 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring rhythm formant analysis for Indic language classification
Oct 08, 2024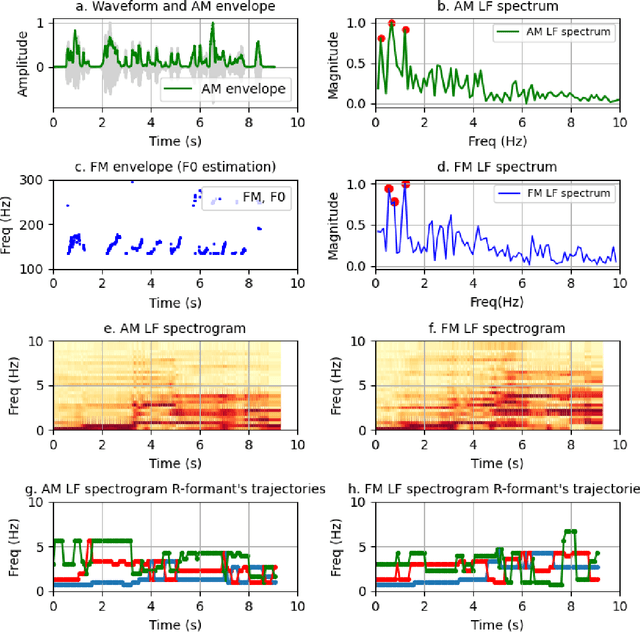
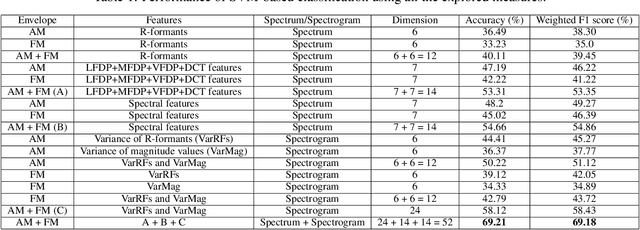
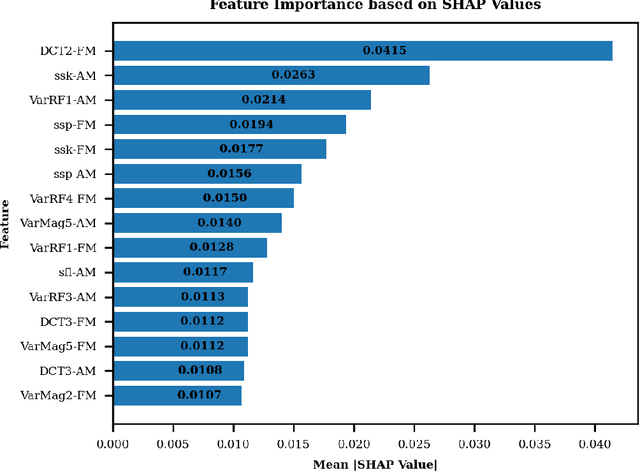
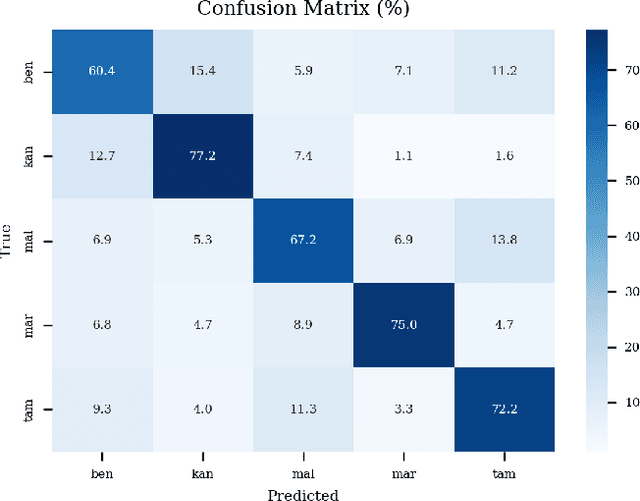
This paper reports a preliminary study on quantitative frequency domain rhythm cues for classifying five Indian languages: Bengali, Kannada, Malayalam, Marathi, and Tamil. We employ rhythm formant (R-formants) analysis, a technique introduced by Gibbon that utilizes low-frequency spectral analysis of amplitude modulation and frequency modulation envelopes to characterize speech rhythm. Various measures are computed from the LF spectrum, including R-formants, discrete cosine transform-based measures, and spectral measures. Results show that threshold-based and spectral features outperform directly computed R-formants. Temporal pattern of rhythm derived from LF spectrograms provides better language-discriminating cues. Combining all derived features we achieve an accuracy of 69.21% and a weighted F1 score of 69.18% in classifying the five languages. This study demonstrates the potential of RFA in characterizing speech rhythm for Indian language classification.
