 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden Traveling Waves bind Working Memory Variables in Recurrent Neural Networks
Feb 17, 2024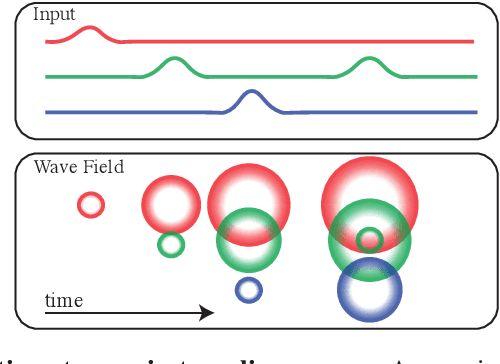
Traveling waves are a fundamental phenomenon in the brain, playing a crucial role in short-term information storage. In this study, we leverage the concept of traveling wave dynamics within a neural lattice to formulate a theoretical model of neural working memory, study its properties, and its real world implications in AI. The proposed model diverges from traditional approaches, which assume information storage in static, register-like locations updated by interference. Instead, the model stores data as waves that is updated by the wave's boundary conditions. We rigorously examine the model's capabilities in representing and learning state histories, which are vital for learning history-dependent dynamical systems. The findings reveal that the model reliably stores external information and enhances the learning process by addressing the diminishing gradient problem. To understand the model's real-world applicability, we explore two cases: linear boundary condition and non-linear, self-attention-driven boundary condition. The experiments reveal that the linear scenario is effectively learned by Recurrent Neural Networks (RNNs) through backpropagation when modeling history-dependent dynamical systems. Conversely, the non-linear scenario parallels the autoregressive loop of an attention-only transformer. Collectively, our findings suggest the broader relevance of traveling waves in AI and its potential in advancing neural network architectures.
Episodic Memory Theory for the Mechanistic Interpretation of Recurrent Neural Networks
Oct 03, 2023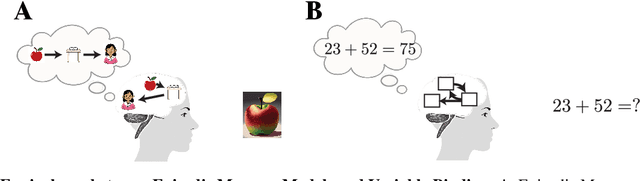
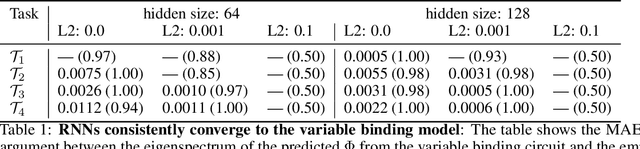
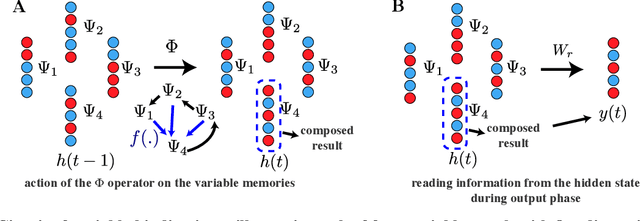
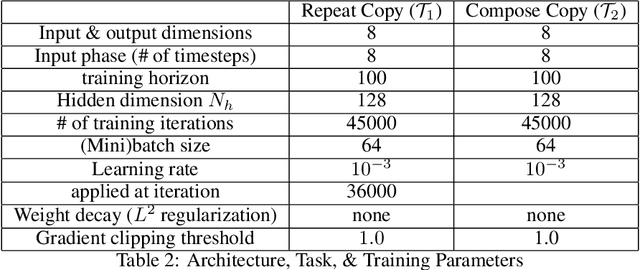
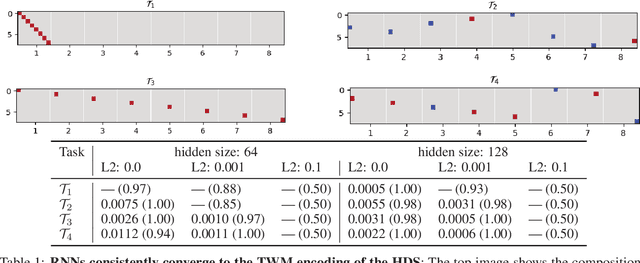
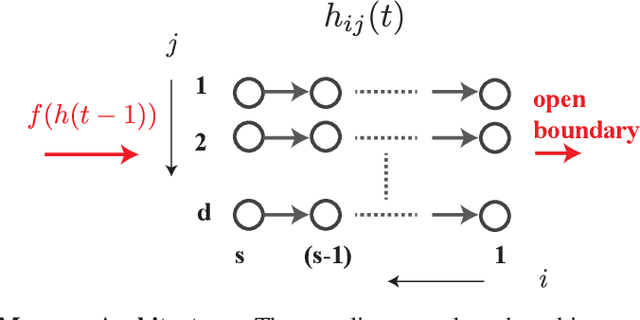
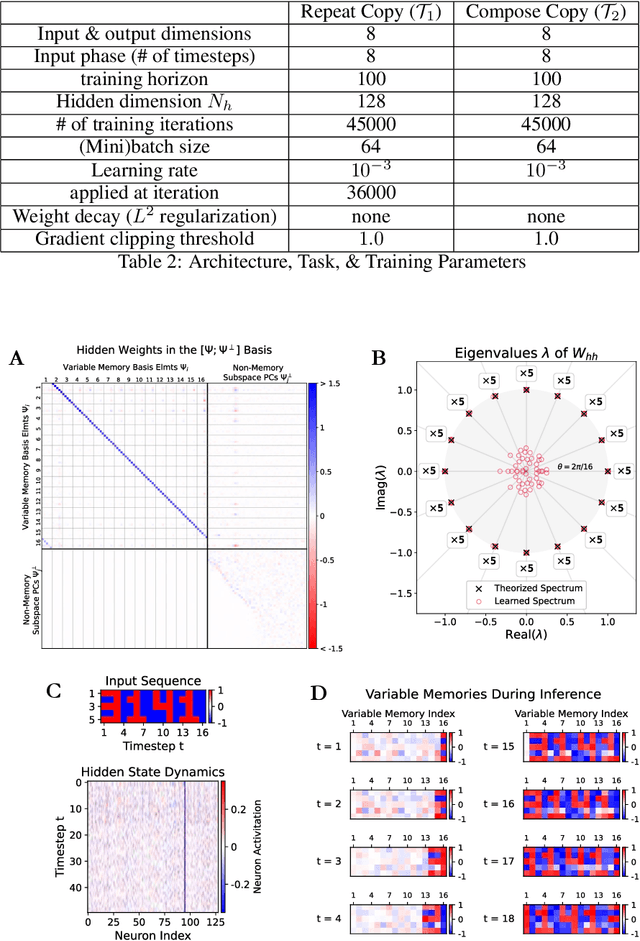
Understanding the intricate operations of Recurrent Neural Networks (RNNs) mechanistically is pivotal for advancing their capabilities and applications. In this pursuit, we propose the Episodic Memory Theory (EMT), illustrating that RNNs can be conceptualized as discrete-time analogs of the recently proposed General Sequential Episodic Memory Model. To substantiate EMT, we introduce a novel set of algorithmic tasks tailored to probe the variable binding behavior