 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAC-Lite : A Lightweight Image Captioning Model for Low-Resource Assamese Language
Mar 03, 2025Neural networks have significantly advanced AI applications, yet their real-world adoption remains constrained by high computational demands, hardware limitations, and accessibility challenges. In image captioning, many state-of-the-art models have achieved impressive performances while relying on resource-intensive architectures. This made them impractical for deployment on resource-constrained devices. This limitation is particularly noticeable for applications involving low-resource languages. We demonstrate the case of image captioning in Assamese language, where lack of effective, scalable systems can restrict the accessibility of AI-based solutions for native Assamese speakers. This work presents AC-Lite, a computationally efficient model for image captioning in low-resource Assamese language. AC-Lite reduces computational requirements by replacing computation-heavy visual feature extractors like FasterRCNN with lightweight ShuffleNetv2x1.5. Additionally, Gated Recurrent Units (GRUs) are used as the caption decoder to further reduce computational demands and model parameters. Furthermore, the integration of bilinear attention enhances the model's overall performance. AC-Lite can operate on edge devices, thereby eliminating the need for computation on remote servers. The proposed AC-Lite model achieves 82.3 CIDEr score on the COCO-AC dataset with 1.098 GFLOPs and 25.65M parameters.
Enhancing Event Extraction from Short Stories through Contextualized Prompts
Dec 14, 2024



Event extraction is an important natural language processing (NLP) task of identifying events in an unstructured text. Although a plethora of works deal with event extraction from new articles, clinical text etc., only a few works focus on event extraction from literary content. Detecting events in short stories presents several challenges to current systems, encompassing a different distribution of events as compared to other domains and the portrayal of diverse emotional conditions. This paper presents \texttt{Vrittanta-EN}, a collection of 1000 English short stories annotated for real events. Exploring this field could result in the creation of techniques and resources that support literary scholars in improving their effectiveness. This could simultaneously influence the field of Natural Language Processing. Our objective is to clarify the intricate idea of events in the context of short stories. Towards the objective, we collected 1,000 short stories written mostly for children in the Indian context. Further, we present fresh guidelines for annotating event mentions and their categories, organized into \textit{seven distinct classes}. The classes are {\tt{COGNITIVE-MENTAL-STATE(CMS), COMMUNICATION(COM), CONFLICT(CON), GENERAL-ACTIVITY(GA), LIFE-EVENT(LE), MOVEMENT(MOV), and OTHERS(OTH)}}. Subsequently, we apply these guidelines to annotate the short story dataset. Later, we apply the baseline methods for automatically detecting and categorizing events. We also propose a prompt-based method for event detection and classification. The proposed method outperforms the baselines, while having significant improvement of more than 4\% for the class \texttt{CONFLICT} in event classification task.
FDLite: A Single Stage Lightweight Face Detector Network
Jun 27, 2024Face detection is frequently attempted by using heavy pre-trained backbone networks like ResNet-50/101/152 and VGG16/19. Few recent works have also proposed lightweight detectors with customized backbones, novel loss functions and efficient training strategies. The novelty of this work lies in the design of a lightweight detector while training with only the commonly used loss functions and learning strategies. The proposed face detector grossly follows the established RetinaFace architecture. The first contribution of this work is the design of a customized lightweight backbone network (BLite) having 0.167M parameters with 0.52 GFLOPs. The second contribution is the use of two independent multi-task losses. The proposed lightweight face detector (FDLite) has 0.26M parameters with 0.94 GFLOPs. The network is trained on the WIDER FACE dataset. FDLite is observed to achieve 92.3\%, 89.8\%, and 82.2\% Average Precision (AP) on the easy, medium, and hard subsets of the WIDER FACE validation dataset, respectively.
