 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabits: Layered Bidirectional Time Surfaces Representation for Event Camera-based Continuous Dense Trajectory Estimation
Dec 12, 2024



Event cameras provide a compelling alternative to traditional frame-based sensors, capturing dynamic scenes with high temporal resolution and low latency. Moving objects trigger events with precise timestamps along their trajectory, enabling smooth continuous-time estimation. However, few works have attempted to optimize the information loss during event representation construction, imposing a ceiling on this task. Fully exploiting event cameras requires representations that simultaneously preserve fine-grained temporal information, stable and characteristic 2D visual features, and temporally consistent information density, an unmet challenge in existing representations. We introduce Labits: Layered Bidirectional Time Surfaces, a simple yet elegant representation designed to retain all these features. Additionally, we propose a dedicated module for extracting active pixel local optical flow (APLOF), significantly boosting the performance. Our approach achieves an impressive 49% reduction in trajectory end-point error (TEPE) compared to the previous state-of-the-art on the MultiFlow dataset. The code will be released upon acceptance.
Predicting Quality of Video Gaming Experience Using Global-Scale Telemetry Data and Federated Learning
Dec 12, 2024Frames Per Second (FPS) significantly affects the gaming experience. Providing players with accurate FPS estimates prior to purchase benefits both players and game developers. However, we have a limited understanding of how to predict a game's FPS performance on a specific device. In this paper, we first conduct a comprehensive analysis of a wide range of factors that may affect game FPS on a global-scale dataset to identify the determinants of FPS. This includes player-side and game-side characteristics, as well as country-level socio-economic statistics. Furthermore, recognizing that accurate FPS predictions require extensive user data, which raises privacy concerns, we propose a federated learning-based model to ensure user privacy. Each player and game is assigned a unique learnable knowledge kernel that gradually extracts latent features for improved accuracy. We also introduce a novel training and prediction scheme that allows these kernels to be dynamically plug-and-play, effectively addressing cold start issues. To train this model with minimal bias, we collected a large telemetry dataset from 224 countries and regions, 100,000 users, and 835 games. Our model achieved a mean Wasserstein distance of 0.469 between predicted and ground truth FPS distributions, outperforming all baseline methods.
Spike-based Neuromorphic Computing for Next-Generation Computer Vision
Oct 15, 2023Neuromorphic Computing promises orders of magnitude improvement in energy efficiency compared to traditional von Neumann computing paradigm. The goal is to develop an adaptive, fault-tolerant, low-footprint, fast, low-energy intelligent system by learning and emulating brain functionality which can be realized through innovation in different abstraction layers including material, device, circuit, architecture and algorithm. As the energy consumption in complex vision tasks keep increasing exponentially due to larger data set and resource-constrained edge devices become increasingly ubiquitous, spike-based neuromorphic computing approaches can be viable alternative to deep convolutional neural network that is dominating the vision field today. In this book chapter, we introduce neuromorphic computing, outline a few representative examples from different layers of the design stack (devices, circuits and algorithms) and conclude with a few exciting applications and future research directions that seem promising for computer vision in the near future.
"Reading Between the Heat": Co-Teaching Body Thermal Signatures for Non-intrusive Stress Detection
Oct 15, 2023Stress impacts our physical and mental health as well as our social life. A passive and contactless indoor stress monitoring system can unlock numerous important applications such as workplace productivity assessment, smart homes, and personalized mental health monitoring. While the thermal signatures from a user's body captured by a thermal camera can provide important information about the "fight-flight" response of the sympathetic and parasympathetic nervous system, relying solely on thermal imaging for training a stress prediction model often lead to overfitting and consequently a suboptimal performance. This paper addresses this challenge by introducing ThermaStrain, a novel co-teaching framework that achieves high-stress prediction performance by transferring knowledge from the wearable modality to the contactless thermal modality. During training, ThermaStrain incorporates a wearable electrodermal activity (EDA) sensor to generate stress-indicative representations from thermal videos, emulating stress-indicative representations from a wearable EDA sensor. During testing, only thermal sensing is used, and stress-indicative patterns from thermal data and emulated EDA representations are extracted to improve stress assessment. The study collected a comprehensive dataset with thermal video and EDA data under various stress conditions and distances. ThermaStrain achieves an F1 score of 0.8293 in binary stress classification, outperforming the thermal-only baseline approach by over 9%. Extensive evaluations highlight ThermaStrain's effectiveness in recognizing stress-indicative attributes, its adaptability across distances and stress scenarios, real-time executability on edge platforms, its applicability to multi-individual sensing, ability to function on limited visibility and unfamiliar conditions, and the advantages of its co-teaching approach.