in RNNs. Utilizing the EMT, we formulate a mathematically rigorous circuit that facilitates variable binding in these tasks. Our empirical investigations reveal that trained RNNs consistently converge to the variable binding circuit, thus indicating universality in the dynamics of RNNs. Building on these findings, we devise an algorithm to define a privileged basis, which reveals hidden neurons instrumental in the temporal storage and composition of variables, a mechanism vital for the successful generalization in these tasks. We show that the privileged basis enhances the interpretability of the learned parameters and hidden states of RNNs. Our work represents a step toward demystifying the internal mechanisms of RNNs and, for computational neuroscience, serves to bridge the gap between artificial neural networks and neural memory models.
On the Dynamics of Learning Time-Aware Behavior with Recurrent Neural Networks
Jun 12, 2023Recurrent Neural Networks (RNNs) have shown great success in modeling time-dependent patterns, but there is limited research on their learned representations of latent temporal features and the emergence of these representations during training. To address this gap, we use timed automata (TA) to introduce a family of supervised learning tasks modeling behavior dependent on hidden temporal variables whose complexity is directly controllable. Building upon past studies from the perspective of dynamical systems, we train RNNs to emulate temporal flipflops, a new collection of TA that emphasizes the need for time-awareness over long-term memory. We find that these RNNs learn in phases: they quickly perfect any time-independent behavior, but they initially struggle to discover the hidden time-dependent features. In the case of periodic "time-of-day" aware automata, we show that the RNNs learn to switch between periodic orbits that encode time modulo the period of the transition rules. We subsequently apply fixed point stability analysis to monitor changes in the RNN dynamics during training, and we observe that the learning phases are separated by a bifurcation from which the periodic behavior emerges. In this way, we demonstrate how dynamical systems theory can provide insights into not only the learned representations of these models, but also the dynamics of the learning process itself. We argue that this style of analysis may provide insights into the training pathologies of recurrent architectures in contexts outside of time-awareness.
