 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning via Recurrent Convolutional Neural Networks
Jan 09, 2017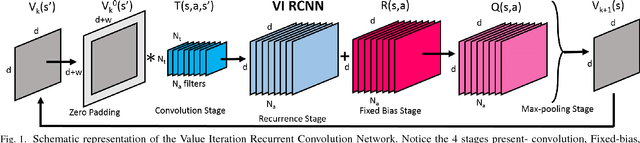
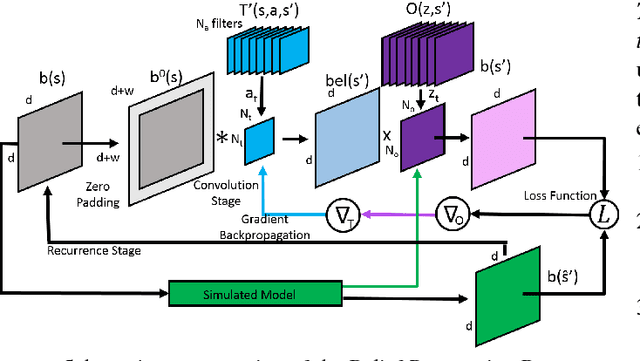
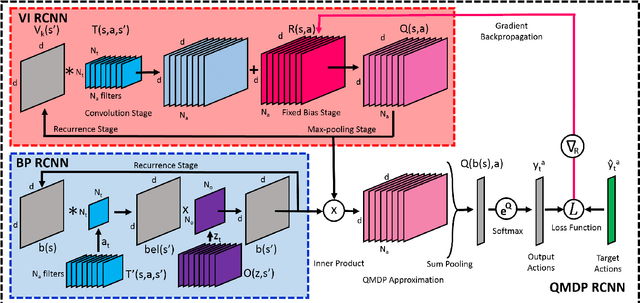
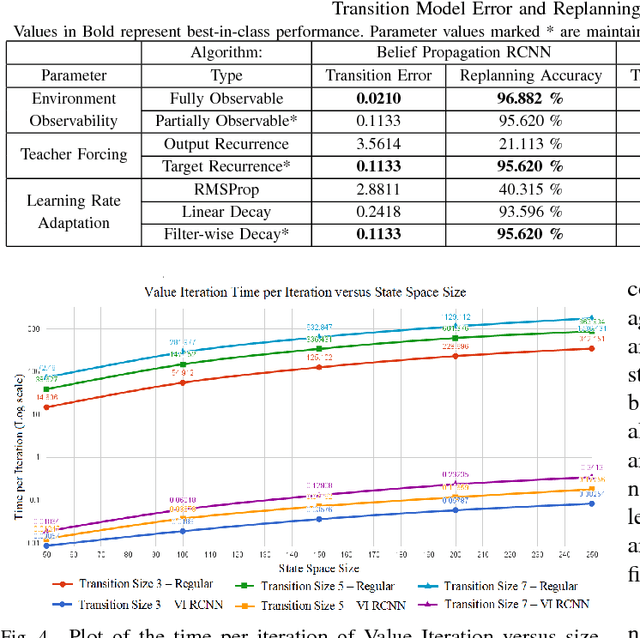
Deep Reinforcement Learning has enabled the learning of policies for complex tasks in partially observable environments, without explicitly learning the underlying model of the tasks. While such model-free methods achieve considerable performance, they often ignore the structure of task. We present a natural representation of to Reinforcement Learning (RL) problems using Recurrent Convolutional Neural Networks (RCNNs), to better exploit this inherent structure. We define 3 such RCNNs, whose forward passes execute an efficient Value Iteration, propagate beliefs of state in partially observable environments, and choose optimal actions respectively. Backpropagating gradients through these RCNNs allows the system to explicitly learn the Transition Model and Reward Function associated with the underlying MDP, serving as an elegant alternative to classical model-based RL. We evaluate the proposed algorithms in simulation, considering a robot planning problem. We demonstrate the capability of our framework to reduce the cost of replanning, learn accurate MDP models, and finally re-plan with learnt models to achieve near-optimal policies.