IDA-UIE: An Iterative Framework for Deep Network-based Degradation Aware Underwater Image Enhancement
Jun 26, 2024Underwater image quality is affected by fluorescence, low illumination, absorption, and scattering. Recent works in underwater image enhancement have proposed different deep network architectures to handle these problems. Most of these works have proposed a single network to handle all the challenges. We believe that deep networks trained for specific conditions deliver better performance than a single network learned from all degradation cases. Accordingly, the first contribution of this work lies in the proposal of an iterative framework where a single dominant degradation condition is identified and resolved. This proposal considers the following eight degradation conditions -- low illumination, low contrast, haziness, blurred image, presence of noise and color imbalance in three different channels. A deep network is designed to identify the dominant degradation condition. Accordingly, an appropriate deep network is selected for degradation condition-specific enhancement. The second contribution of this work is the construction of degradation condition specific datasets from good quality images of two standard datasets (UIEB and EUVP). This dataset is used to learn the condition specific enhancement networks. The proposed approach is found to outperform nine baseline methods on UIEB and EUVP datasets.
VQA with Cascade of Self- and Co-Attention Blocks
Feb 28, 2023
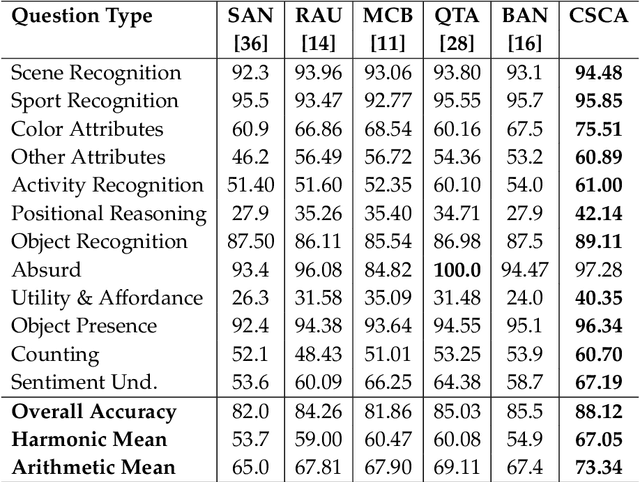
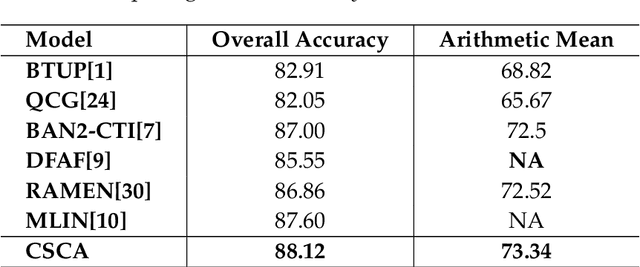
The use of complex attention modules has improved the performance of the Visual Question Answering (VQA) task. This work aims to learn an improved multi-modal representation through dense interaction of visual and textual modalities. The proposed model has an attention block containing both self-attention and co-attention on image and text. The self-attention modules provide the contextual information of objects (for an image) and words (for a question) that are crucial for inferring an answer. On the other hand, co-attention aids the interaction of image and text. Further, fine-grained information is obtained from two modalities by using a Cascade of Self- and Co-Attention blocks (CSCA). This proposal is benchmarked on the widely used VQA2.0 and TDIUC datasets. The efficacy of key components of the model and cascading of attention modules are demonstrated by experiments involving ablation analysis.
