 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Prosodically Informed Mizo TTS without Explicit Tone Markings
Jan 05, 2026This paper reports on the development of a text-to-speech (TTS) system for Mizo, a low-resource, tonal, and Tibeto-Burman language spoken primarily in the Indian state of Mizoram. The TTS was built with only 5.18 hours of data; however, in terms of subjective and objective evaluations, the outputs were considered perceptually acceptable and intelligible. A baseline model using Tacotron2 was built, and then, with the same data, another TTS model was built with VITS. In both subjective and objective evaluations, the VITS model outperformed the Tacotron2 model. In terms of tone synthesis, the VITS model showed significantly lower tone errors than the Tacotron2 model. The paper demonstrates that a non-autoregressive, end-to-end framework can achieve synthesis of acceptable perceptual quality and intelligibility.
Analyzing long-term rhythm variations in Mising and Assamese using frequency domain correlates
Oct 26, 2024
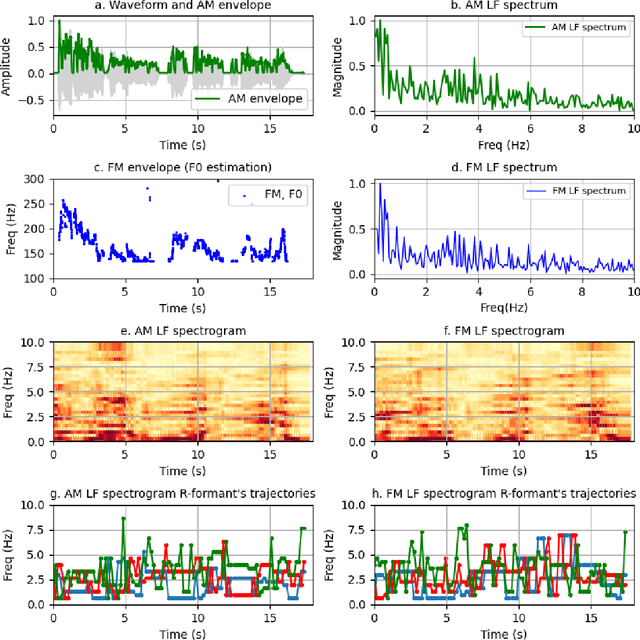
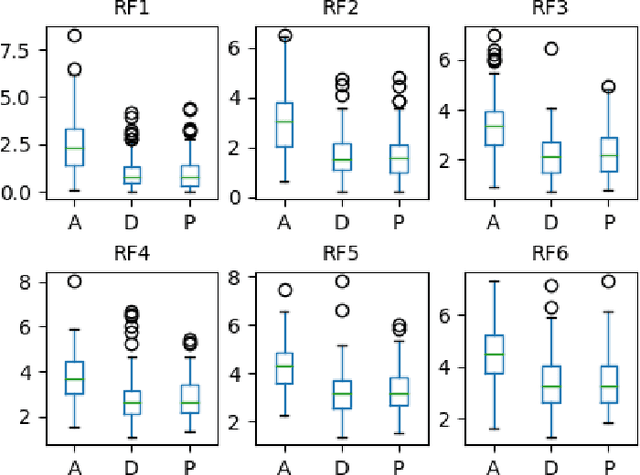
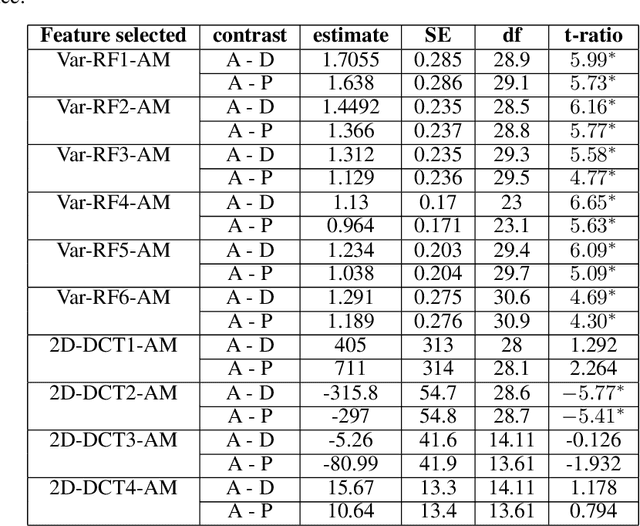
The current work explores long-term speech rhythm variations to classify Mising and Assamese, two low-resourced languages from Assam, Northeast India. We study the temporal information of speech rhythm embedded in low-frequency (LF) spectrograms derived from amplitude (AM) and frequency modulation (FM) envelopes. This quantitative frequency domain analysis of rhythm is supported by the idea of rhythm formant analysis (RFA), originally proposed by Gibbon [1]. We attempt to make the investigation by extracting features derived from trajectories of first six rhythm formants along with two-dimensional discrete cosine transform-based characterizations of the AM and FM LF spectrograms. The derived features are fed as input to a machine learning tool to contrast rhythms of Assamese and Mising. In this way, an improved methodology for empirically investigating rhythm variation structure without prior annotation of the larger unit of the speech signal is illustrated for two low-resourced languages of Northeast India.