Energy-based General Sequential Episodic Memory Networks at the Adiabatic Limit
Dec 11, 2022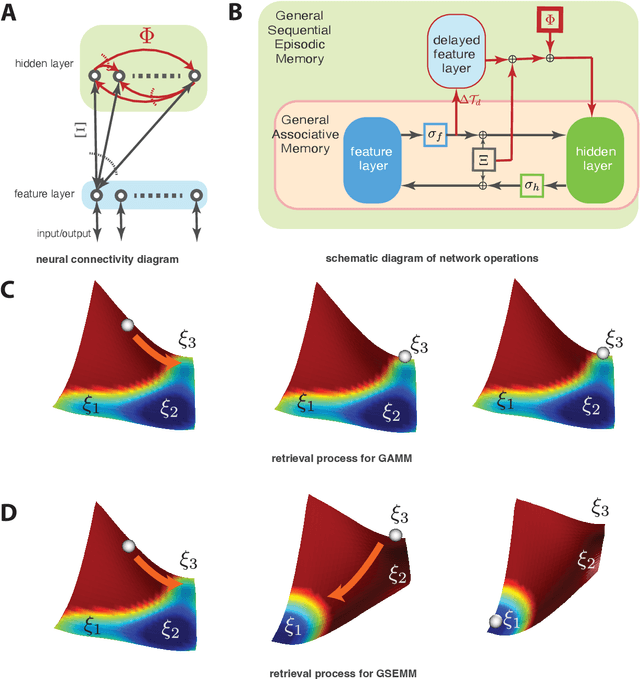
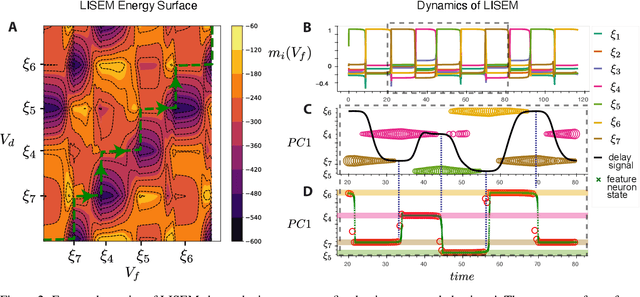
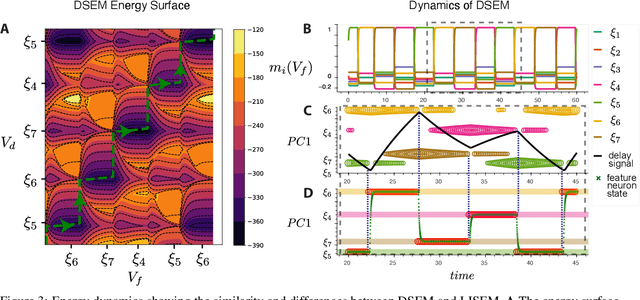
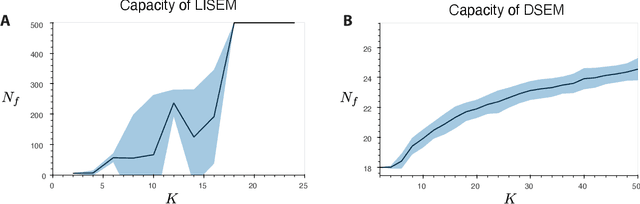
The General Associative Memory Model (GAMM) has a constant state-dependant energy surface that leads the output dynamics to fixed points, retrieving single memories from a collection of memories that can be asynchronously preloaded. We introduce a new class of General Sequential Episodic Memory Models (GSEMM) that, in the adiabatic limit, exhibit temporally changing energy surface, leading to a series of meta-stable states that are sequential episodic memories. The dynamic energy surface is enabled by newly introduced asymmetric synapses with signal propagation delays in the network's hidden layer. We study the theoretical and empirical properties of two memory models from the GSEMM class, differing in their activation functions. LISEM has non-linearities in the feature layer, whereas DSEM has non-linearity in the hidden layer. In principle, DSEM has a storage capacity that grows exponentially with the number of neurons in the network. We introduce a learning rule for the synapses based on the energy minimization principle and show it can learn single memories and their sequential relationships online. This rule is similar to the Hebbian learning algorithm and Spike-Timing Dependent Plasticity (STDP), which describe conditions under which synapses between neurons change strength. Thus, GSEMM combines the static and dynamic properties of episodic memory under a single theoretical framework and bridges neuroscience, machine learning, and artificial intelligence.