Facial Keypoint Sequence Generation from Audio
Nov 02, 2020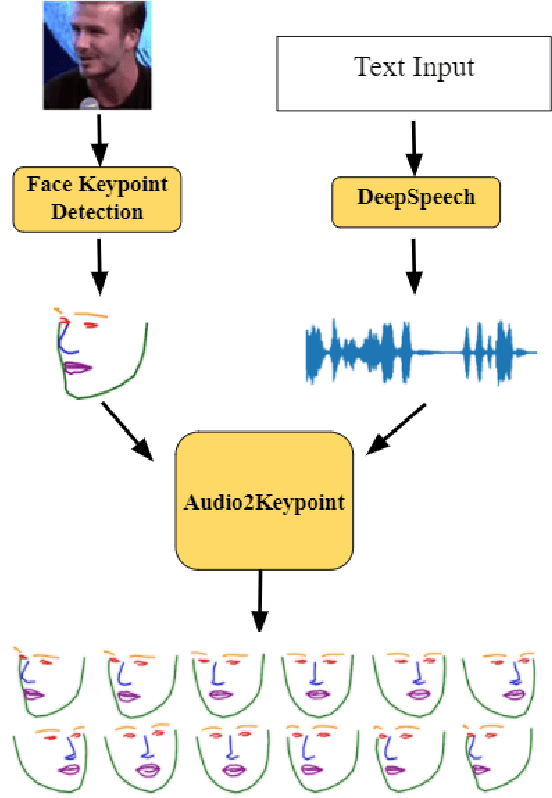
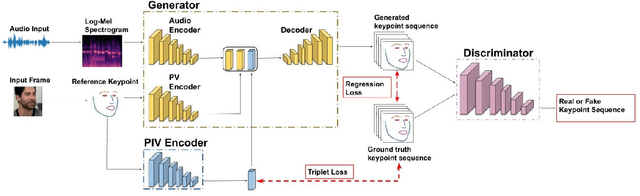
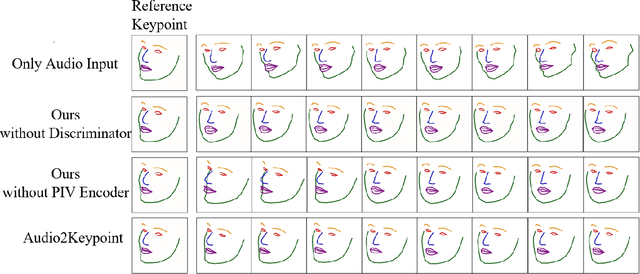
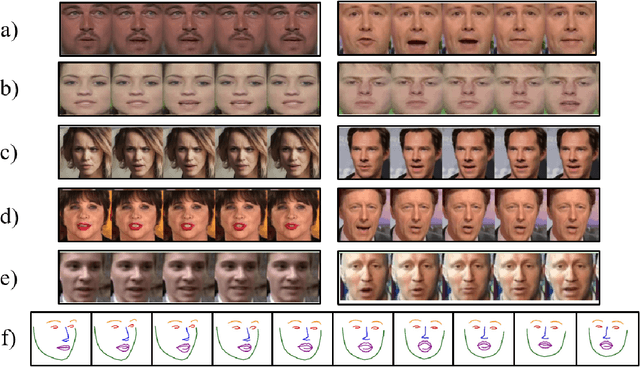
Whenever we speak, our voice is accompanied by facial movements and expressions. Several recent works have shown the synthesis of highly photo-realistic videos of talking faces, but they either require a source video to drive the target face or only generate videos with a fixed head pose. This lack of facial movement is because most of these works focus on the lip movement in sync with the audio while assuming the remaining facial keypoints' fixed nature. To address this, a unique audio-keypoint dataset of over 150,000 videos at 224p and 25fps is introduced that relates the facial keypoint movement for the given audio. This dataset is then further used to train the model, Audio2Keypoint, a novel approach for synthesizing facial keypoint movement to go with the audio. Given a single image of the target person and an audio sequence (in any language), Audio2Keypoint generates a plausible keypoint movement sequence in sync with the input audio, conditioned on the input image to preserve the target person's facial characteristics. To the best of our knowledge, this is the first work that proposes an audio-keypoint dataset and learns a model to output the plausible keypoint sequence to go with audio of any arbitrary length. Audio2Keypoint generalizes across unseen people with a different facial structure allowing us to generate the sequence with the voice from any source or even synthetic voices. Instead of learning a direct mapping from audio to video domain, this work aims to learn the audio-keypoint mapping that allows for in-plane and out-of-plane head rotations, while preserving the person's identity using a Pose Invariant (PIV) Encoder.
