 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDropout Robustness and Cognitive Profiling of Transformer Models via Stochastic Inference
Mar 18, 2026Transformer-based language models are widely deployed for reasoning, yet their behavior under inference-time stochasticity remains underexplored. While dropout is common during training, its inference-time effects via Monte Carlo sampling lack systematic evaluation across architectures, limiting understanding of model reliability in uncertainty-aware applications. This work analyzes dropout-induced variability across 19 transformer models using MC Dropout with 100 stochastic forward passes per sample. Dropout robustness is defined as maintaining high accuracy and stable predictions under stochastic inference, measured by standard deviation of per-run accuracies. A cognitive decomposition framework disentangles performance into memory and reasoning components. Experiments span five dropout configurations yielding 95 unique evaluations on 1,000 samples. Results reveal substantial architectural variation. Smaller models demonstrate perfect prediction stability while medium-sized models exhibit notable volatility. Mid-sized models achieve the best overall performance; larger models excel at memory tasks. Critically, 53% of models suffer severe accuracy degradation under baseline MC Dropout, with task-specialized models losing up to 24 percentage points, indicating unsuitability for uncertainty quantification in these architectures. Asymmetric effects emerge: high dropout reduces memory accuracy by 27 percentage points while reasoning degrades only 1 point, suggesting memory tasks rely on stable representations that dropout disrupts. 84% of models demonstrate memory-biased performance. This provides the first comprehensive MC Dropout benchmark for transformers, revealing dropout robustness is architecture-dependent and uncorrelated with scale. The cognitive profiling framework offers actionable guidance for model selection in uncertainty-aware applications.
AI Content Self-Detection for Transformer-based Large Language Models
Dec 28, 2023$ $The usage of generative artificial intelligence (AI) tools based on large language models, including ChatGPT, Bard, and Claude, for text generation has many exciting applications with the potential for phenomenal productivity gains. One issue is authorship attribution when using AI tools. This is especially important in an academic setting where the inappropriate use of generative AI tools may hinder student learning or stifle research by creating a large amount of automatically generated derivative work. Existing plagiarism detection systems can trace the source of submitted text but are not yet equipped with methods to accurately detect AI-generated text. This paper introduces the idea of direct origin detection and evaluates whether generative AI systems can recognize their output and distinguish it from human-written texts. We argue why current transformer-based models may be able to self-detect their own generated text and perform a small empirical study using zero-shot learning to investigate if that is the case. Results reveal varying capabilities of AI systems to identify their generated text. Google's Bard model exhibits the largest capability of self-detection with an accuracy of 94\%, followed by OpenAI's ChatGPT with 83\%. On the other hand, Anthropic's Claude model seems to be not able to self-detect.
recommenderlab: An R Framework for Developing and Testing Recommendation Algorithms
May 24, 2022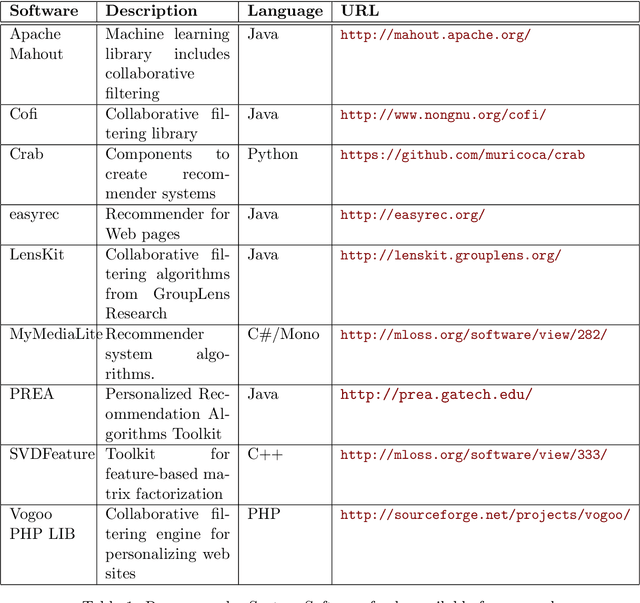
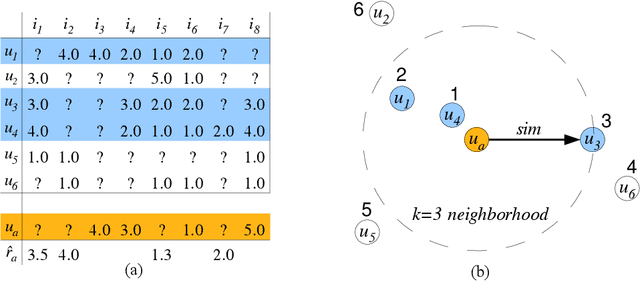
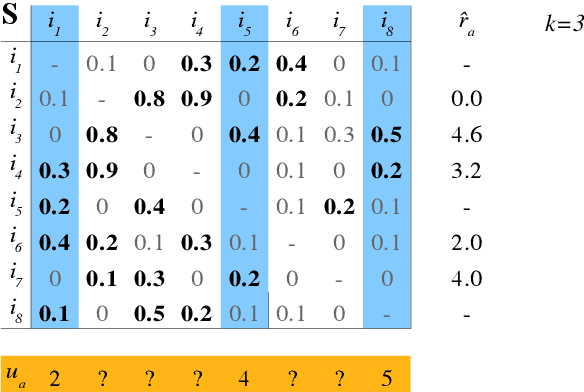

