 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of Experts based Multi-task Supervise Learning from Crowds
Jul 18, 2024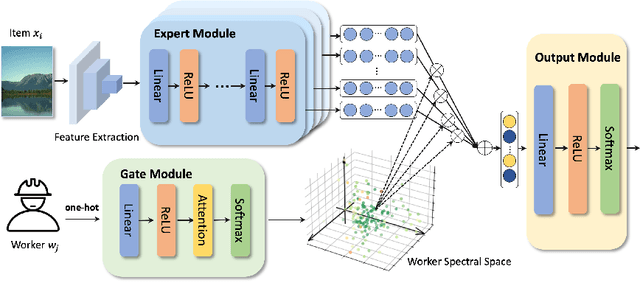
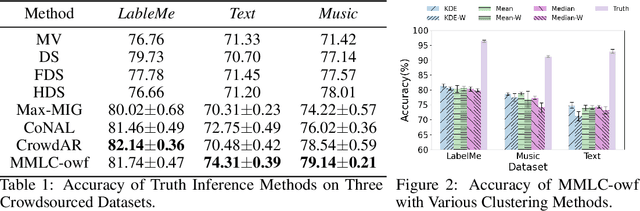
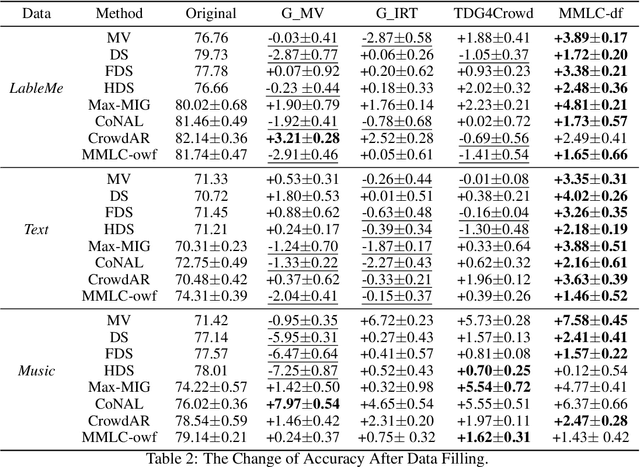
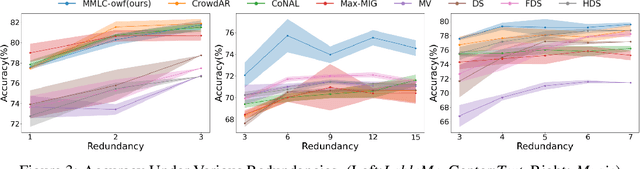
Existing truth inference methods in crowdsourcing aim to map redundant labels and items to the ground truth. They treat the ground truth as hidden variables and use statistical or deep learning-based worker behavior models to infer the ground truth. However, worker behavior models that rely on ground truth hidden variables overlook workers' behavior at the item feature level, leading to imprecise characterizations and negatively impacting the quality of truth inference. This paper proposes a new paradigm of multi-task supervised learning from crowds, which eliminates the need for modeling of items's ground truth in worker behavior models. Within this paradigm, we propose a worker behavior model at the item feature level called Mixture of Experts based Multi-task Supervised Learning from Crowds (MMLC). Two truth inference strategies are proposed within MMLC. The first strategy, named MMLC-owf, utilizes clustering methods in the worker spectral space to identify the projection vector of the oracle worker. Subsequently, the labels generated based on this vector are considered as the inferred truth. The second strategy, called MMLC-df, employs the MMLC model to fill the crowdsourced data, which can enhance the effectiveness of existing truth inference methods. Experimental results demonstrate that MMLC-owf outperforms state-of-the-art methods and MMLC-df enhances the quality of existing truth inference methods.