V2CE: Video to Continuous Events Simulator
Sep 16, 2023



Dynamic Vision Sensor (DVS)-based solutions have recently garnered significant interest across various computer vision tasks, offering notable benefits in terms of dynamic range, temporal resolution, and inference speed. However, as a relatively nascent vision sensor compared to Active Pixel Sensor (APS) devices such as RGB cameras, DVS suffers from a dearth of ample labeled datasets. Prior efforts to convert APS data into events often grapple with issues such as a considerable domain shift from real events, the absence of quantified validation, and layering problems within the time axis. In this paper, we present a novel method for video-to-events stream conversion from multiple perspectives, considering the specific characteristics of DVS. A series of carefully designed losses helps enhance the quality of generated event voxels significantly. We also propose a novel local dynamic-aware timestamp inference strategy to accurately recover event timestamps from event voxels in a continuous fashion and eliminate the temporal layering problem. Results from rigorous validation through quantified metrics at all stages of the pipeline establish our method unquestionably as the current state-of-the-art (SOTA).
YeLan: Event Camera-Based 3D Human Pose Estimation for Technology-Mediated Dancing in Challenging Environments with Comprehensive Motion-to-Event Simulator
Jan 17, 2023As a beloved sport worldwide, dancing is getting integrated into traditional and virtual reality-based gaming platforms nowadays. It opens up new opportunities in the technology-mediated dancing space. These platforms primarily rely on passive and continuous human pose estimation as an input capture mechanism. Existing solutions are mainly based on RGB or RGB-Depth cameras for dance games. The former suffers in low-lighting conditions due to the motion blur and low sensitivity, while the latter is too power-hungry, has a low frame rate, and has limited working distance. With ultra-low latency, energy efficiency, and wide dynamic range characteristics, the event camera is a promising solution to overcome these shortcomings. We propose YeLan, an event camera-based 3-dimensional human pose estimation(HPE) system that survives low-lighting and dynamic background contents. We collected the world's first event camera dance dataset and developed a fully customizable motion-to-event physics-aware simulator. YeLan outperforms the baseline models in these challenging conditions and demonstrated robustness against different types of clothing, background motion, viewing angle, occlusion, and lighting fluctuations.
Hyperspectral Image Super-Resolution in Arbitrary Input-Output Band Settings
Mar 19, 2021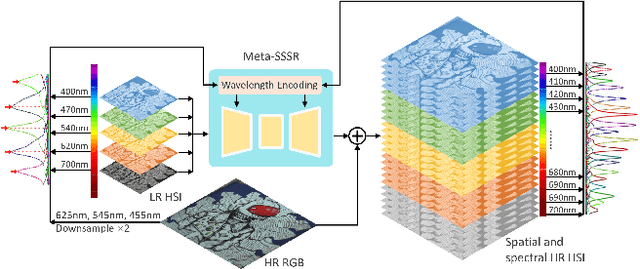
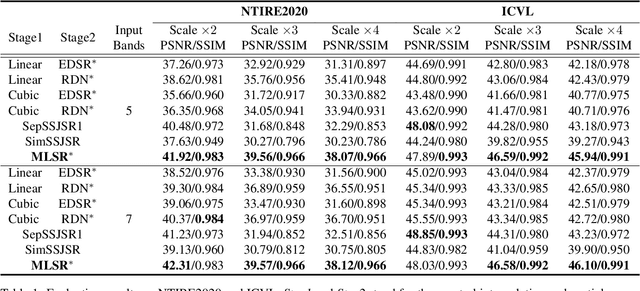


Hyperspectral images (HSIs) with narrow spectral bands can capture rich spectral information, making them suitable for many computer vision tasks. One of the fundamental limitations of HSI is its low spatial resolution, and several recent works on super-resolution(SR) have been proposed to tackle this challenge. However, due to HSI cameras' diversity, different cameras capture images with different spectral response functions and the number of total channels. The existing HSI datasets are usually small and consequently insufficient for modeling. We propose a Meta-Learning-Based Super-Resolution(MLSR) model, which can take in HSI images at an arbitrary number of input bands' peak wavelengths and generate super-resolved HSIs with an arbitrary number of output bands' peak wavelengths. We artificially create sub-datasets by sampling the bands from NTIRE2020 and ICVL datasets to simulate the cross-dataset settings and perform HSI SR with spectral interpolation and extrapolation on them. We train a single MLSR model for all sub-datasets and train dedicated baseline models for each sub-dataset. The results show the proposed model has the same level or better performance compared to the-state-of-the-art HSI SR methods.