Algorithms that create recommendations based on observed data have significant commercial value for online retailers and many other industries. Recommender systems have a significant research community, and studying such systems is part of most modern data science curricula. While there is an abundance of software that implements recommendation algorithms, there is little in terms of supporting recommender system research and education. This paper describes the open-source software recommenderlab which was created with supporting research and education in mind. The package can be directly installed in R or downloaded from https://github.com/mhahsler/recommenderlab.
Swapped Face Detection using Deep Learning and Subjective Assessment
Sep 10, 2019


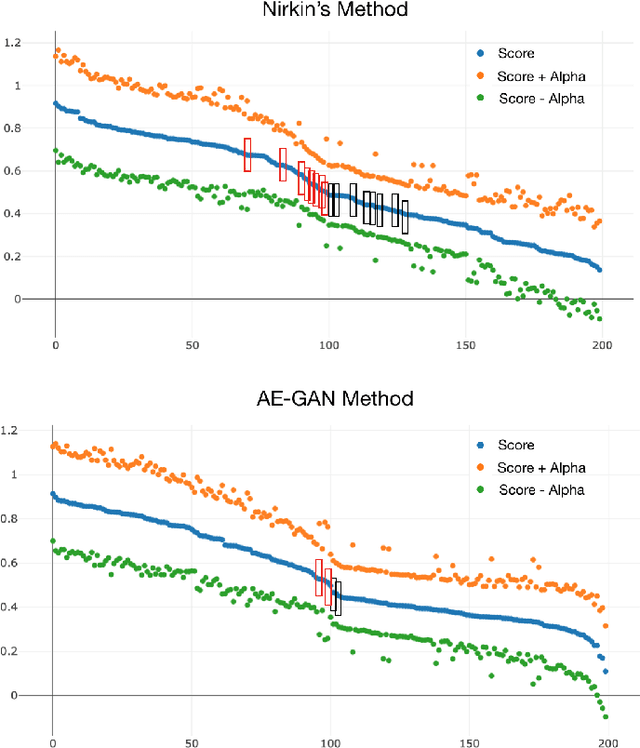
The tremendous success of deep learning for imaging applications has resulted in numerous beneficial advances. Unfortunately, this success has also been a catalyst for malicious uses such as photo-realistic face swapping of parties without consent. Transferring one person's face from a source image to a target image of another person, while keeping the image photo-realistic overall has become increasingly easy and automatic, even for individuals without much knowledge of image processing. In this study, we use deep transfer learning for face swapping detection, showing true positive rates >96% with very few false alarms. Distinguished from existing methods that only provide detection accuracy, we also provide uncertainty for each prediction, which is critical for trust in the deployment of such detection systems. Moreover, we provide a comparison to human subjects. To capture human recognition performance, we build a website to collect pairwise comparisons of images from human subjects. Based on these comparisons, images are ranked from most real to most fake. We compare this ranking to the outputs from our automatic model, showing good, but imperfect, correspondence with linear correlations >0.75. Overall, the results show the effectiveness of our method. As part of this study, we create a novel, publicly available dataset that is, to the best of our knowledge, the largest public swapped face dataset created using still images. Our goal of this study is to inspire more research in the field of image forensics through the creation of a public dataset and initial analysis.
New probabilistic interest measures for association rules
Mar 06, 2008

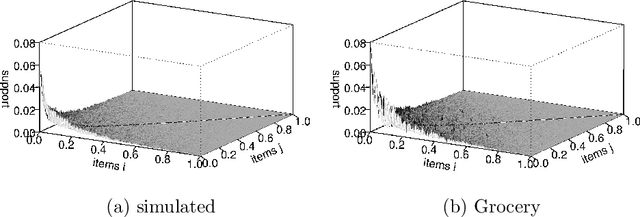
Mining association rules is an important technique for discovering meaningful patterns in transaction databases. Many different measures of interestingness have been proposed for association rules. However, these measures fail to take the probabilistic properties of the mined data into account. In this paper, we start with presenting a simple probabilistic framework for transaction data which can be used to simulate transaction data when no associations are present. We use such data and a real-world database from a grocery outlet to explore the behavior of confidence and lift, two popular interest measures used for rule mining. The results show that confidence is systematically influenced by the frequency of the items in the left hand side of rules and that lift performs poorly to filter random noise in transaction data. Based on the probabilistic framework we develop two new interest measures, hyper-lift and hyper-confidence, which can be used to filter or order mined association rules. The new measures show significantly better performance than lift for applications where spurious rules are problematic.