IQ-VQA: Intelligent Visual Question Answering
Jul 08, 2020
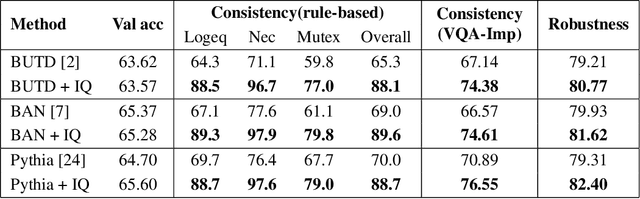


Even though there has been tremendous progress in the field of Visual Question Answering, models today still tend to be inconsistent and brittle. To this end, we propose a model-independent cyclic framework which increases consistency and robustness of any VQA architecture. We train our models to answer the original question, generate an implication based on the answer and then also learn to answer the generated implication correctly. As a part of the cyclic framework, we propose a novel implication generator which can generate implied questions from any question-answer pair. As a baseline for future works on consistency, we provide a new human annotated VQA-Implications dataset. The dataset consists of ~30k questions containing implications of 3 types - Logical Equivalence, Necessary Condition and Mutual Exclusion - made from the VQA v2.0 validation dataset. We show that our framework improves consistency of VQA models by ~15% on the rule-based dataset, ~7% on VQA-Implications dataset and robustness by ~2%, without degrading their performance. In addition, we also quantitatively show improvement in attention maps which highlights better multi-modal understanding of vision and language.
CQ-VQA: Visual Question Answering on Categorized Questions
Feb 17, 2020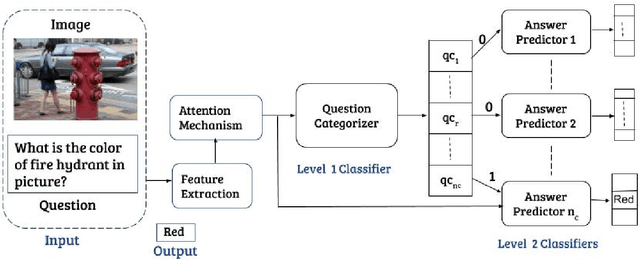
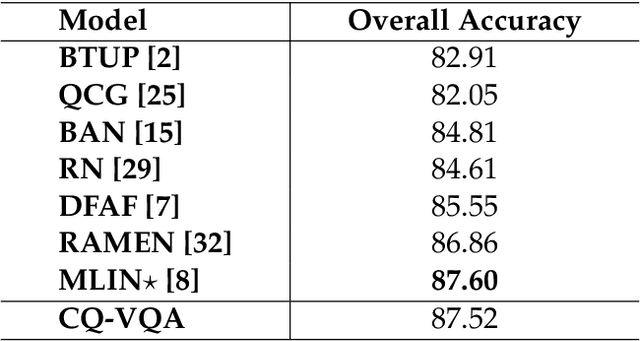
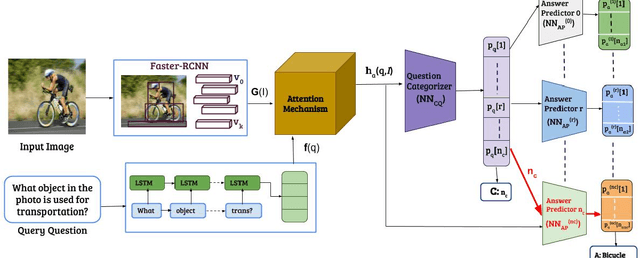
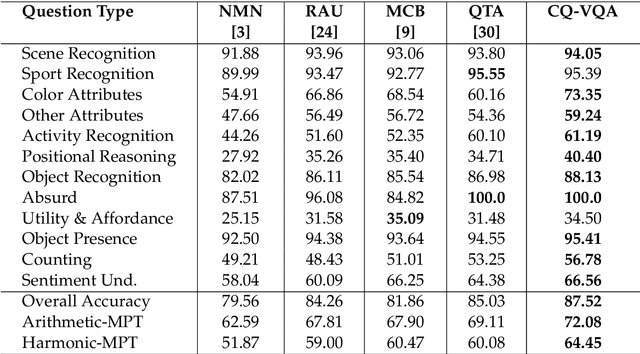
This paper proposes CQ-VQA, a novel 2-level hierarchical but end-to-end model to solve the task of visual question answering (VQA). The first level of CQ-VQA, referred to as question categorizer (QC), classifies questions to reduce the potential answer search space. The QC uses attended and fused features of the input question and image. The second level, referred to as answer predictor (AP), comprises of a set of distinct classifiers corresponding to each question category. Depending on the question category predicted by QC, only one of the classifiers of AP remains active. The loss functions of QC and AP are aggregated together to make it an end-to-end model. The proposed model (CQ-VQA) is evaluated on the TDIUC dataset and is benchmarked against state-of-the-art approaches. Results indicate competitive or better performance of CQ-VQA.