An Approach for Combining Multimodal Fusion and Neural Architecture Search Applied to Knowledge Tracing
Nov 08, 2021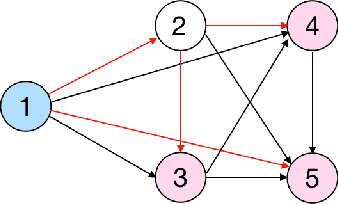
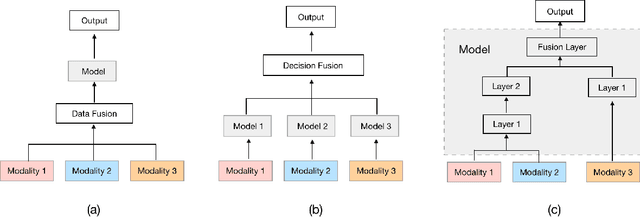
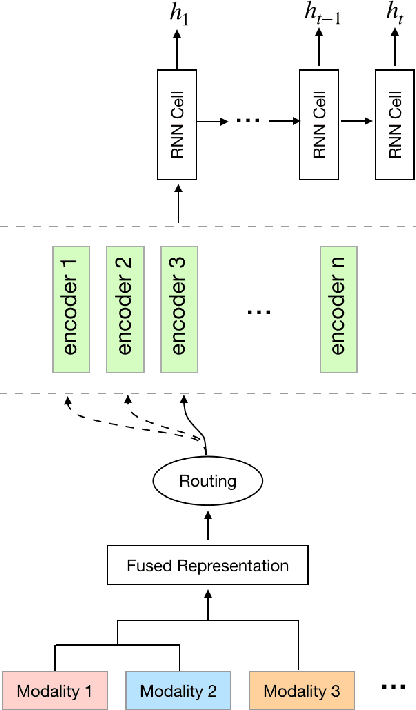
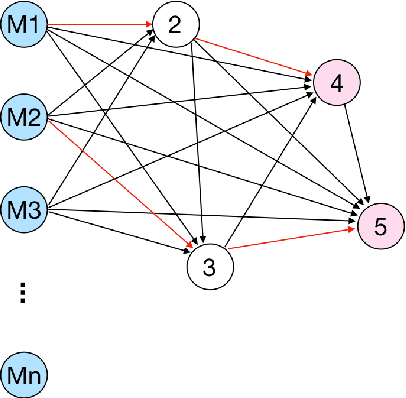
Knowledge Tracing is the process of tracking mastery level of different skills of students for a given learning domain. It is one of the key components for building adaptive learning systems and has been investigated for decades. In parallel with the success of deep neural networks in other fields, we have seen researchers take similar approaches in the learning science community. However, most existing deep learning based knowledge tracing models either: (1) only use the correct/incorrect response (ignoring useful information from other modalities) or (2) design their network architectures through domain expertise via trial and error. In this paper, we propose a sequential model based optimization approach that combines multimodal fusion and neural architecture search within one framework. The commonly used neural architecture search technique could be considered as a special case of our proposed approach when there is only one modality involved. We further propose to use a new metric called time-weighted Area Under the Curve (weighted AUC) to measure how a sequence model performs with time. We evaluate our methods on two public real datasets showing the discovered model is able to achieve superior performance. Unlike most existing works, we conduct McNemar's test on the model predictions and the results are statistically significant.
Smartphone Camera Oximetry in an Induced Hypoxemia Study
Mar 31, 2021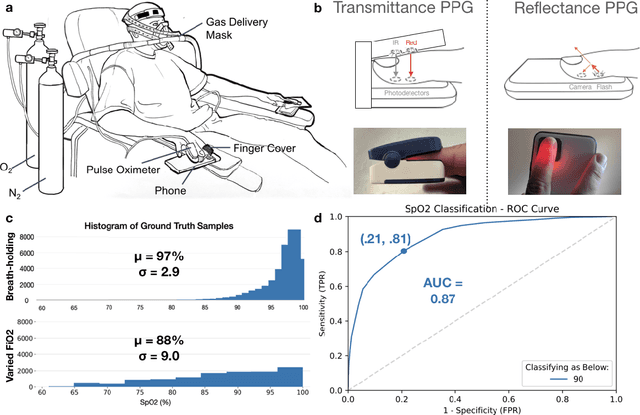
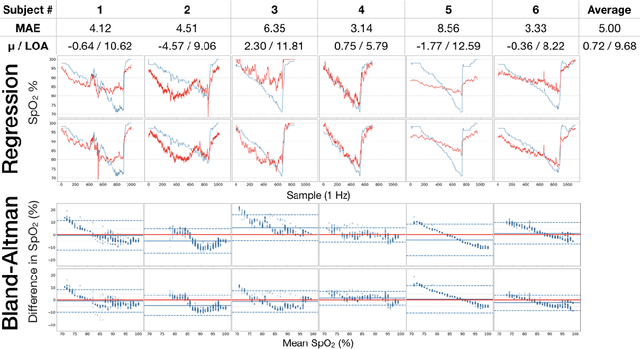
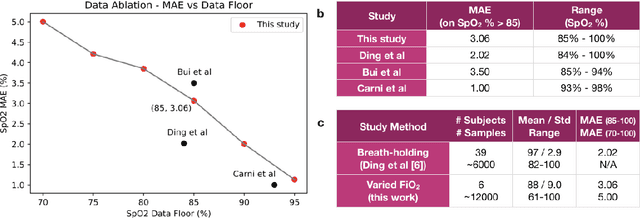
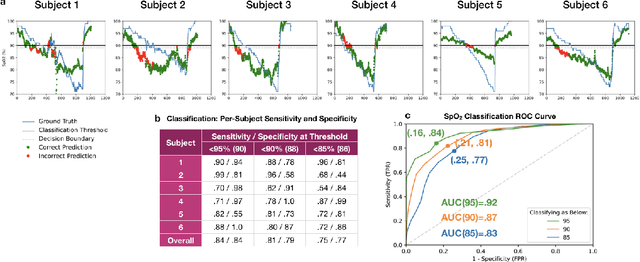
Hypoxemia, a medical condition that occurs when the blood is not carrying enough oxygen to adequately supply the tissues, is a leading indicator for dangerous complications of respiratory diseases like asthma, COPD, and COVID-19. While purpose-built pulse oximeters can provide accurate blood-oxygen saturation (SpO$_2$) readings that allow for diagnosis of hypoxemia, enabling this capability in unmodified smartphone cameras via