Forward Signal Propagation Learning
Apr 04, 2022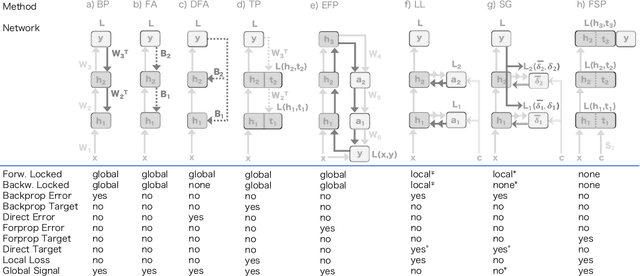
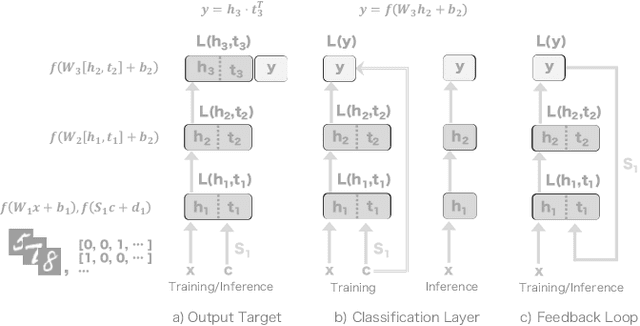
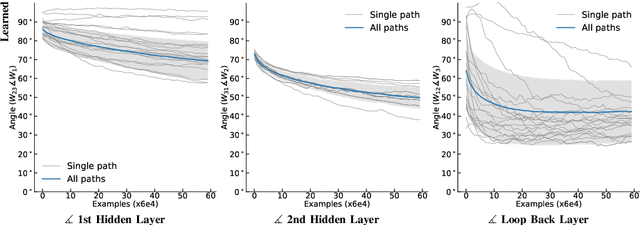
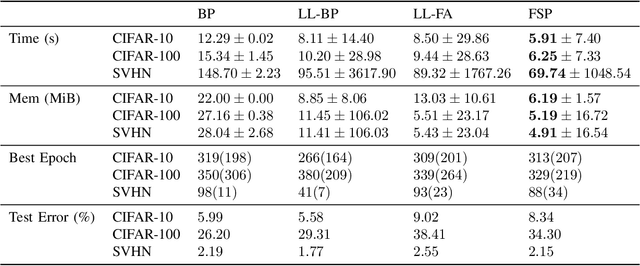
We propose a new learning algorithm for propagating a learning signal and updating neural network parameters via a forward pass, as an alternative to backpropagation. In forward signal propagation learning (sigprop), there is only the forward path for learning and inference, so there are no additional structural or computational constraints on learning, such as feedback connectivity, weight transport, or a backward pass, which exist under backpropagation. Sigprop enables global supervised learning with only a forward path. This is ideal for parallel training of layers or modules. In biology, this explains how neurons without feedback connections can still receive a global learning signal. In hardware, this provides an approach for global supervised learning without backward connectivity. Sigprop by design has better compatibility with models of learning in the brain and in hardware than backpropagation and alternative approaches to relaxing learning constraints. We also demonstrate that sigprop is more efficient in time and memory than they are. To further explain the behavior of sigprop, we provide evidence that sigprop provides useful learning signals in context to backpropagation. To further support relevance to biological and hardware learning, we use sigprop to train continuous time neural networks with Hebbian updates and train spiking neural networks without surrogate functions.
