 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing One-pixel Black-box Adversarial Attacks
Apr 30, 2022

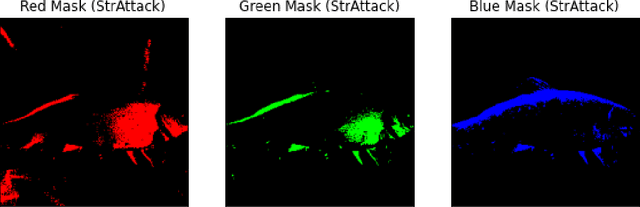

The output of Deep Neural Networks (DNN) can be altered by a small perturbation of the input in a black box setting by making multiple calls to the DNN. However, the high computation and time required makes the existing approaches unusable. This work seeks to improve the One-pixel (few-pixel) black-box adversarial attacks to reduce the number of calls to the network under attack. The One-pixel attack uses a non-gradient optimization algorithm to find pixel-level perturbations under the constraint of a fixed number of pixels, which causes the network to predict the wrong label for a given image. We show through experimental results how the choice of the optimization algorithm and initial positions to search can reduce function calls and increase attack success significantly, making the attack more practical in real-world settings.
Facial Keypoint Sequence Generation from Audio
Nov 02, 2020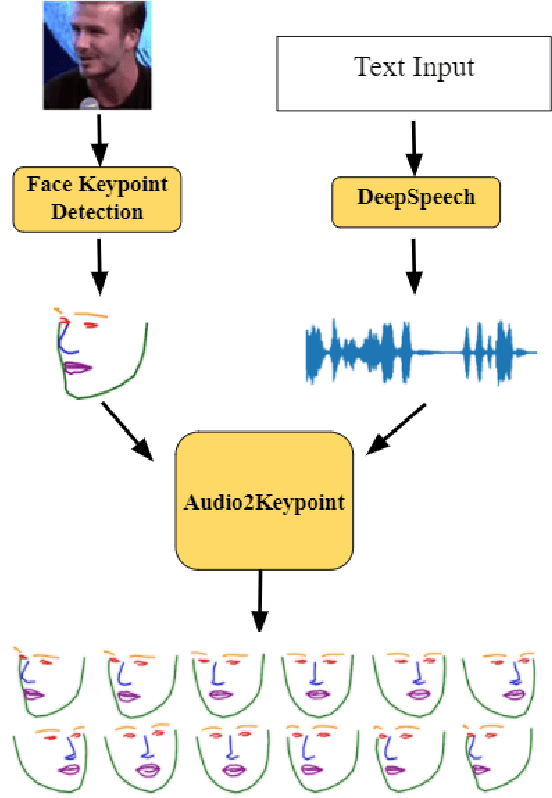
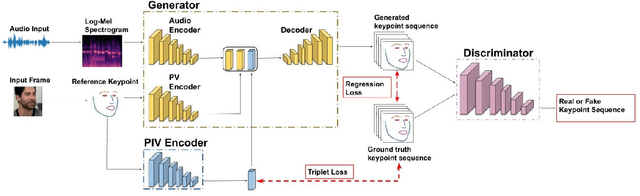
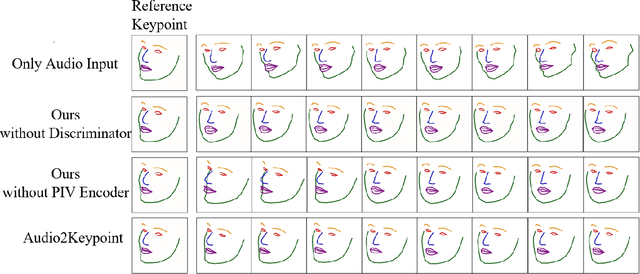
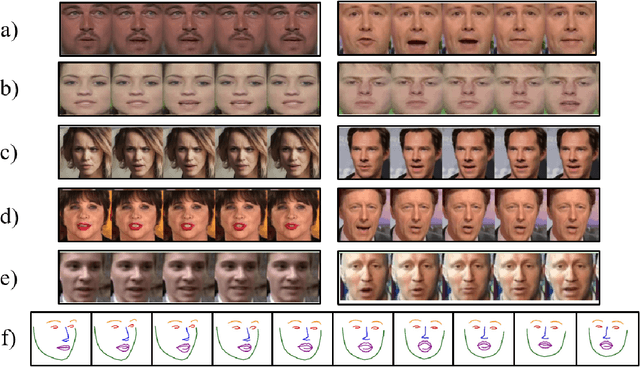
Whenever we speak, our voice is accompanied by facial movements and expressions. Several recent works have shown the synthesis of highly photo-realistic videos of talking faces, but they either require a source video to drive the target face or only generate videos with a fixed head pose. This lack of facial movement is because most of these works focus on the lip movement in sync with the audio while assuming the remaining facial keypoints' fixed nature. To address this, a unique audio-keypoint dataset of over 150,000 videos at 224p and 25fps is introduced that relates the facial keypoint movement for the given audio. This dataset is then further used to train the model, Audio2Keypoint, a novel approach for synthesizing facial keypoint movement to go with the audio. Given a single image of the target person and an audio sequence (in any language), Audio2Keypoint generates a plausible keypoint movement sequence in sync with the input audio, conditioned on the input image to preserve the target person's facial characteristics. To the best of our knowledge, this is the first work that proposes an audio-keypoint dataset and learns a model to output the plausible keypoint sequence to go with audio of any arbitrary length. Audio2Keypoint generalizes across unseen people with a different facial structure allowing us to generate the sequence with the voice from any source or even synthetic voices. Instead of learning a direct mapping from audio to video domain, this work aims to learn the audio-keypoint mapping that allows for in-plane and out-of-plane head rotations, while preserving the person's identity using a Pose Invariant (PIV) Encoder.