Exploring rhythm formant analysis for Indic language classification
Oct 08, 2024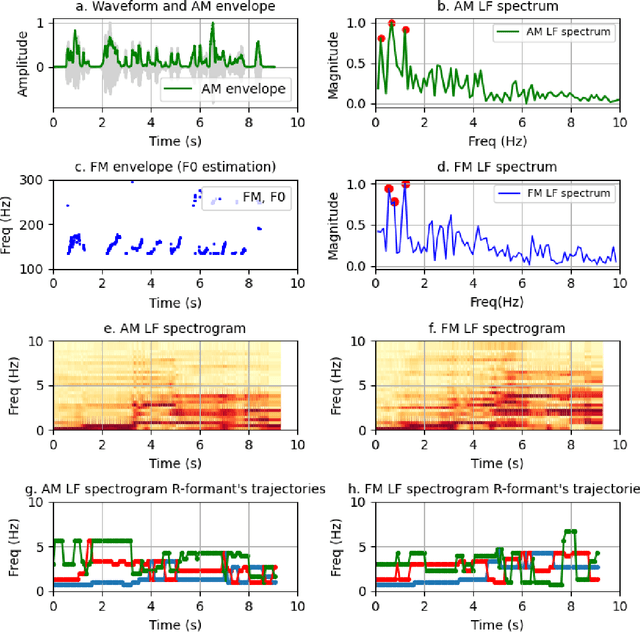
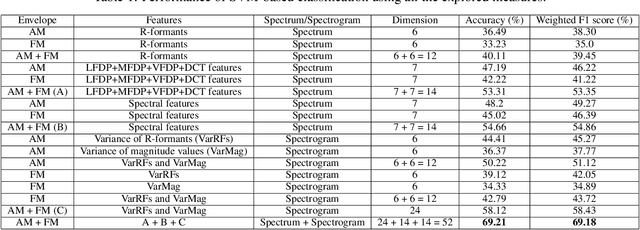
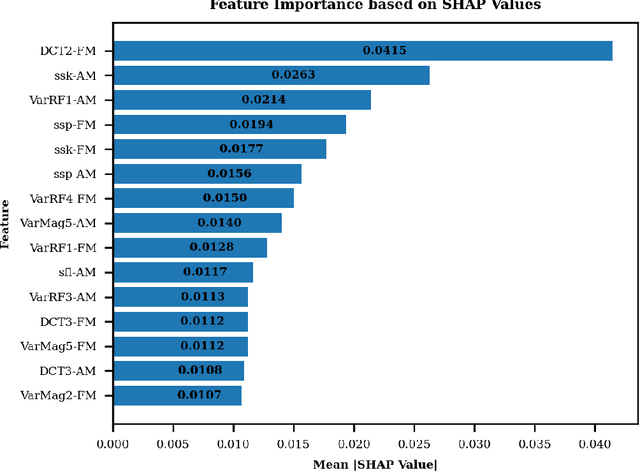
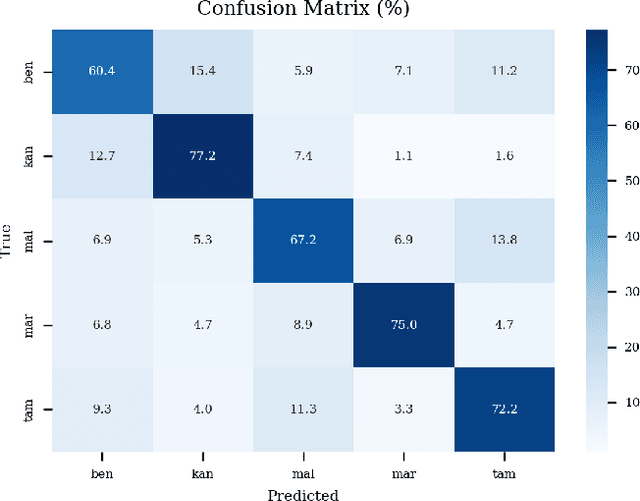
This paper reports a preliminary study on quantitative frequency domain rhythm cues for classifying five Indian languages: Bengali, Kannada, Malayalam, Marathi, and Tamil. We employ rhythm formant (R-formants) analysis, a technique introduced by Gibbon that utilizes low-frequency spectral analysis of amplitude modulation and frequency modulation envelopes to characterize speech rhythm. Various measures are computed from the LF spectrum, including R-formants, discrete cosine transform-based measures, and spectral measures. Results show that threshold-based and spectral features outperform directly computed R-formants. Temporal pattern of rhythm derived from LF spectrograms provides better language-discriminating cues. Combining all derived features we achieve an accuracy of 69.21% and a weighted F1 score of 69.18% in classifying the five languages. This study demonstrates the potential of RFA in characterizing speech rhythm for Indian language classification.