Replay in Deep Learning: Current Approaches and Missing Biological Elements
Apr 01, 2021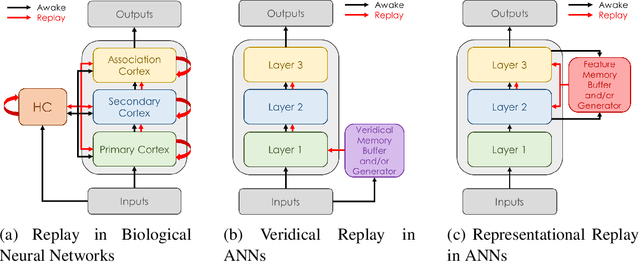
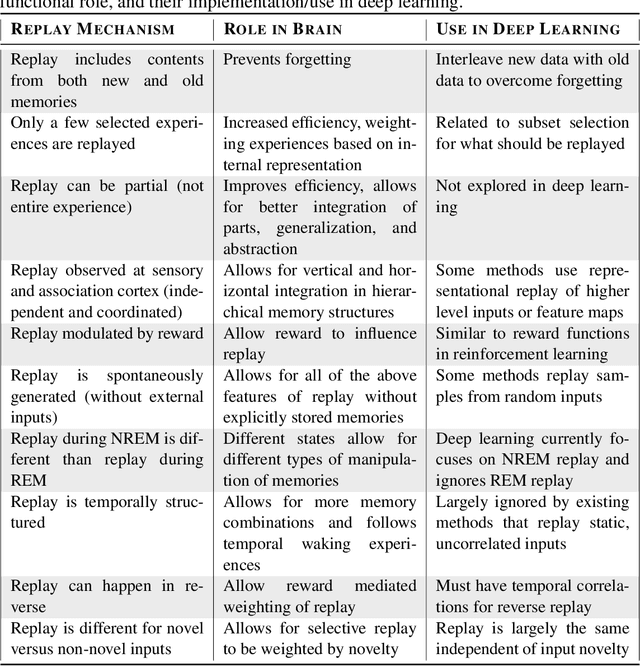
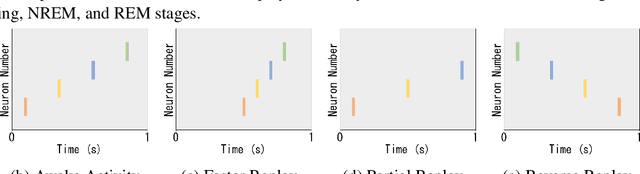
Replay is the reactivation of one or more neural patterns, which are similar to the activation patterns experienced during past waking experiences. Replay was first observed in biological neural networks during sleep, and it is now thought to play a critical role in memory formation, retrieval, and consolidation. Replay-like mechanisms have been incorporated into deep artificial neural networks that learn over time to avoid catastrophic forgetting of previous knowledge. Replay algorithms have been successfully used in a wide range of deep learning methods within supervised, unsupervised, and reinforcement learning paradigms. In this paper, we provide the first comprehensive comparison between replay in the mammalian brain and replay in artificial neural networks. We identify multiple aspects of biological replay that are missing in deep learning systems and hypothesize how they could be utilized to improve artificial neural networks.
Minibatch Processing in Spiking Neural Networks
Sep 05, 2019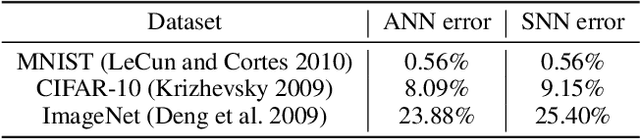
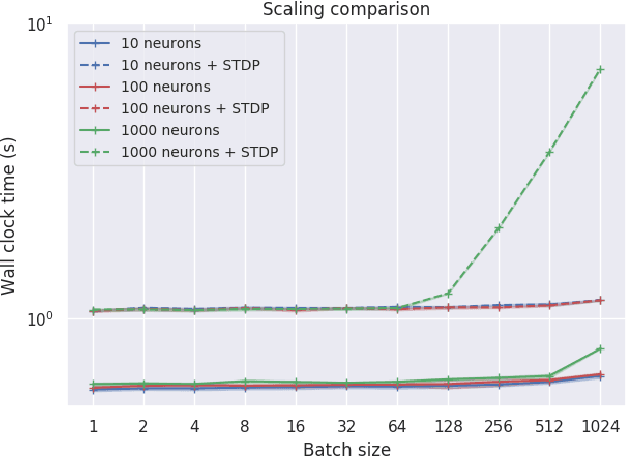

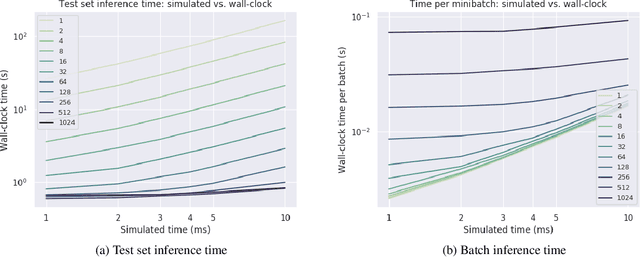
Spiking neural networks (SNNs) are a promising candidate for biologically-inspired and energy efficient computation. However, their simulation is notoriously time consuming, and may be seen as a bottleneck in developing competitive training methods with potential deployment on neuromorphic hardware platforms. To address this issue, we provide an implementation of mini-batch processing applied to clock-based SNN simulation, leading to drastically increased data throughput. To our knowledge, this is the first general-purpose implementation of mini-batch processing in a spiking neural networks simulator, which works with arbitrary neuron and synapse models. We demonstrate nearly constant-time scaling with batch size on a simulation setup (up to GPU memory limits), and showcase the effectiveness of large batch sizes in two SNN application domains, resulting in $\approx$880X and $\approx$24X reductions in wall-clock time respectively. Different parameter reduction techniques are shown to produce different learning outcomes in a simulation of networks trained with spike-timing-dependent plasticity. Machine learning practitioners and biological modelers alike may benefit from the drastically reduced simulation time and increased iteration speed this method enables. Code to reproduce the benchmarks and experimental findings in this paper can be found at https://github.com/djsaunde/snn-minibatch.
