 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEthical Fairness without Demographics in Human-Centered AI
Mar 17, 2026Computational models are increasingly embedded in human-centered domains such as healthcare, education, workplace analytics, and digital well-being, where their predictions directly influence individual outcomes and collective welfare. In such contexts, achieving high accuracy alone is insufficient; models must also act ethically and equitably across diverse populations. However, fair AI approaches that rely on demographic attributes are impractical, as such information is often unavailable, privacy-sensitive, or restricted by regulatory frameworks. Moreover, conventional parity-based fairness approaches, while aiming for equity, can inadvertently violate core ethical principles by trading off subgroup performance or stability. To address this challenge, we present Flare (Fisher-guided LAtent-subgroup learning with do-no-harm REgularization), the first demographic-agnostic framework that aligns algorithmic fairness with ethical principles through the geometry of optimization. Flare leverages Fisher Information to regularize curvature, uncovering latent disparities in model behavior without access to demographic or sensitive attributes. By integrating representation, loss, and curvature signals, it identifies hidden performance strata and adaptively refines them through collaborative but do-no-harm optimization, enhancing each subgroup's performance while preserving global stability and ethical balance. We also introduce BHE (Beneficence-Harm Avoidance-Equity), a novel metric suite that operationalizes ethical fairness evaluation beyond statistical parity. Extensive evaluations across diverse physiological (EDA), behavioral (IHS), and clinical (OhioT1DM) datasets show that Flare consistently enhances ethical fairness compared to state-of-the-art baselines.
UnIT: Scalable Unstructured Inference-Time Pruning for MAC-efficient Neural Inference on MCUs
Jul 10, 2025Existing pruning methods are typically applied during training or compile time and often rely on structured sparsity. While compatible with low-power microcontrollers (MCUs), structured pruning underutilizes the opportunity for fine-grained efficiency on devices without SIMD support or parallel compute. To address these limitations, we introduce UnIT (Unstructured Inference-Time pruning), a lightweight method that dynamically identifies and skips unnecessary multiply-accumulate (MAC) operations during inference, guided by input-specific activation patterns. Unlike structured pruning, UnIT embraces irregular sparsity and does not require retraining or hardware specialization. It transforms pruning decisions into lightweight comparisons, replacing multiplications with threshold checks and approximated divisions. UnIT further optimizes compute by reusing threshold computations across multiple connections and applying layer- and group-specific pruning sensitivity. We present three fast, hardware-friendly division approximations tailored to the capabilities of common embedded platforms. Demonstrated on the MSP430 microcontroller, UnIT achieves 11.02% to 82.03% MAC reduction, 27.30% to 84.19% faster inference, and 27.33% to 84.38% lower energy consumption compared to training-time pruned models, while maintaining accuracy with 0.48-7%. Under domain shift, UnIT matches or exceeds the accuracy of retrained models while requiring significantly fewer MACs. These results establish unstructured inference-time pruning as a viable and practical solution for efficient, retraining-free deployment of deep neural networks on MCUs.
Toward Foundation Model for Multivariate Wearable Sensing of Physiological Signals
Dec 12, 2024



Time-series foundation models have the ability to run inference, mainly forecasting, on any type of time series data, thanks to the informative representations comprising waveform features. Wearable sensing data, on the other hand, contain more variability in both patterns and frequency bands of interest and generally emphasize more on the ability to infer healthcare-related outcomes. The main challenge of crafting a foundation model for wearable sensing physiological signals is to learn generalizable representations that support efficient adaptation across heterogeneous sensing configurations and applications. In this work, we propose NormWear, a step toward such a foundation model, aiming to extract generalized and informative wearable sensing representations. NormWear has been pretrained on a large set of physiological signals, including PPG, ECG, EEG, GSR, and IMU, from various public resources. For a holistic assessment, we perform downstream evaluation on 11 public wearable sensing datasets, spanning 18 applications in the areas of mental health, body state inference, biomarker estimations, and disease risk evaluations. We demonstrate that NormWear achieves a better performance improvement over competitive baselines in general time series foundation modeling. In addition, leveraging a novel representation-alignment-match-based method, we align physiological signals embeddings with text embeddings. This alignment enables our proposed foundation model to perform zero-shot inference, allowing it to generalize to previously unseen wearable signal-based health applications. Finally, we perform nonlinear dynamic analysis on the waveform features extracted by the model at each intermediate layer. This analysis quantifies the model's internal processes, offering clear insights into its behavior and fostering greater trust in its inferences among end users.