Solving Poisson's Equation using Deep Learning in Particle Simulation of PN Junction
Oct 25, 2018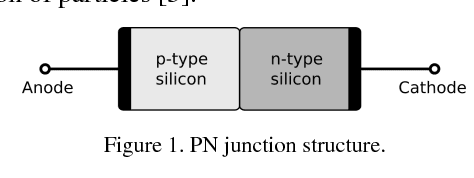
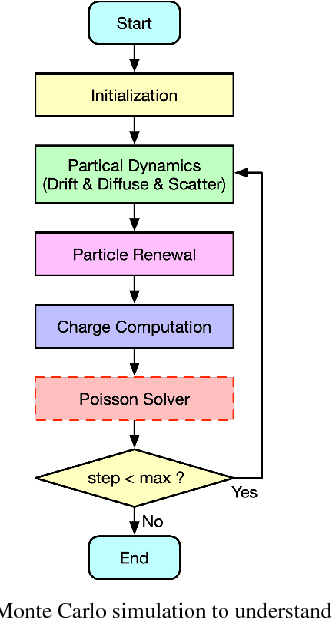
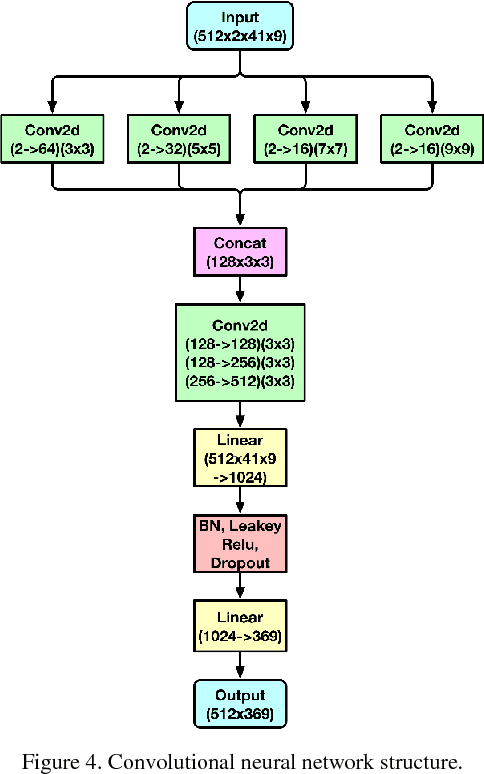
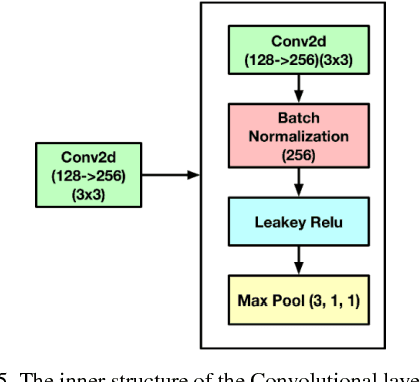
Simulating the dynamic characteristics of a PN junction at the microscopic level requires solving the Poisson's equation at every time step. Solving at every time step is a necessary but time-consuming process when using the traditional finite difference (FDM) approach. Deep learning is a powerful technique to fit complex functions. In this work, deep learning is utilized to accelerate solving Poisson's equation in a PN junction. The role of the boundary condition is emphasized in the loss function to ensure a better fitting. The resulting I-V curve for the PN junction, using the deep learning solver presented in this work, shows a perfect match to the I-V curve obtained using the finite difference method, with the advantage of being 10 times faster at every time step.