Locally Connected Spiking Neural Networks for Unsupervised Feature Learning
Apr 12, 2019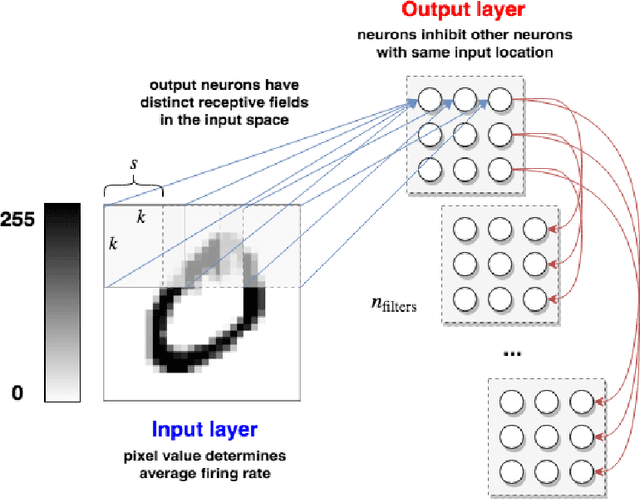
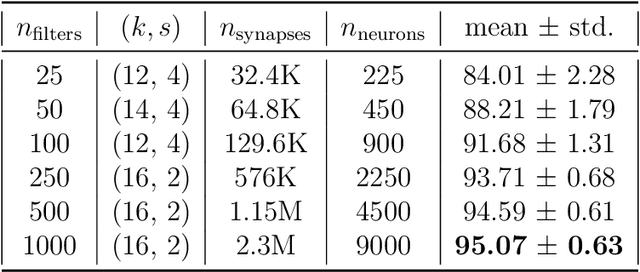
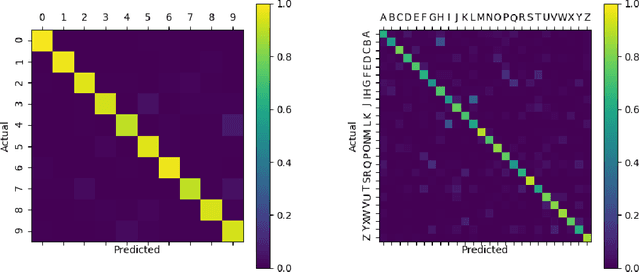
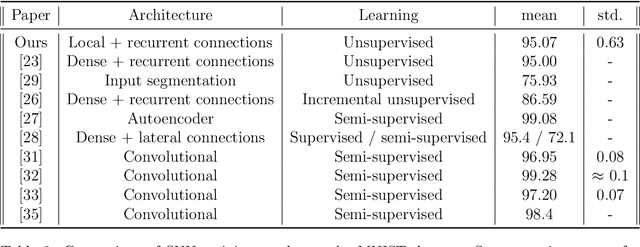
In recent years, Spiking Neural Networks (SNNs) have demonstrated great successes in completing various Machine Learning tasks. We introduce a method for learning image features by \textit{locally connected layers} in SNNs using spike-timing-dependent plasticity (STDP) rule. In our approach, sub-networks compete via competitive inhibitory interactions to learn features from different locations of the input space. These \textit{Locally-Connected SNNs} (LC-SNNs) manifest key topological features of the spatial interaction of biological neurons. We explore biologically inspired n-gram classification approach allowing parallel processing over various patches of the the image space. We report the classification accuracy of simple two-layer LC-SNNs on two image datasets, which match the state-of-art performance and are the first results to date. LC-SNNs have the advantage of fast convergence to a dataset representation, and they require fewer learnable parameters than other SNN approaches with unsupervised learning. Robustness tests demonstrate that LC-SNNs exhibit graceful degradation of performance despite the random deletion of large amounts of synapses and neurons.
