 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Limits of Open-Weight CLIP: An Optimization Framework for Self-supervised Fine-tuning of CLIP
Jan 14, 2026CLIP has become a cornerstone of multimodal representation learning, yet improving its performance typically requires a prohibitively costly process of training from scratch on billions of samples. We ask a different question: Can we improve the performance of open-weight CLIP models across various downstream tasks using only existing self-supervised datasets? Unlike supervised fine-tuning, which adapts a pretrained model to a single downstream task, our setting seeks to improve general performance across various tasks. However, as both our experiments and prior studies reveal, simply applying standard training protocols starting from an open-weight CLIP model often fails, leading to performance degradation. In this paper, we introduce TuneCLIP, a self-supervised fine-tuning framework that overcomes the performance degradation. TuneCLIP has two key components: (1) a warm-up stage of recovering optimization statistics to reduce cold-start bias, inspired by theoretical analysis, and (2) a fine-tuning stage of optimizing a new contrastive loss to mitigate the penalization on false negative pairs. Our extensive experiments show that TuneCLIP consistently improves performance across model architectures and scales. Notably, it elevates leading open-weight models like SigLIP (ViT-B/16), achieving gains of up to +2.5% on ImageNet and related out-of-distribution benchmarks, and +1.2% on the highly competitive DataComp benchmark, setting a new strong baseline for efficient post-pretraining adaptation.
HFMF: Hierarchical Fusion Meets Multi-Stream Models for Deepfake Detection
Jan 10, 2025The rapid progress in deep generative models has led to the creation of incredibly realistic synthetic images that are becoming increasingly difficult to distinguish from real-world data. The widespread use of Variational Models, Diffusion Models, and Generative Adversarial Networks has made it easier to generate convincing fake images and videos, which poses significant challenges for detecting and mitigating the spread of misinformation. As a result, developing effective methods for detecting AI-generated fakes has become a pressing concern. In our research, we propose HFMF, a comprehensive two-stage deepfake detection framework that leverages both hierarchical cross-modal feature fusion and multi-stream feature extraction to enhance detection performance against imagery produced by state-of-the-art generative AI models. The first component of our approach integrates vision Transformers and convolutional nets through a hierarchical feature fusion mechanism. The second component of our framework combines object-level information and a fine-tuned convolutional net model. We then fuse the outputs from both components via an ensemble deep neural net, enabling robust classification performances. We demonstrate that our architecture achieves superior performance across diverse dataset benchmarks while maintaining calibration and interoperability.
AmCLR: Unified Augmented Learning for Cross-Modal Representations
Dec 10, 2024



Contrastive learning has emerged as a pivotal framework for representation learning, underpinning advances in both unimodal and bimodal applications like SimCLR and CLIP. To address fundamental limitations like large batch size dependency and bimodality, methods such as SogCLR leverage stochastic optimization for the global contrastive objective. Inspired by SogCLR's efficiency and adaptability, we introduce AmCLR and xAmCLR objective functions tailored for bimodal vision-language models to further enhance the robustness of contrastive learning. AmCLR integrates diverse augmentations, including text paraphrasing and image transformations, to reinforce the alignment of contrastive representations, keeping batch size limited to a few hundred samples unlike CLIP which needs batch size of 32,768 to produce reasonable results. xAmCLR further extends this paradigm by incorporating intra-modal alignments between original and augmented modalities for richer feature learning. These advancements yield a more resilient and generalizable contrastive learning process, aimed at overcoming bottlenecks in scaling and augmentative diversity. Since we have built our framework on the existing SogCLR, we are able to demonstrate improved representation quality with fewer computational resources, establishing a foundation for scalable and robust multi-modal learning.
Predictive Maintenance of Armoured Vehicles using Machine Learning Approaches
Jul 26, 2023



Armoured vehicles are specialized and complex pieces of machinery designed to operate in high-stress environments, often in combat or tactical situations. This study proposes a predictive maintenance-based ensemble system that aids in predicting potential maintenance needs based on sensor data collected from these vehicles. The proposed model's architecture involves various models such as Light Gradient Boosting, Random Forest, Decision Tree, Extra Tree Classifier and Gradient Boosting to predict the maintenance requirements of the vehicles accurately. In addition, K-fold cross validation, along with TOPSIS analysis, is employed to evaluate the proposed ensemble model's stability. The results indicate that the proposed system achieves an accuracy of 98.93%, precision of 99.80% and recall of 99.03%. The algorithm can effectively predict maintenance needs, thereby reducing vehicle downtime and improving operational efficiency. Through comparisons between various algorithms and the suggested ensemble, this study highlights the potential of machine learning-based predictive maintenance solutions.
Benchmarking the Effectiveness of Classification Algorithms and SVM Kernels for Dry Beans
Jul 15, 2023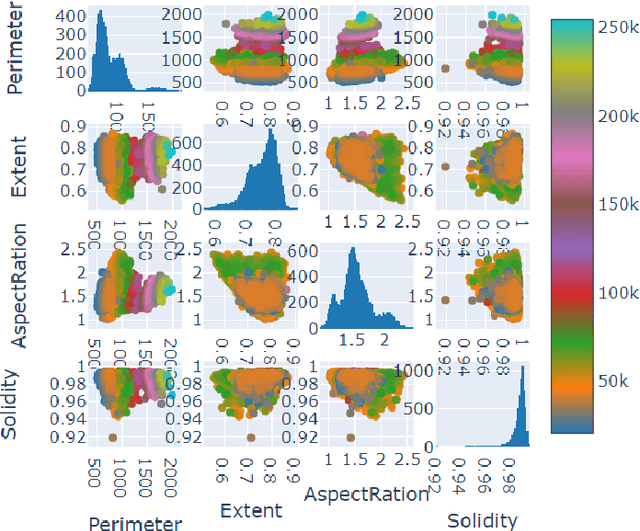
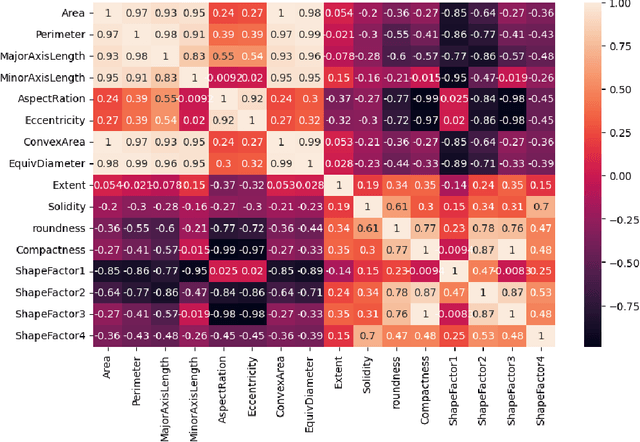

Plant breeders and agricultural researchers can increase crop productivity by identifying desirable features, disease resistance, and nutritional content by analysing the Dry Bean dataset. This study analyses and compares different Support Vector Machine (SVM) classification algorithms, namely linear, polynomial, and radial basis function (RBF), along with other popular classification algorithms. The analysis is performed on the Dry Bean Dataset, with PCA (Principal Component Analysis) conducted as a preprocessing step for dimensionality reduction. The primary evaluation metric used is accuracy, and the RBF SVM kernel algorithm achieves the highest Accuracy of 93.34%, Precision of 92.61%, Recall of 92.35% and F1 Score as 91.40%. Along with adept visualization and empirical analysis, this study offers valuable guidance by emphasizing the importance of considering different SVM algorithms for complex and non-linear structured datasets.