CRoP: Context-wise Robust Static Human-Sensing Personalization
Sep 26, 2024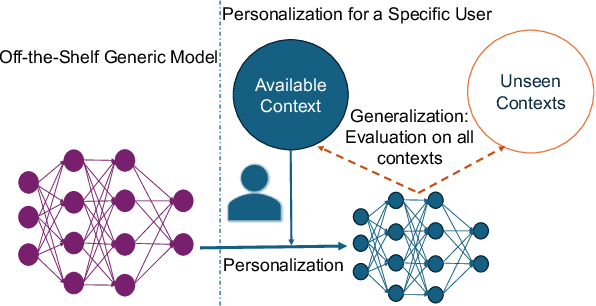
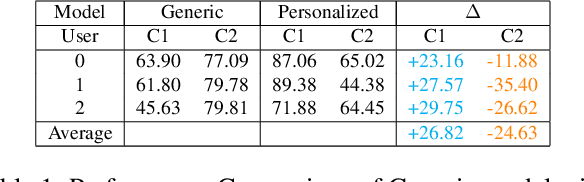
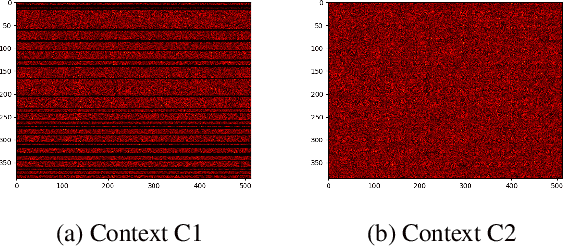

The advancement in deep learning and internet-of-things have led to diverse human sensing applications. However, distinct patterns in human sensing, influenced by various factors or contexts, challenge generic neural network model's performance due to natural distribution shifts. To address this, personalization tailors models to individual users. Yet most personalization studies overlook intra-user heterogeneity across contexts in sensory data, limiting intra-user generalizability. This limitation is especially critical in clinical applications, where limited data availability hampers both generalizability and personalization. Notably, intra-user sensing attributes are expected to change due to external factors such as treatment progression, further complicating the challenges.This work introduces CRoP, a novel static personalization approach using an off-the-shelf pre-trained model and pruning to optimize personalization and generalization. CRoP shows superior personalization effectiveness and intra-user robustness across four human-sensing datasets, including two from real-world health domains, highlighting its practical and social impact. Additionally, to support CRoP's generalization ability and design choices, we provide empirical justification through gradient inner product analysis, ablation studies, and comparisons against state-of-the-art baselines.
