 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing long-term rhythm variations in Mising and Assamese using frequency domain correlates
Oct 26, 2024
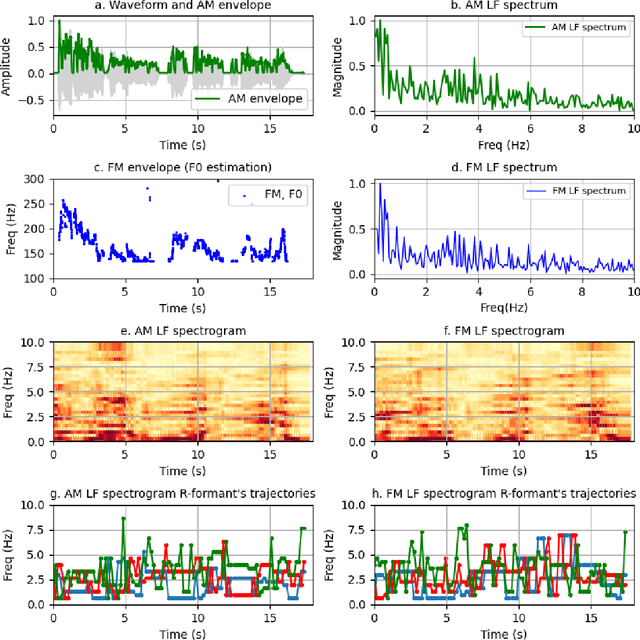
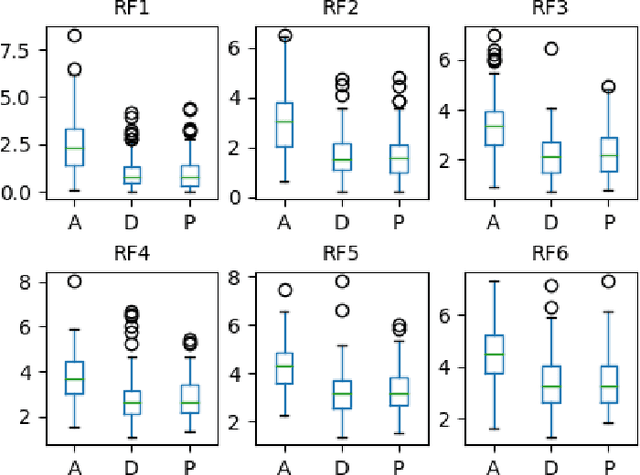
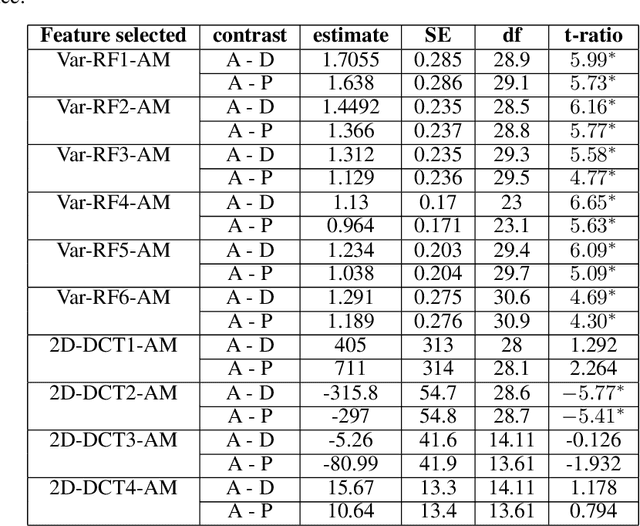
The current work explores long-term speech rhythm variations to classify Mising and Assamese, two low-resourced languages from Assam, Northeast India. We study the temporal information of speech rhythm embedded in low-frequency (LF) spectrograms derived from amplitude (AM) and frequency modulation (FM) envelopes. This quantitative frequency domain analysis of rhythm is supported by the idea of rhythm formant analysis (RFA), originally proposed by Gibbon [1]. We attempt to make the investigation by extracting features derived from trajectories of first six rhythm formants along with two-dimensional discrete cosine transform-based characterizations of the AM and FM LF spectrograms. The derived features are fed as input to a machine learning tool to contrast rhythms of Assamese and Mising. In this way, an improved methodology for empirically investigating rhythm variation structure without prior annotation of the larger unit of the speech signal is illustrated for two low-resourced languages of Northeast India.