STDP Learning of Image Patches with Convolutional Spiking Neural Networks
Aug 24, 2018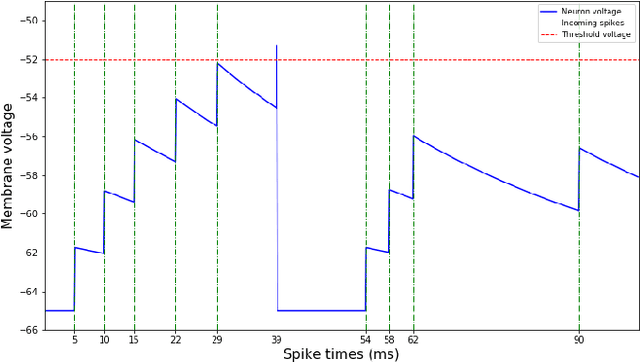
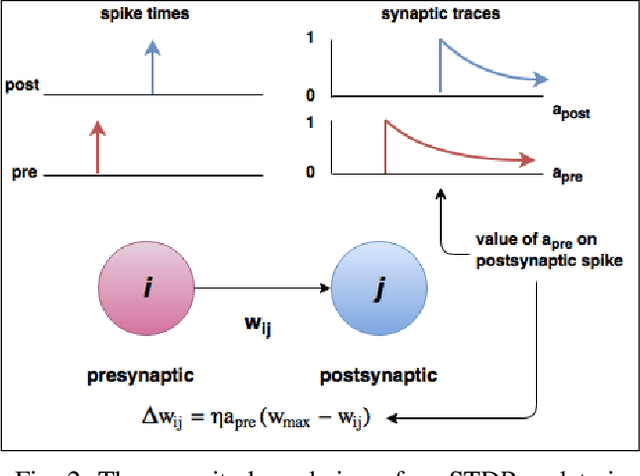
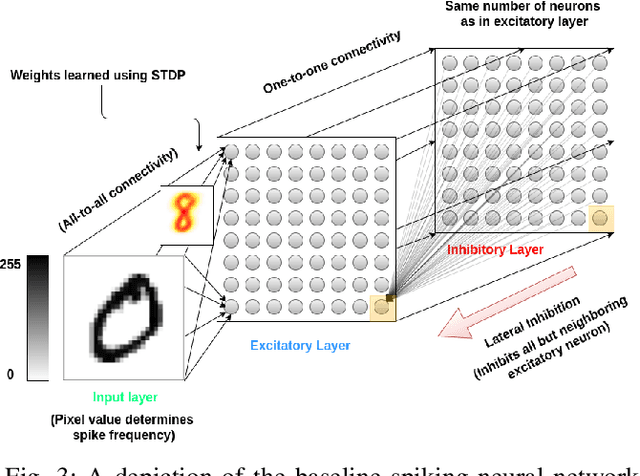
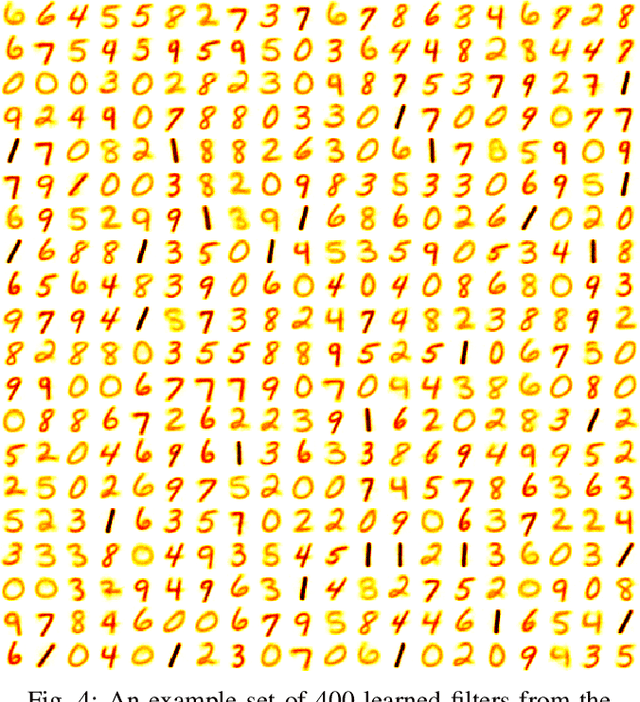
Spiking neural networks are motivated from principles of neural systems and may possess unexplored advantages in the context of machine learning. A class of \textit{convolutional spiking neural networks} is introduced, trained to detect image features with an unsupervised, competitive learning mechanism. Image features can be shared within subpopulations of neurons, or each may evolve independently to capture different features in different regions of input space. We analyze the time and memory requirements of learning with and operating such networks. The MNIST dataset is used as an experimental testbed, and comparisons are made between the performance and convergence speed of a baseline spiking neural network.