Only My Model On My Data: A Privacy Preserving Approach Protecting one Model and Deceiving Unauthorized Black-Box Models
Feb 14, 2024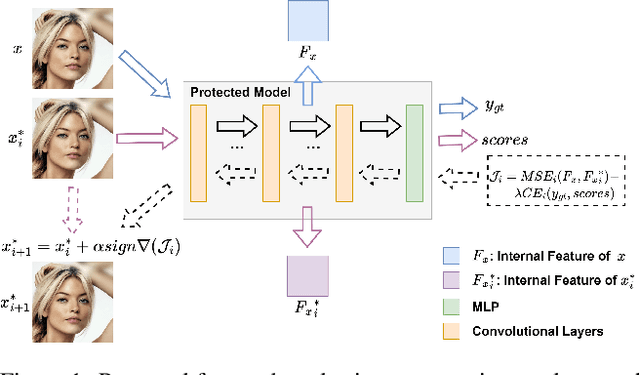
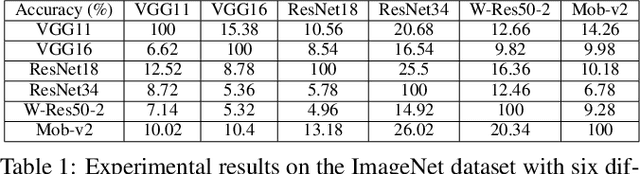
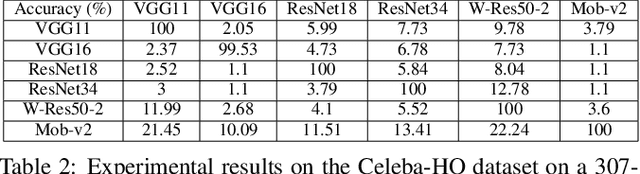

Deep neural networks are extensively applied to real-world tasks, such as face recognition and medical image classification, where privacy and data protection are critical. Image data, if not protected, can be exploited to infer personal or contextual information. Existing privacy preservation methods, like encryption, generate perturbed images that are unrecognizable to even humans. Adversarial attack approaches prohibit automated inference even for authorized stakeholders, limiting practical incentives for commercial and widespread adaptation. This pioneering study tackles an unexplored practical privacy preservation use case by generating human-perceivable images that maintain accurate inference by an authorized model while evading other unauthorized black-box models of similar or dissimilar objectives, and addresses the previous research gaps. The datasets employed are ImageNet, for image classification, Celeba-HQ dataset, for identity classification, and AffectNet, for emotion classification. Our results show that the generated images can successfully maintain the accuracy of a protected model and degrade the average accuracy of the unauthorized black-box models to 11.97%, 6.63%, and 55.51% on ImageNet, Celeba-HQ, and AffectNet datasets, respectively.
"Reading Between the Heat": Co-Teaching Body Thermal Signatures for Non-intrusive Stress Detection
Oct 15, 2023



Stress impacts our physical and mental health as well as our social life. A passive and contactless indoor stress monitoring system can unlock numerous important applications such as workplace productivity assessment, smart homes, and personalized mental health monitoring. While the thermal signatures from a user's body captured by a thermal camera can provide important information about the "fight-flight" response of the sympathetic and parasympathetic nervous system, relying solely on thermal imaging for training a stress prediction model often lead to overfitting and consequently a suboptimal performance. This paper addresses this challenge by introducing ThermaStrain, a novel co-teaching framework that achieves high-stress prediction performance by transferring knowledge from the wearable modality to the contactless thermal modality. During training, ThermaStrain incorporates a wearable electrodermal activity (EDA) sensor to generate stress-indicative representations from thermal videos, emulating stress-indicative representations from a wearable EDA sensor. During testing, only thermal sensing is used, and stress-indicative patterns from thermal data and emulated EDA representations are extracted to improve stress assessment. The study collected a comprehensive dataset with thermal video and EDA data under various stress conditions and distances. ThermaStrain achieves an F1 score of 0.8293 in binary stress classification, outperforming the thermal-only baseline approach by over 9%. Extensive evaluations highlight ThermaStrain's effectiveness in recognizing stress-indicative attributes, its adaptability across distances and stress scenarios, real-time executability on edge platforms, its applicability to multi-individual sensing, ability to function on limited visibility and unfamiliar conditions, and the advantages of its co-teaching approach.
Classifying Rhoticity of /r/ in Speech Sound Disorder using Age-and-Sex Normalized Formants
May 25, 2023



Mispronunciation detection tools could increase treatment access for speech sound disorders impacting, e.g., /r/. We show age-and-sex normalized formant estimation outperforms cepstral representation for detection of fully rhotic vs. derhotic /r/ in the PERCEPT-R Corpus. Gated recurrent neural networks trained on this feature set achieve a mean test participant-specific F1-score =.81 ({\sigma}x=.10, med = .83, n = 48), with post hoc modeling showing no significant effect of child age or sex.
