 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIVINE: Coordinating Multimodal Disentangled Representations for Oro-Facial Neurological Disorder Assessment
Jan 11, 2026In this study, we present a multimodal framework for predicting neuro-facial disorders by capturing both vocal and facial cues. We hypothesize that explicitly disentangling shared and modality-specific representations within multimodal foundation model embeddings can enhance clinical interpretability and generalization. To validate this hypothesis, we propose DIVINE a fully disentangled multimodal framework that operates on representations extracted from state-of-the-art (SOTA) audio and video foundation models, incorporating hierarchical variational bottlenecks, sparse gated fusion, and learnable symptom tokens. DIVINE operates in a multitask learning setup to jointly predict diagnostic categories (Healthy Control,ALS, Stroke) and severity levels (Mild, Moderate, Severe). The model is trained using synchronized audio and video inputs and evaluated on the Toronto NeuroFace dataset under full (audio-video) as well as single-modality (audio-only and video-only) test conditions. Our proposed approach, DIVINE achieves SOTA result, with the DeepSeek-VL2 and TRILLsson combination reaching 98.26% accuracy and 97.51% F1-score. Under modality-constrained scenarios, the framework performs well, showing strong generalization when tested with video-only or audio-only inputs. It consistently yields superior performance compared to unimodal models and baseline fusion techniques. To the best of our knowledge, DIVINE is the first framework that combines cross-modal disentanglement, adaptive fusion, and multitask learning to comprehensively assess neurological disorders using synchronized speech and facial video.
Bridging Attribution and Open-Set Detection using Graph-Augmented Instance Learning in Synthetic Speech
Jan 11, 2026We propose a unified framework for not only attributing synthetic speech to its source but also for detecting speech generated by synthesizers that were not encountered during training. This requires methods that move beyond simple detection to support both detailed forensic analysis and open-set generalization. To address this, we introduce SIGNAL, a hybrid framework that combines speech foundation models (SFMs) with graph-based modeling and open-set-aware inference. Our framework integrates Graph Neural Networks (GNNs) and a k-Nearest Neighbor (KNN) classifier, allowing it to capture meaningful relationships between utterances and recognize speech that doesn`t belong to any known generator. It constructs a query-conditioned graph over generator class prototypes, enabling the GNN to reason over relationships among candidate generators, while the KNN branch supports open-set detection via confidence-based thresholding. We evaluate SIGNAL using the DiffSSD dataset, which offers a diverse mix of real speech and synthetic audio from both open-source and commercial diffusion-based TTS systems. To further assess generalization, we also test on the SingFake benchmark. Our results show that SIGNAL consistently improves performance across both tasks, with Mamba-based embeddings delivering especially strong results. To the best of our knowledge, this is the first study to unify graph-based learning and open-set detection for tracing synthetic speech back to its origin.
Towards Attribution of Generators and Emotional Manipulation in Cross-Lingual Synthetic Speech using Geometric Learning
Nov 13, 2025



In this work, we address the problem of finegrained traceback of emotional and manipulation characteristics from synthetically manipulated speech. We hypothesize that combining semantic-prosodic cues captured by Speech Foundation Models (SFMs) with fine-grained spectral dynamics from auditory representations can enable more precise tracing of both emotion and manipulation source. To validate this hypothesis, we introduce MiCuNet, a novel multitask framework for fine-grained tracing of emotional and manipulation attributes in synthetically generated speech. Our approach integrates SFM embeddings with spectrogram-based auditory features through a mixed-curvature projection mechanism that spans Hyperbolic, Euclidean, and Spherical spaces guided by a learnable temporal gating mechanism. Our proposed method adopts a multitask learning setup to simultaneously predict original emotions, manipulated emotions, and manipulation sources on the EmoFake dataset (EFD) across both English and Chinese subsets. MiCuNet yields consistent improvements, consistently surpassing conventional fusion strategies. To the best of our knowledge, this work presents the first study to explore a curvature-adaptive framework specifically tailored for multitask tracking in synthetic speech.
Curved Worlds, Clear Boundaries: Generalizing Speech Deepfake Detection using Hyperbolic and Spherical Geometry Spaces
Nov 13, 2025In this work, we address the challenge of generalizable audio deepfake detection (ADD) across diverse speech synthesis paradigms-including conventional text-to-speech (TTS) systems and modern diffusion or flow-matching (FM) based generators. Prior work has mostly targeted individual synthesis families and often fails to generalize across paradigms due to overfitting to generation-specific artifacts. We hypothesize that synthetic speech, irrespective of its generative origin, leaves behind shared structural distortions in the embedding space that can be aligned through geometry-aware modeling. To this end, we propose RHYME, a unified detection framework that fuses utterance-level embeddings from diverse pretrained speech encoders using non-Euclidean projections. RHYME maps representations into hyperbolic and spherical manifolds-where hyperbolic geometry excels at modeling hierarchical generator families, and spherical projections capture angular, energy-invariant cues such as periodic vocoder artifacts. The fused representation is obtained via Riemannian barycentric averaging, enabling synthesis-invariant alignment. RHYME outperforms individual PTMs and homogeneous fusion baselines, achieving top performance and setting new state-of-the-art in cross-paradigm ADD.