Error Forward-Propagation: Reusing Feedforward Connections to Propagate Errors in Deep Learning
Aug 09, 2018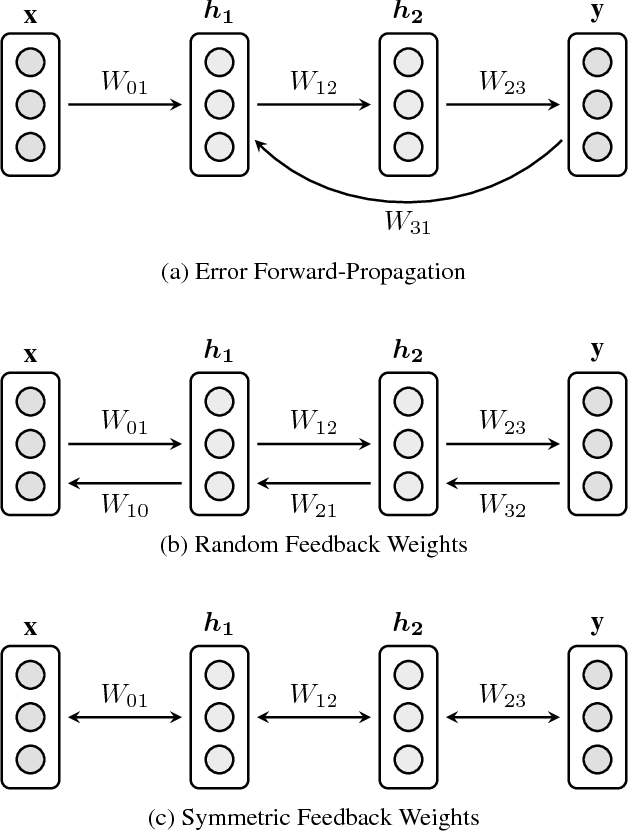

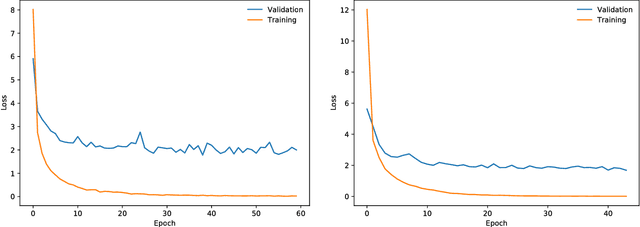
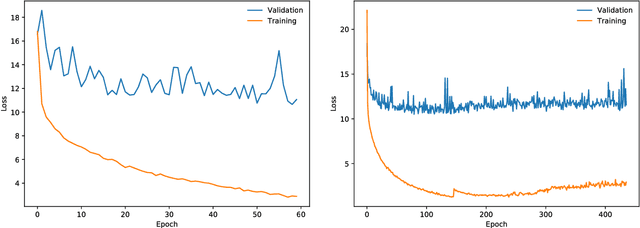
We introduce Error Forward-Propagation, a biologically plausible mechanism to propagate error feedback forward through the network. Architectural constraints on connectivity are virtually eliminated for error feedback in the brain; systematic backward connectivity is not used or needed to deliver error feedback. Feedback as a means of assigning credit to neurons earlier in the forward pathway for their contribution to the final output is thought to be used in learning in the brain. How the brain solves the credit assignment problem is unclear. In machine learning, error backpropagation is a highly successful mechanism for credit assignment in deep multilayered networks. Backpropagation requires symmetric reciprocal connectivity for every neuron. From a biological perspective, there is no evidence of such an architectural constraint, which makes backpropagation implausible for learning in the brain. This architectural constraint is reduced with the use of random feedback weights. Models using random feedback weights require backward connectivity patterns for every neuron, but avoid symmetric weights and reciprocal connections. In this paper, we practically remove this architectural constraint, requiring only a backward loop connection for effective error feedback. We propose reusing the forward connections to deliver the error feedback by feeding the outputs into the input receiving layer. This mechanism, Error Forward-Propagation, is a plausible basis for how error feedback occurs deep in the brain independent of and yet in support of the functionality underlying intricate network architectures. We show experimentally that recurrent neural networks with two and three hidden layers can be trained using Error Forward-Propagation on the MNIST and Fashion MNIST datasets, achieving $1.90\%$ and $11\%$ generalization errors respectively.