SparseVLR: A Novel Framework for Verified Locally Robust Sparse Neural Networks Search
Dec 02, 2022The compute-intensive nature of neural networks (NNs) limits their deployment in resource-constrained environments such as cell phones, drones, autonomous robots, etc. Hence, developing robust sparse models fit for safety-critical applications has been an issue of longstanding interest. Though adversarial training with model sparsification has been combined to attain the goal, conventional adversarial training approaches provide no formal guarantee that the models would be robust against any rogue samples in a restricted space around a benign sample. Recently proposed verified local robustness techniques provide such a guarantee. This is the first paper that combines the ideas from verified local robustness and dynamic sparse training to develop `SparseVLR'-- a novel framework to search verified locally robust sparse networks. Obtained sparse models exhibit accuracy and robustness comparable to their dense counterparts at sparsity as high as 99%. Furthermore, unlike most conventional sparsification techniques, SparseVLR does not require a pre-trained dense model, reducing the training time by 50%. We exhaustively investigated SparseVLR's efficacy and generalizability by evaluating various benchmark and application-specific datasets across several models.
Privacy against Real-Time Speech Emotion Detection via Acoustic Adversarial Evasion of Machine Learning
Nov 17, 2022Emotional Surveillance is an emerging area with wide-reaching privacy concerns. These concerns are exacerbated by ubiquitous IoT devices with multiple sensors that can support these surveillance use cases. The work presented here considers one such use case: the use of a speech emotion recognition (SER) classifier tied to a smart speaker. This work demonstrates the ability to evade black-box SER classifiers tied to a smart speaker without compromising the utility of the smart speaker. This privacy concern is considered through the lens of adversarial evasion of machine learning. Our solution, Defeating Acoustic Recognition of Emotion via Genetic Programming (DARE-GP), uses genetic programming to generate non-invasive additive audio perturbations (AAPs). By constraining the evolution of these AAPs, transcription accuracy can be protected while simultaneously degrading SER classifier performance. The additive nature of these AAPs, along with an approach that generates these AAPs for a fixed set of users in an utterance and user location-independent manner, supports real-time, real-world evasion of SER classifiers. DARE-GP's use of spectral features, which underlay the emotional content of speech, allows the transferability of AAPs to previously unseen black-box SER classifiers. Further, DARE-GP outperforms state-of-the-art SER evasion techniques and is robust against defenses employed by a knowledgeable adversary. The evaluations in this work culminate with acoustic evaluations against two off-the-shelf commercial smart speakers, where a single AAP could evade a black box classifier over 70% of the time. The final evaluation deployed AAP playback on a small-form-factor system (raspberry pi) integrated with a wake-word system to evaluate the efficacy of a real-world, real-time deployment where DARE-GP is automatically invoked with the smart speaker's wake word.
Psychophysiology-aided Perceptually Fluent Speech Analysis of Children Who Stutter
Nov 16, 2022



This first-of-its-kind paper presents a novel approach named PASAD that detects changes in perceptually fluent speech acoustics of young children. Particularly, analysis of perceptually fluent speech enables identifying the speech-motor-control factors that are considered as the underlying cause of stuttering disfluencies. Recent studies indicate that the speech production of young children, especially those who stutter, may get adversely affected by situational physiological arousal. A major contribution of this paper is leveraging the speaker's situational physiological responses in real-time to analyze the speech signal effectively. The presented PASAD approach adapts a Hyper-Network structure to extract temporal speech importance information leveraging physiological parameters. In addition, a novel non-local acoustic spectrogram feature extraction network identifies meaningful acoustic attributes. Finally, a sequential network utilizes the acoustic attributes and the extracted temporal speech importance for effective classification. We collected speech and physiological sensing data from 73 preschool-age children who stutter (CWS) and who don't stutter (CWNS) in different conditions. PASAD's unique architecture enables visualizing speech attributes distinct to a CWS's fluent speech and mapping them to the speaker's respective speech-motor-control factors (i.e., speech articulators). Extracted knowledge can enhance understanding of children's fluent speech, speech-motor-control (SMC), and stuttering development. Our comprehensive evaluation shows that PASAD outperforms state-of-the-art multi-modal baseline approaches in different conditions, is expressive and adaptive to the speaker's speech and physiology, generalizable, robust, and is real-time executable on mobile and scalable devices.