AsPOS: Assamese Part of Speech Tagger using Deep Learning Approach
Dec 14, 2022Part of Speech (POS) tagging is crucial to Natural Language Processing (NLP). It is a well-studied topic in several resource-rich languages. However, the development of computational linguistic resources is still in its infancy despite the existence of numerous languages that are historically and literary rich. Assamese, an Indian scheduled language, spoken by more than 25 million people, falls under this category. In this paper, we present a Deep Learning (DL)-based POS tagger for Assamese. The development process is divided into two stages. In the first phase, several pre-trained word embeddings are employed to train several tagging models. This allows us to evaluate the performance of the word embeddings in the POS tagging task. The top-performing model from the first phase is employed to annotate another set of new sentences. In the second phase, the model is trained further using the fresh dataset. Finally, we attain a tagging accuracy of 86.52% in F1 score. The model may serve as a baseline for further study on DL-based Assamese POS tagging.
AsNER -- Annotated Dataset and Baseline for Assamese Named Entity recognition
Jul 07, 2022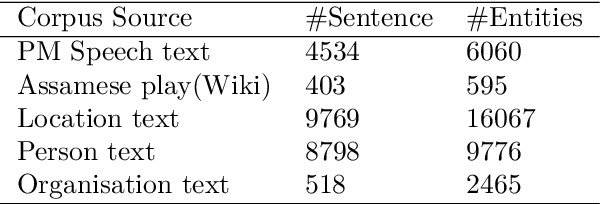
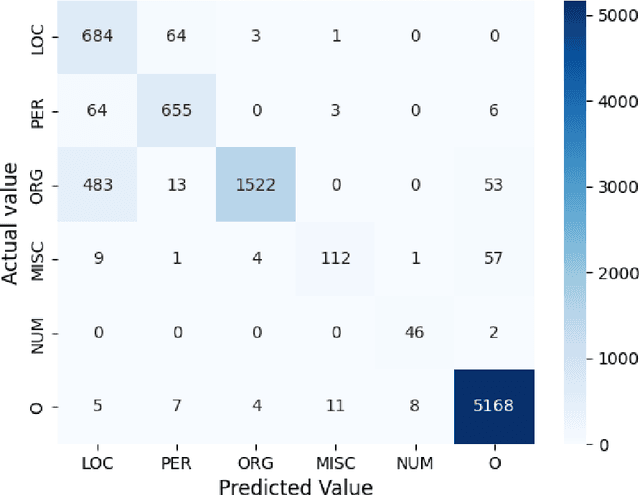
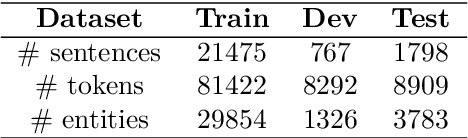
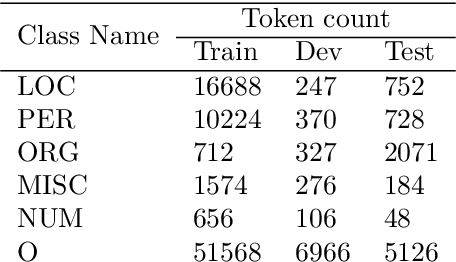
We present the AsNER, a named entity annotation dataset for low resource Assamese language with a baseline Assamese NER model. The dataset contains about 99k tokens comprised of text from the speech of the Prime Minister of India and Assamese play. It also contains person names, location names and addresses. The proposed NER dataset is likely to be a significant resource for deep neural based Assamese language processing. We benchmark the dataset by training NER models and evaluating using state-of-the-art architectures for supervised named entity recognition (NER) such as Fasttext, BERT, XLM-R, FLAIR, MuRIL etc. We implement several baseline approaches with state-of-the-art sequence tagging Bi-LSTM-CRF architecture. The highest F1-score among all baselines achieves an accuracy of 80.69% when using MuRIL as a word embedding method. The annotated dataset and the top performing model are made publicly available.
* Published at LREC 2022