 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Study of Zero-Shot Cross-Lingual Transfer for Bodo POS and NER Tagging Using Gemini 2.0 Flash Thinking Experimental Model
Mar 06, 2025Named Entity Recognition (NER) and Part-of-Speech (POS) tagging are critical tasks for Natural Language Processing (NLP), yet their availability for low-resource languages (LRLs) like Bodo remains limited. This article presents a comparative empirical study investigating the effectiveness of Google's Gemini 2.0 Flash Thinking Experiment model for zero-shot cross-lingual transfer of POS and NER tagging to Bodo. We explore two distinct methodologies: (1) direct translation of English sentences to Bodo followed by tag transfer, and (2) prompt-based tag transfer on parallel English-Bodo sentence pairs. Both methods leverage the machine translation and cross-lingual understanding capabilities of Gemini 2.0 Flash Thinking Experiment to project English POS and NER annotations onto Bodo text in CONLL-2003 format. Our findings reveal the capabilities and limitations of each approach, demonstrating that while both methods show promise for bootstrapping Bodo NLP, prompt-based transfer exhibits superior performance, particularly for NER. We provide a detailed analysis of the results, highlighting the impact of translation quality, grammatical divergences, and the inherent challenges of zero-shot cross-lingual transfer. The article concludes by discussing future research directions, emphasizing the need for hybrid approaches, few-shot fine-tuning, and the development of dedicated Bodo NLP resources to achieve high-accuracy POS and NER tagging for this low-resource language.
AC-Lite : A Lightweight Image Captioning Model for Low-Resource Assamese Language
Mar 03, 2025Neural networks have significantly advanced AI applications, yet their real-world adoption remains constrained by high computational demands, hardware limitations, and accessibility challenges. In image captioning, many state-of-the-art models have achieved impressive performances while relying on resource-intensive architectures. This made them impractical for deployment on resource-constrained devices. This limitation is particularly noticeable for applications involving low-resource languages. We demonstrate the case of image captioning in Assamese language, where lack of effective, scalable systems can restrict the accessibility of AI-based solutions for native Assamese speakers. This work presents AC-Lite, a computationally efficient model for image captioning in low-resource Assamese language. AC-Lite reduces computational requirements by replacing computation-heavy visual feature extractors like FasterRCNN with lightweight ShuffleNetv2x1.5. Additionally, Gated Recurrent Units (GRUs) are used as the caption decoder to further reduce computational demands and model parameters. Furthermore, the integration of bilinear attention enhances the model's overall performance. AC-Lite can operate on edge devices, thereby eliminating the need for computation on remote servers. The proposed AC-Lite model achieves 82.3 CIDEr score on the COCO-AC dataset with 1.098 GFLOPs and 25.65M parameters.
Part-of-Speech Tagger for Bodo Language using Deep Learning approach
Jan 06, 2024Language Processing systems such as Part-of-speech tagging, Named entity recognition, Machine translation, Speech recognition, and Language modeling (LM) are well-studied in high-resource languages. Nevertheless, research on these systems for several low-resource languages, including Bodo, Mizo, Nagamese, and others, is either yet to commence or is in its nascent stages. Language model plays a vital role in the downstream tasks of modern NLP. Extensive studies are carried out on LMs for high-resource languages. Nevertheless, languages such as Bodo, Rabha, and Mising continue to lack coverage. In this study, we first present BodoBERT, a language model for the Bodo language. To the best of our knowledge, this work is the first such effort to develop a language model for Bodo. Secondly, we present an ensemble DL-based POS tagging model for Bodo. The POS tagging model is based on combinations of BiLSTM with CRF and stacked embedding of BodoBERT with BytePairEmbeddings. We cover several language models in the experiment to see how well they work in POS tagging tasks. The best-performing model achieves an F1 score of 0.8041. A comparative experiment was also conducted on Assamese POS taggers, considering that the language is spoken in the same region as Bodo.
AsPOS: Assamese Part of Speech Tagger using Deep Learning Approach
Dec 14, 2022Part of Speech (POS) tagging is crucial to Natural Language Processing (NLP). It is a well-studied topic in several resource-rich languages. However, the development of computational linguistic resources is still in its infancy despite the existence of numerous languages that are historically and literary rich. Assamese, an Indian scheduled language, spoken by more than 25 million people, falls under this category. In this paper, we present a Deep Learning (DL)-based POS tagger for Assamese. The development process is divided into two stages. In the first phase, several pre-trained word embeddings are employed to train several tagging models. This allows us to evaluate the performance of the word embeddings in the POS tagging task. The top-performing model from the first phase is employed to annotate another set of new sentences. In the second phase, the model is trained further using the fresh dataset. Finally, we attain a tagging accuracy of 86.52% in F1 score. The model may serve as a baseline for further study on DL-based Assamese POS tagging.
