks for the newer AMIGOS and DREAMER datasets. We also evaluate the performance of our algorithms by combining the datasets and by using transfer learning to show that the proposed method overcomes the inconsistencies between the datasets. Hence, we do a thorough analysis of multi-modal affective data from more than 120 subjects and 2,800 trials. Finally, utilizing a convolution-deconvolution network, we propose a new technique towards identifying salient brain regions corresponding to various affective states.
Gradient Descent for Spiking Neural Networks
Jun 19, 2017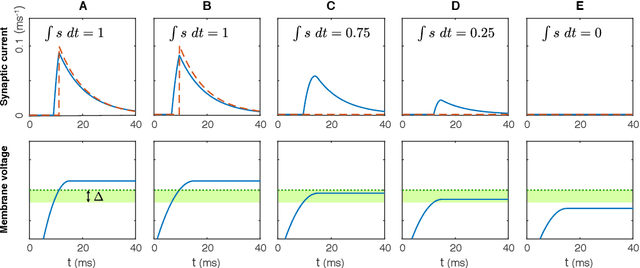
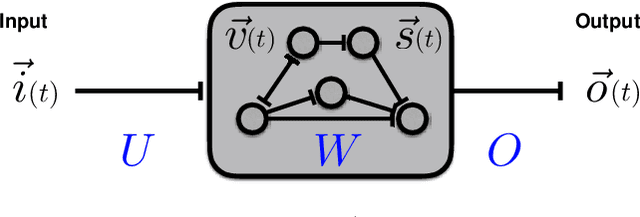
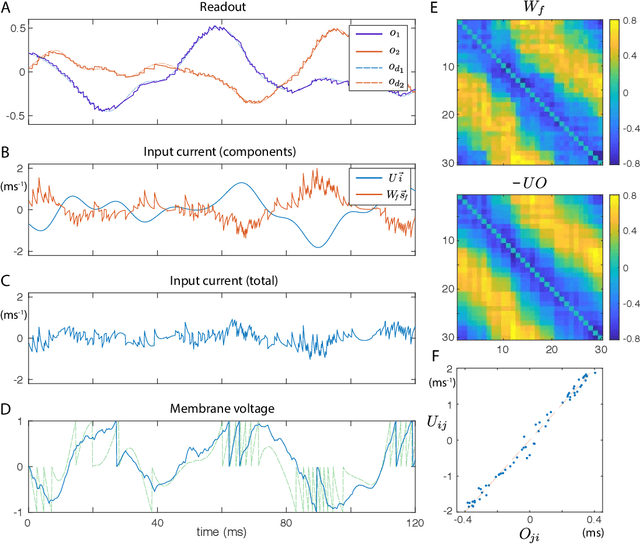
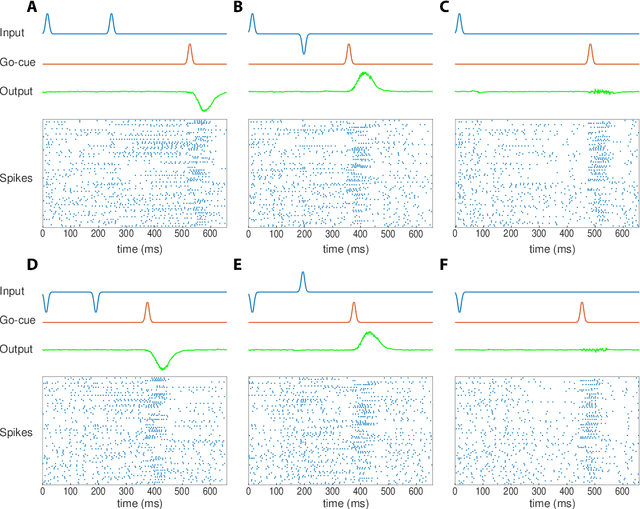
Much of studies on neural computation are based on network models of static neurons that produce analog output, despite the fact that information processing in the brain is predominantly carried out by dynamic neurons that produce discrete pulses called spikes. Research in spike-based computation has been impeded by the lack of efficient supervised learning algorithm for spiking networks. Here, we present a gradient descent method for optimizing spiking network models by introducing a differentiable formulation of spiking networks and deriving the exact gradient calculation. For demonstration, we trained recurrent spiking networks on two dynamic tasks: one that requires optimizing fast (~millisecond) spike-based interactions for efficient encoding of information, and a delayed memory XOR task over extended duration (~second). The results show that our method indeed optimizes the spiking network dynamics on the time scale of individual spikes as well as behavioral time scales. In conclusion, our result offers a general purpose supervised learning algorithm for spiking neural networks, thus advancing further investigations on spike-based computation.
The Wilson Machine for Image Modeling
Nov 11, 2015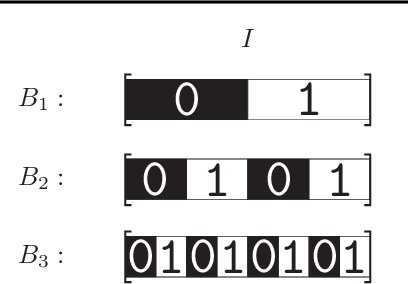


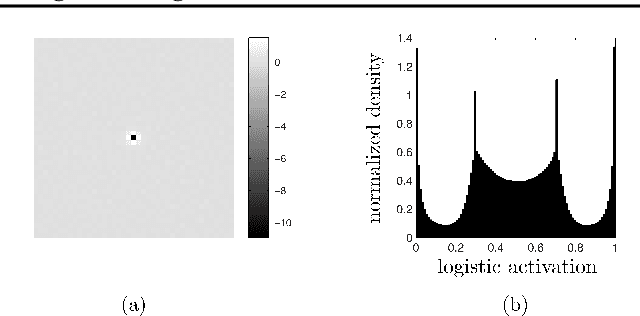
Learning the distribution of natural images is one of the hardest and most important problems in machine learning. The problem remains open, because the enormous complexity of the structures in natural images spans all length scales. We break down the complexity of the problem and show that the hierarchy of structures in natural images fuels a new class of learning algorithms based on the theory of critical phenomena and stochastic processes. We approach this problem from the perspective of the theory of critical phenomena, which was developed in condensed matter physics to address problems with infinite length-scale fluctuations, and build a framework to integrate the criticality of natural images into a learning algorithm. The problem is broken down by mapping images into a hierarchy of binary images, called bitplanes. In this representation, the top bitplane is critical, having fluctuations in structures over a vast range of scales. The bitplanes below go through a gradual stochastic heating process to disorder. We turn this representation into a directed probabilistic graphical model, transforming the learning problem into the unsupervised learning of the distribution of the critical bitplane and the supervised learning of the conditional distributions for the remaining bitplanes. We learnt the conditional distributions by logistic regression in a convolutional architecture. Conditioned on the critical binary image, this simple architecture can generate large, natural-looking images, with many shades of gray, without the use of hidden units, unprecedented in the studies of natural images. The framework presented here is a major step in bringing criticality and stochastic processes to machine learning and in studying natural image statistics.