Reinforcement Learning via Recurrent Convolutional Neural Networks
Jan 09, 2017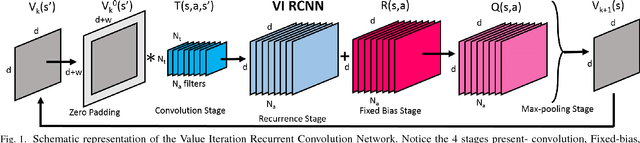
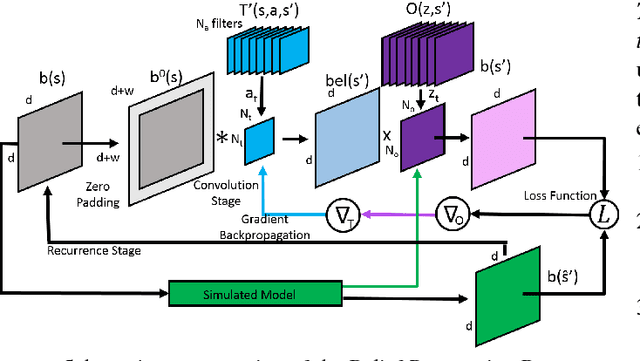
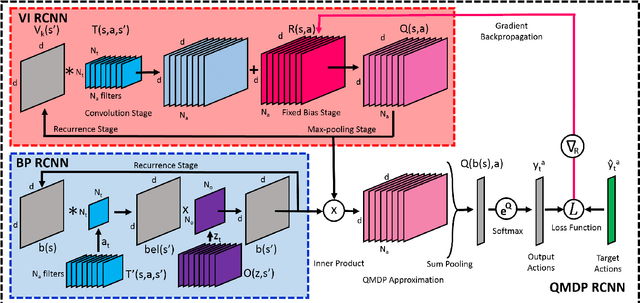
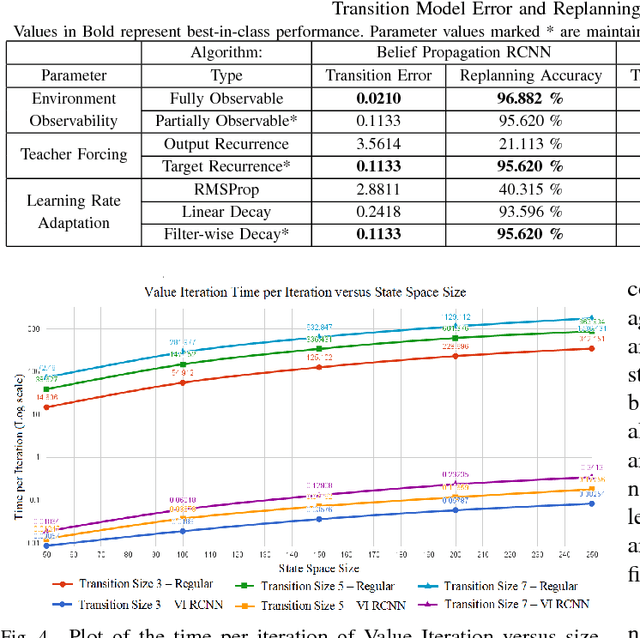
Deep Reinforcement Learning has enabled the learning of policies for complex tasks in partially observable environments, without explicitly learning the underlying model of the tasks. While such model-free methods achieve considerable performance, they often ignore the structure of task. We present a natural representation of to Reinforcement Learning (RL) problems using Recurrent Convolutional Neural Networks (RCNNs), to better exploit this inherent structure. We define 3 such RCNNs, whose forward passes execute an efficient Value Iteration, propagate beliefs of state in partially observable environments, and choose optimal actions respectively. Backpropagating gradients through these RCNNs allows the system to explicitly learn the Transition Model and Reward Function associated with the underlying MDP, serving as an elegant alternative to classical model-based RL. We evaluate the proposed algorithms in simulation, considering a robot planning problem. We demonstrate the capability of our framework to reduce the cost of replanning, learn accurate MDP models, and finally re-plan with learnt models to achieve near-optimal policies.