AsNER -- Annotated Dataset and Baseline for Assamese Named Entity recognition
Jul 07, 2022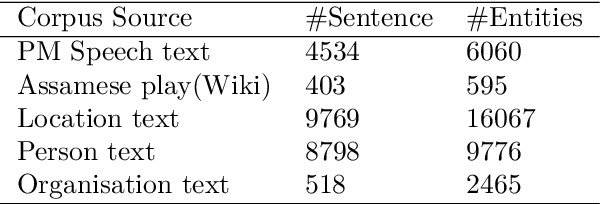
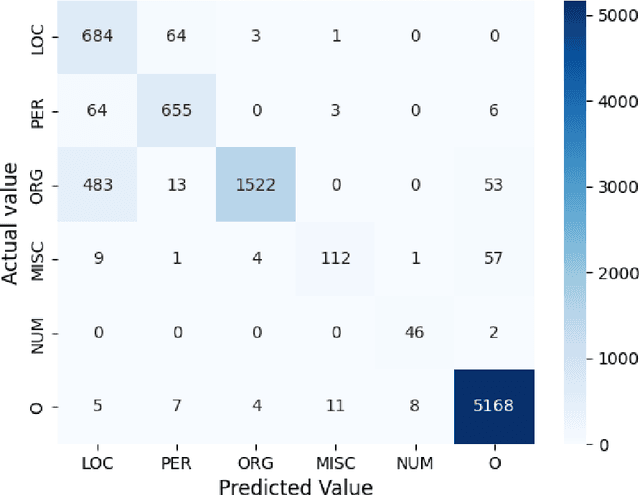
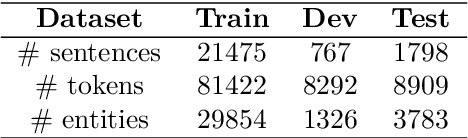
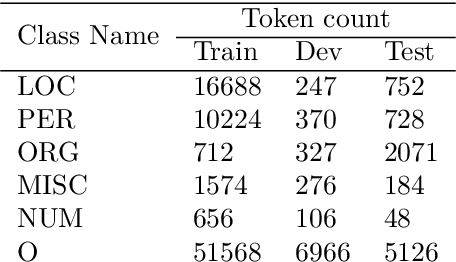
We present the AsNER, a named entity annotation dataset for low resource Assamese language with a baseline Assamese NER model. The dataset contains about 99k tokens comprised of text from the speech of the Prime Minister of India and Assamese play. It also contains person names, location names and addresses. The proposed NER dataset is likely to be a significant resource for deep neural based Assamese language processing. We benchmark the dataset by training NER models and evaluating using state-of-the-art architectures for supervised named entity recognition (NER) such as Fasttext, BERT, XLM-R, FLAIR, MuRIL etc. We implement several baseline approaches with state-of-the-art sequence tagging Bi-LSTM-CRF architecture. The highest F1-score among all baselines achieves an accuracy of 80.69% when using MuRIL as a word embedding method. The annotated dataset and the top performing model are made publicly available.
* Published at LREC 2022
PowerPlanningDL: Reliability-Aware Framework for On-Chip Power Grid Design using Deep Learning
May 04, 2020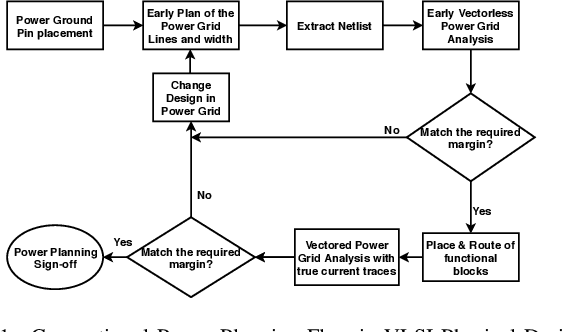
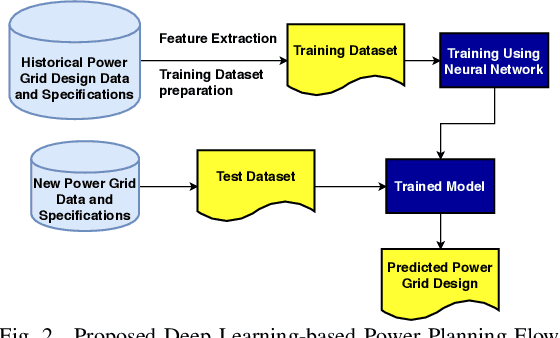

With the increase in the complexity of chip designs, VLSI physical design has become a time-consuming task, which is an iterative design process. Power planning is that part of the floorplanning in VLSI physical design where power grid networks are designed in order to provide adequate power to all the underlying functional blocks. Power planning also requires multiple iterative steps to create the power grid network while satisfying the allowed worst-case IR drop and Electromigration (EM) margin. For the first time, this paper introduces Deep learning (DL)-based framework to approximately predict the initial design of the power grid network, considering different reliability constraints. The proposed framework reduces many iterative design steps and speeds up the total design cycle. Neural Network-based multi-target regression technique is used to create the DL model. Feature extraction is done, and the training dataset is generated from the floorplans of some of the power grid designs extracted from the IBM processor. The DL model is trained using the generated dataset. The proposed DL-based framework is validated using a new set of power grid specifications (obtained by perturbing the designs used in the training phase). The results show that the predicted power grid design is closer to the original design with minimal prediction error (~2%). The proposed DL-based approach also improves the design cycle time with a speedup of ~6X for standard power grid benchmarks.