Representation Loss Minimization with Randomized Selection Strategy for Efficient Environmental Fake Audio Detection
Sep 24, 2024



The adaptation of foundation models has significantly advanced environmental audio deepfake detection (EADD), a rapidly growing area of research. These models are typically fine-tuned or utilized in their frozen states for downstream tasks. However, the dimensionality of their representations can substantially lead to a high parameter count of downstream models, leading to higher computational demands. So, a general way is to compress these representations by leveraging state-of-the-art (SOTA) unsupervised dimensionality reduction techniques (PCA, SVD, KPCA, GRP) for efficient EADD. However, with the application of such techniques, we observe a drop in performance. So in this paper, we show that representation vectors contain redundant information, and randomly selecting 40-50% of representation values and building downstream models on it preserves or sometimes even improves performance. We show that such random selection preserves more performance than the SOTA dimensionality reduction techniques while reducing model parameters and inference time by almost over half.
Are Music Foundation Models Better at Singing Voice Deepfake Detection? Far-Better Fuse them with Speech Foundation Models
Sep 21, 2024



In this study, for the first time, we extensively investigate whether music foundation models (MFMs) or speech foundation models (SFMs) work better for singing voice deepfake detection (SVDD), which has recently attracted attention in the research community. For this, we perform a comprehensive comparative study of state-of-the-art (SOTA) MFMs (MERT variants and music2vec) and SFMs (pre-trained for general speech representation learning as well as speaker recognition). We show that speaker recognition SFM representations perform the best amongst all the foundation models (FMs), and this performance can be attributed to its higher efficacy