Overlay Text Extraction From TV News Broadcast
Apr 02, 2016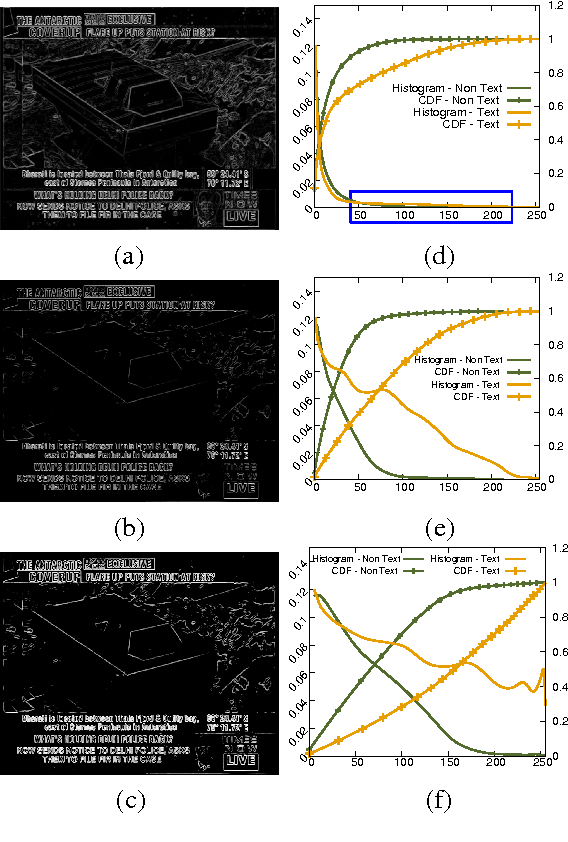

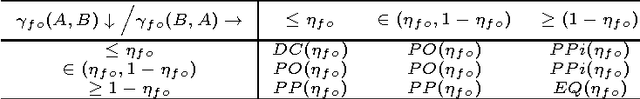
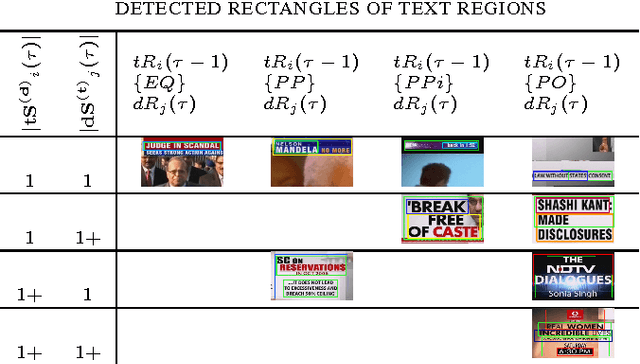
The text data present in overlaid bands convey brief descriptions of news events in broadcast videos. The process of text extraction becomes challenging as overlay text is presented in widely varying formats and often with animation effects. We note that existing edge density based methods are well suited for our application on account of their simplicity and speed of operation. However, these methods are sensitive to thresholds and have high false positive rates. In this paper, we present a contrast enhancement based preprocessing stage for overlay text detection and a parameter free edge density based scheme for efficient text band detection. The second contribution of this paper is a novel approach for multiple text region tracking with a formal identification of all possible detection failure cases. The tracking stage enables us to establish the temporal presence of text bands and their linking over time. The third contribution is the adoption of Tesseract OCR for the specific task of overlay text recognition using web news articles. The proposed approach is tested and found superior on news videos acquired from three Indian English television news channels along with benchmark datasets.