a software update could give more people access to important information about their health, as well as improve physicians' ability to remotely diagnose and treat respiratory conditions. In this work, we take a step towards this goal by performing the first clinical development validation on a smartphone-based SpO$_2$ sensing system using a varied fraction of inspired oxygen (FiO$_2$) protocol, creating a clinically relevant validation dataset for solely smartphone-based methods on a wide range of SpO$_2$ values (70%-100%) for the first time. This contrasts with previous studies, which evaluated performance on a far smaller range (85%-100%). We build a deep learning model using this data to demonstrate accurate reporting of SpO$_2$ level with an overall MAE=5.00% SpO$_2$ and identifying positive cases of low SpO$_2$<90% with 81% sensitivity and 79% specificity. We ground our analysis with a summary of recent literature in smartphone-based SpO2 monitoring, and we provide the data from the FiO$_2$ study in open-source format, so that others may build on this work.
On the Interpretability of Deep Learning Based Models for Knowledge Tracing
Jan 27, 2021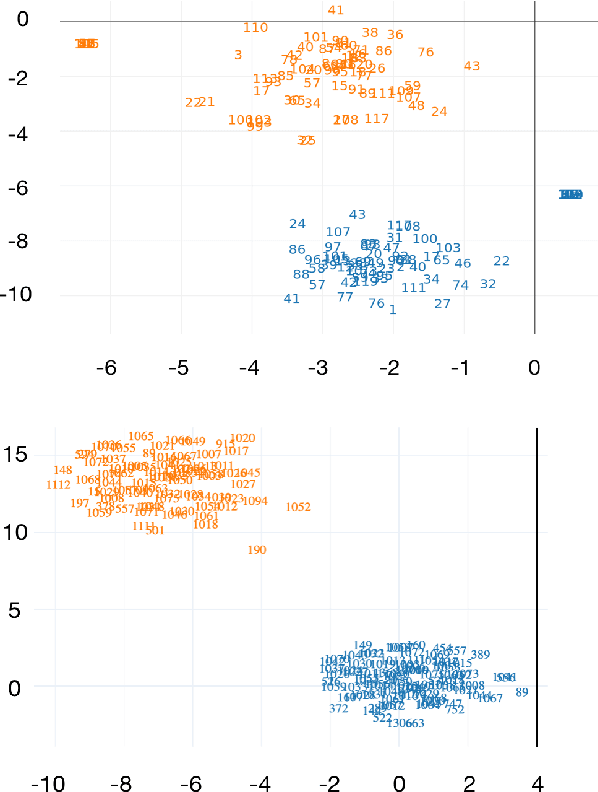
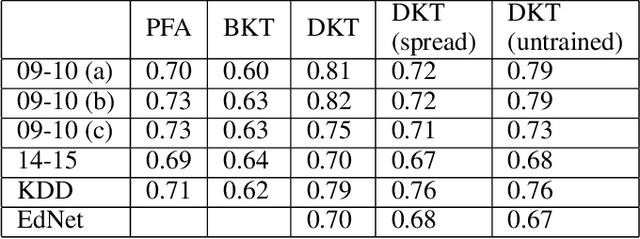
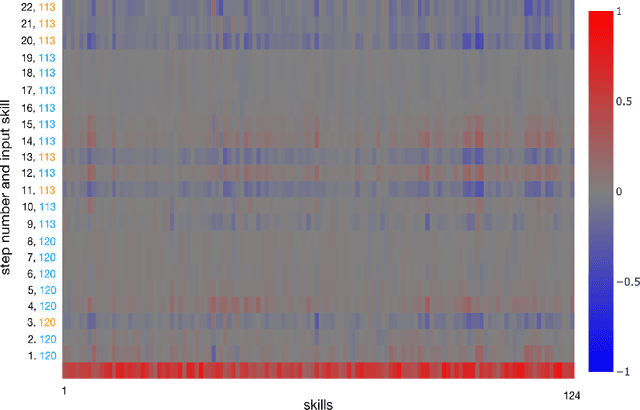
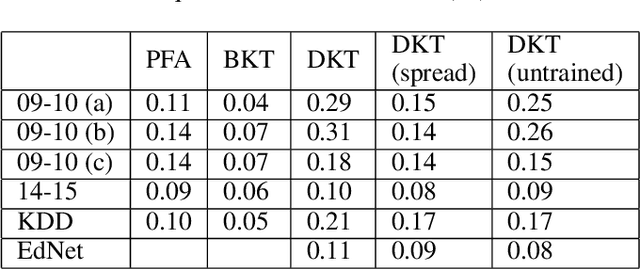
Knowledge tracing allows Intelligent Tutoring Systems to infer which topics or skills a student has mastered, thus adjusting curriculum accordingly. Deep Learning based models like Deep Knowledge Tracing (DKT) and Dynamic Key-Value Memory Network (DKVMN) have achieved significant improvements compared with models like Bayesian Knowledge Tracing (BKT) and Performance Factors Analysis (PFA). However, these deep learning based models are not as interpretable as other models because the decision-making process learned by deep neural networks is not wholly understood by the research community. In previous work, we critically examined the DKT model, visualizing and analyzing the behaviors of DKT in high dimensional space. In this work, we extend our original analyses with a much larger dataset and add discussions about the memory states of the DKVMN model. We discover that Deep Knowledge Tracing has some critical pitfalls: 1) instead of tracking each skill through