in capturing the pitch, tone, intensity, etc, characteristics present in singing voices. To our end, we also explore the fusion of FMs for exploiting their complementary behavior for improved SVDD, and we propose a novel framework, FIONA for the same. With FIONA, through the synchronization of x-vector (speaker recognition SFM) and MERT-v1-330M (MFM), we report the best performance with the lowest Equal Error Rate (EER) of 13.74 %, beating all the individual FMs as well as baseline FM fusions and achieving SOTA results.
Strong Alone, Stronger Together: Synergizing Modality-Binding Foundation Models with Optimal Transport for Non-Verbal Emotion Recognition
Sep 21, 2024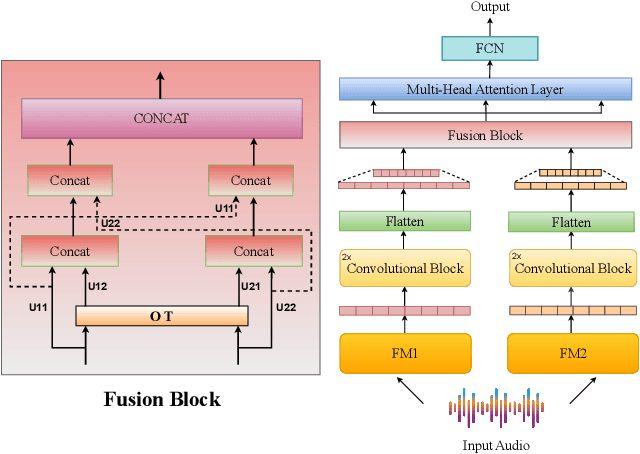
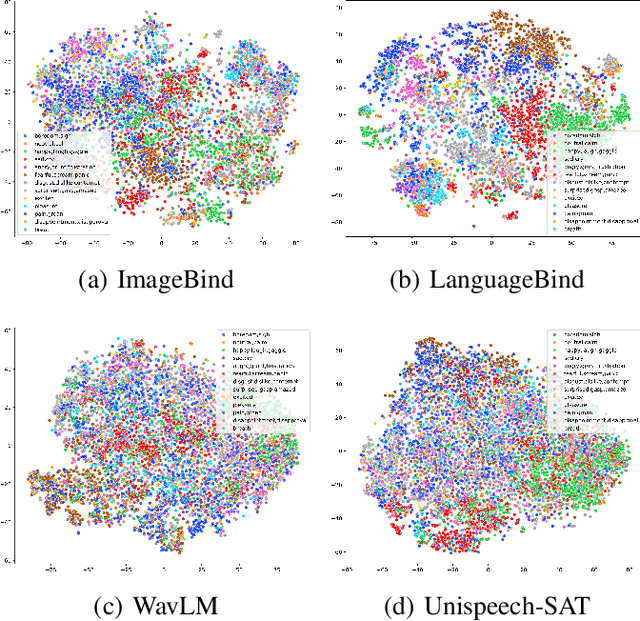
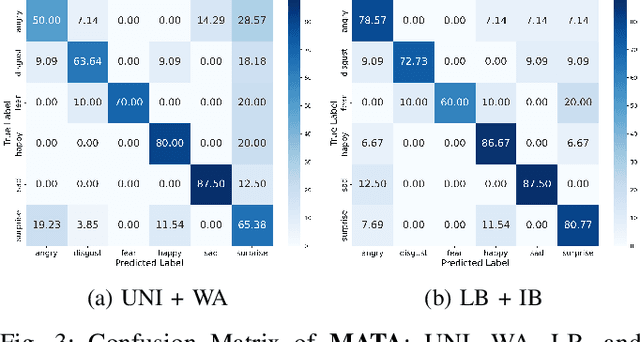
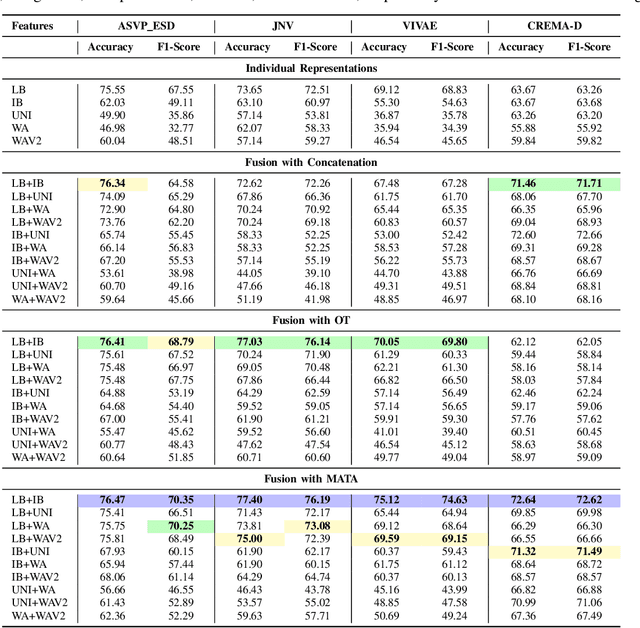
In this study, we investigate multimodal foundation models (MFMs) for emotion recognition from non-verbal sounds. We hypothesize that MFMs, with their joint pre-training across multiple modalities, will be more effective in non-verbal sounds emotion recognition (NVER) by better interpreting and differentiating subtle emotional cues that may be ambiguous in audio-only foundation models (AFMs). To validate our hypothesis, we extract representations from state-of-the-art (SOTA) MFMs and AFMs and evaluated them on benchmark NVER datasets. We also investigate the potential of combining selected foundation model representations to enhance NVER further inspired by research in speech recognition and audio deepfake detection. To achieve this, we propose a framework called MATA (Intra-Modality Alignment through Transport Attention). Through MATA coupled with the combination of MFMs: LanguageBind and ImageBind, we report the topmost performance with accuracies of 76.47%, 77.40%, 75.12% and F1-scores of 70.35%, 76.19%, 74.63% for ASVP-ESD, JNV, and VIVAE datasets against individual FMs and baseline fusion techniques and report SOTA on the benchmark datasets.