Are Multimodal Foundation Models All That Is Needed for Emofake Detection?
Sep 19, 2025In this work, we investigate multimodal foundation models (MFMs) for EmoFake detection (EFD) and hypothesize that they will outperform audio foundation models (AFMs). MFMs due to their cross-modal pre-training, learns emotional patterns from multiple modalities, while AFMs rely only on audio. As such, MFMs can better recognize unnatural emotional shifts and inconsistencies in manipulated audio, making them more effective at distinguishing real from fake emotional expressions. To validate our hypothesis, we conduct a comprehensive comparative analysis of state-of-the-art (SOTA) MFMs (e.g. LanguageBind) alongside AFMs (e.g. WavLM). Our experiments confirm that MFMs surpass AFMs for EFD. Beyond individual foundation models (FMs) performance, we explore FMs fusion, motivated by findings in related research areas such synthetic speech detection and speech emotion recognition. To this end, we propose SCAR, a novel framework for effective fusion. SCAR introduces a nested cross-attention mechanism, where representations from FMs interact at two stages sequentially to refine information exchange. Additionally, a self-attention refinement module further enhances feature representations by reinforcing important cross-FM cues while suppressing noise. Through SCAR with synergistic fusion of MFMs, we achieve SOTA performance, surpassing both standalone FMs and conventional fusion approaches and previous works on EFD.
Rethinking Cross-Corpus Speech Emotion Recognition Benchmarking: Are Paralinguistic Pre-Trained Representations Sufficient?
Sep 19, 2025Recent benchmarks evaluating pre-trained models (PTMs) for cross-corpus speech emotion recognition (SER) have overlooked PTM pre-trained for paralinguistic speech processing (PSP), raising concerns about their reliability, since SER is inherently a paralinguistic task. We hypothesize that PSP-focused PTM will perform better in cross-corpus SER settings. To test this, we analyze state-of-the-art PTMs representations including paralinguistic, monolingual, multilingual, and speaker recognition. Our results confirm that TRILLsson (a paralinguistic PTM) outperforms others, reinforcing the need to consider PSP-focused PTMs in cross-corpus SER benchmarks. This study enhances benchmark trustworthiness and guides PTMs evaluations for reliable cross-corpus SER.
Towards Neural Audio Codec Source Parsing
Jun 14, 2025A new class of audio deepfakes-codecfakes (CFs)-has recently caught attention, synthesized by Audio Language Models that leverage neural audio codecs (NACs) in the backend. In response, the community has introduced dedicated benchmarks and tailored detection strategies. As the field advances, efforts have moved beyond binary detection toward source attribution, including open-set attribution, which aims to identify the NAC responsible for generation and flag novel, unseen ones during inference. This shift toward source attribution improves forensic interpretability and accountability. However, open-set attribution remains fundamentally limited: while it can detect that a NAC is unfamiliar, it cannot characterize or identify individual unseen codecs. It treats such inputs as generic ``unknowns'', lacking insight into their internal configuration. This leads to major shortcomings: limited generalization to new NACs and inability to resolve fine-grained variations within NAC families. To address these gaps, we propose Neural Audio Codec Source Parsing (NACSP) - a paradigm shift that reframes source attribution for CFs as structured regression over generative NAC parameters such as quantizers, bandwidth, and sampling rate. We formulate NACSP as a multi-task regression task for predicting these NAC parameters and establish the first comprehensive benchmark using various state-of-the-art speech pre-trained models (PTMs). To this end, we propose HYDRA, a novel framework that leverages hyperbolic geometry to disentangle complex latent properties from PTM representations. By employing task-specific attention over multiple curvature-aware hyperbolic subspaces, HYDRA enables superior multi-task generalization. Our extensive experiments show HYDRA achieves top results on benchmark CFs datasets compared to baselines operating in Euclidean space.
Beyond Speech and More: Investigating the Emergent Ability of Speech Foundation Models for Classifying Physiological Time-Series Signals
Oct 16, 2024



Despite being trained exclusively on speech data, speech foundation models (SFMs) like Whisper have shown impressive performance in non-speech tasks such as audio classification. This is partly because speech shares some common traits with audio, enabling SFMs to transfer effectively. In this study, we push the boundaries by evaluating SFMs on a more challenging out-of-domain (OOD) task: classifying physiological time-series signals. We test two key hypotheses: first, that SFMs can generalize to physiological signals by capturing shared temporal patterns; second, that multilingual SFMs will outperform others due to their exposure to greater variability during pre-training, leading to more robust, generalized representations. Our experiments, conducted for stress recognition using ECG (Electrocardiogram), EMG (Electromyography), and EDA (Electrodermal Activity) signals, reveal that models trained on SFM-derived representations outperform those trained on raw physiological signals. Among all models, multilingual SFMs achieve the highest accuracy, supporting our hypothesis and demonstrating their OOD capabilities. This work positions SFMs as promising tools for new uncharted domains beyond speech.
