 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrong Alone, Stronger Together: Synergizing Modality-Binding Foundation Models with Optimal Transport for Non-Verbal Emotion Recognition
Paper and Code
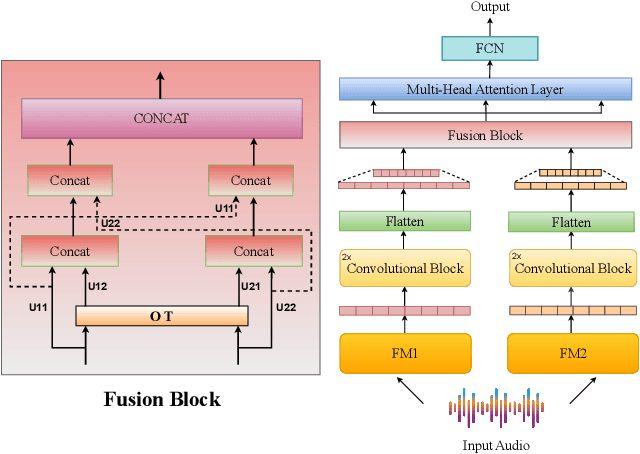
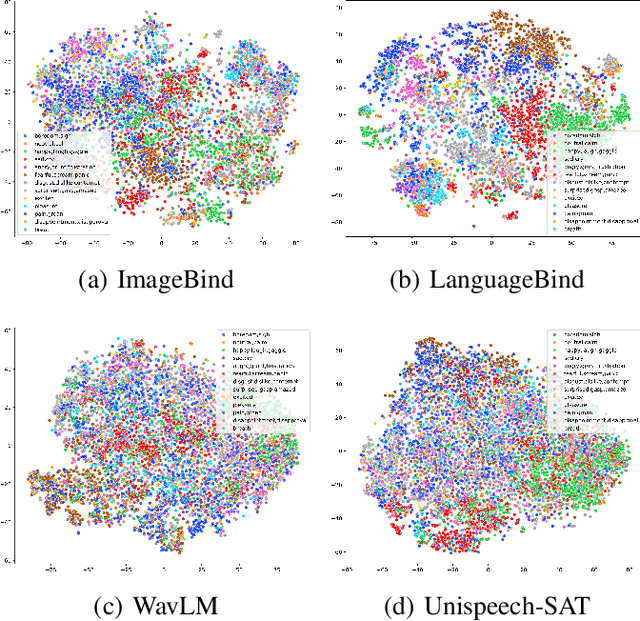
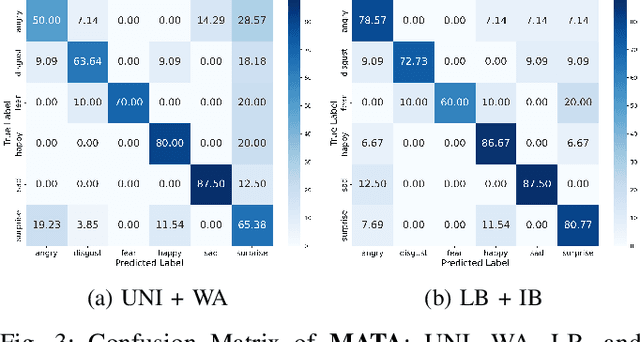
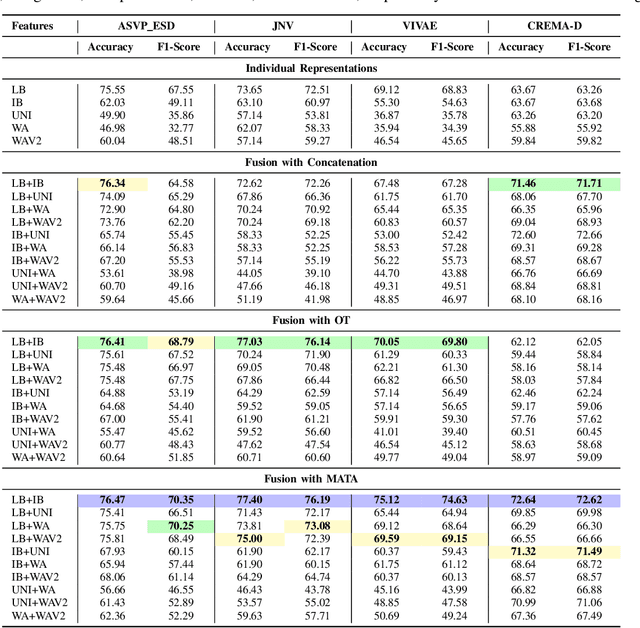
In this study, we investigate multimodal foundation models (MFMs) for emotion recognition from non-verbal sounds. We hypothesize that MFMs, with their joint pre-training across multiple modalities, will be more effective in non-verbal sounds emotion recognition (NVER) by better interpreting and differentiating subtle emotional cues that may be ambiguous in audio-only foundation models (AFMs). To validate our hypothesis, we extract representations from state-of-the-art (SOTA) MFMs and AFMs and evaluated them on benchmark NVER datasets. We also investigate the potential of combining selected foundation model representations to enhance NVER further inspired by research in speech recognition and audio deepfake detection. To achieve this, we propose a framework called MATA (Intra-Modality Alignment through Transport Attention). Through MATA coupled with the combination of MFMs: LanguageBind and ImageBind, we report the topmost performance with accuracies of 76.47%, 77.40%, 75.12% and F1-scores of 70.35%, 76.19%, 74.63% for ASVP-ESD, JNV, and VIVAE datasets against individual FMs and baseline fusion techniques and report SOTA on the benchmark datasets.