time, DKT is more likely to learn an `ability' model; 2) the recurrent nature of DKT reinforces irrelevant information that it uses during the tracking task; 3) an untrained recurrent network can achieve similar results to a trained DKT model, supporting a conclusion that recurrence relations are not properly learned and, instead, improvements are simply a benefit of projection into a high dimensional, sparse vector space. Based on these observations, we propose improvements and future directions for conducting knowledge tracing research using deep neural network models.
Swapped Face Detection using Deep Learning and Subjective Assessment
Sep 10, 2019


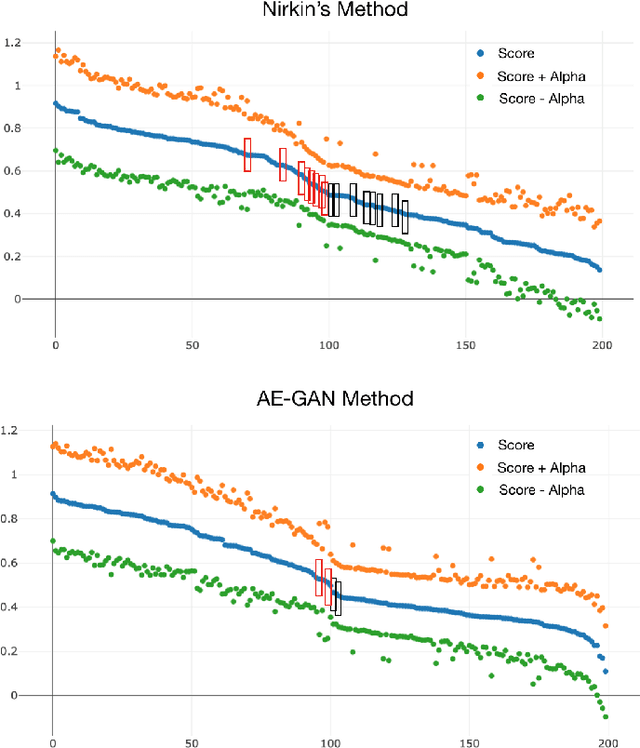
The tremendous success of deep learning for imaging applications has resulted in numerous beneficial advances. Unfortunately, this success has also been a catalyst for malicious uses such as photo-realistic face swapping of parties without consent. Transferring one person's face from a source image to a target image of another person, while keeping the image photo-realistic overall has become increasingly easy and automatic, even for individuals without much knowledge of image processing. In this study, we use deep transfer learning for face swapping detection, showing true positive rates >96% with very few false alarms. Distinguished from existing methods that only provide detection accuracy, we also provide uncertainty for each prediction, which is critical for trust in the deployment of such detection systems. Moreover, we provide a comparison to human subjects. To capture human recognition performance, we build a website to collect pairwise comparisons of images from human subjects. Based on these comparisons, images are ranked from most real to most fake. We compare this ranking to the outputs from our automatic model, showing good, but imperfect, correspondence with linear correlations >0.75. Overall, the results show the effectiveness of our method. As part of this study, we create a novel, publicly available dataset that is, to the best of our knowledge, the largest public swapped face dataset created using still images. Our goal of this study is to inspire more research in the field of image forensics through the creation of a public dataset and initial analysis.