Representation Loss Minimization with Randomized Selection Strategy for Efficient Environmental Fake Audio Detection
Sep 24, 2024



The adaptation of foundation models has significantly advanced environmental audio deepfake detection (EADD), a rapidly growing area of research. These models are typically fine-tuned or utilized in their frozen states for downstream tasks. However, the dimensionality of their representations can substantially lead to a high parameter count of downstream models, leading to higher computational demands. So, a general way is to compress these representations by leveraging state-of-the-art (SOTA) unsupervised dimensionality reduction techniques (PCA, SVD, KPCA, GRP) for efficient EADD. However, with the application of such techniques, we observe a drop in performance. So in this paper, we show that representation vectors contain redundant information, and randomly selecting 40-50% of representation values and building downstream models on it preserves or sometimes even improves performance. We show that such random selection preserves more performance than the SOTA dimensionality reduction techniques while reducing model parameters and inference time by almost over half.
Strong Alone, Stronger Together: Synergizing Modality-Binding Foundation Models with Optimal Transport for Non-Verbal Emotion Recognition
Sep 21, 2024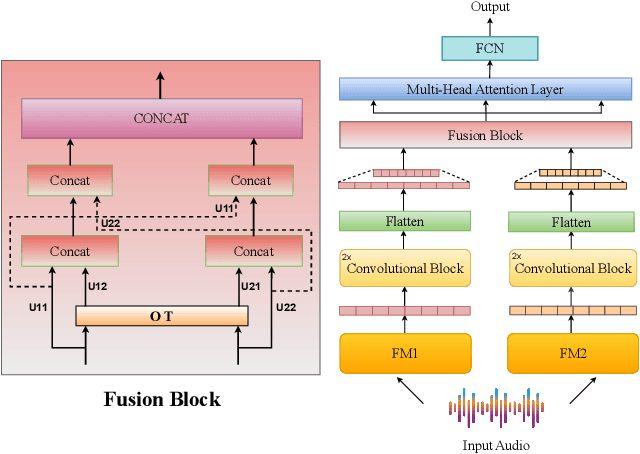
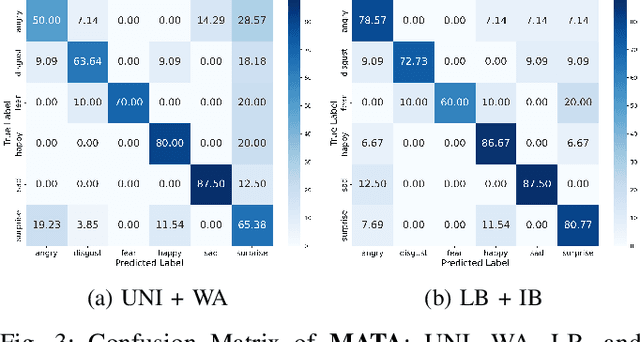
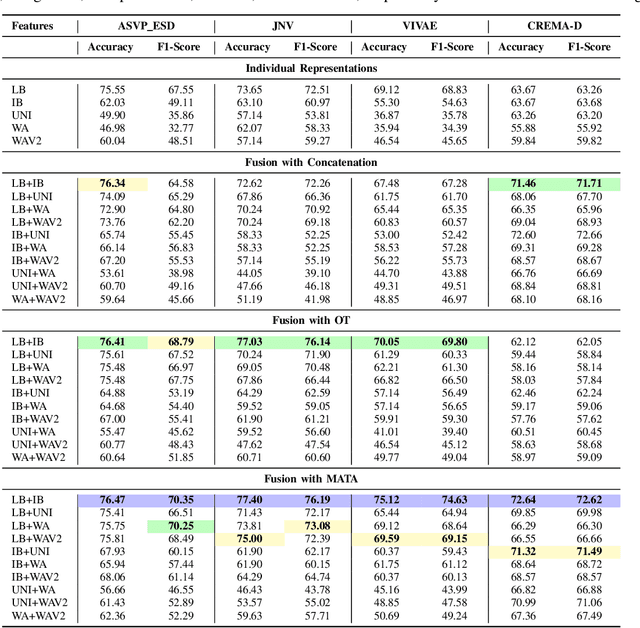
In this study, we investigate multimodal foundation models (MFMs) for emotion recognition from non-verbal sounds. We hypothesize that MFMs, with their joint pre-training across multiple modalities, will be more effective in non-verbal sounds emotion recognition (NVER) by better interpreting and differentiating subtle emotional cues that may be ambiguous in audio-only foundation models (AFMs). To validate our hypothesis, we extract representations from state-of-the-art (SOTA) MFMs and AFMs and evaluated them on benchmark NVER datasets. We also investigate the potential of combining selected foundation model representations to enhance NVER further inspired by research in speech recognition and audio deepfake detection. To achieve this, we propose a framework called MATA (Intra-Modality Alignment through Transport Attention). Through MATA coupled with the combination of MFMs: LanguageBind and ImageBind, we report the topmost performance with accuracies of 76.47%, 77.40%, 75.12% and F1-scores of 70.35%, 76.19%, 74.63% for ASVP-ESD, JNV, and VIVAE datasets against individual FMs and baseline fusion techniques and report SOTA on the benchmark datasets.