 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Models Enable Zero-Shot Pose Estimation for Lower-Limb Prosthetic Users
Dec 13, 2023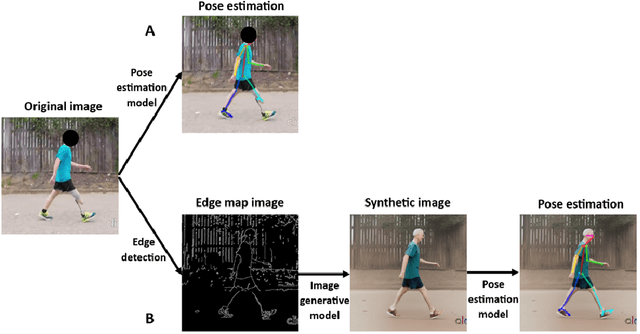
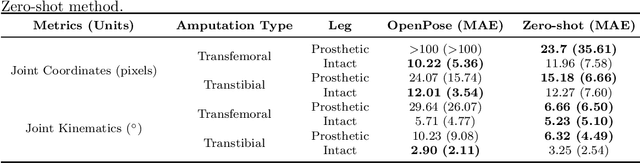
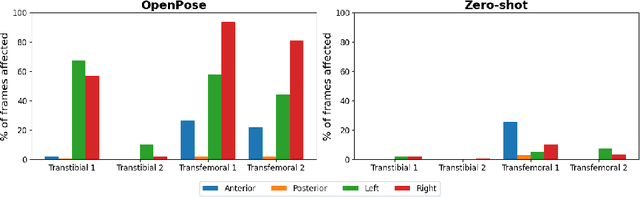
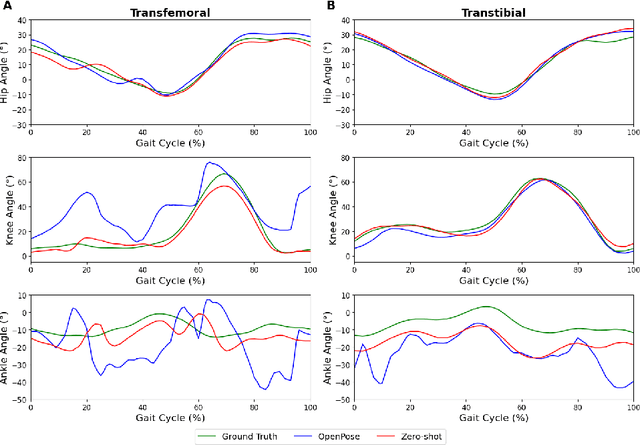
The application of 2D markerless gait analysis has garnered increasing interest and application within clinical settings. However, its effectiveness in the realm of lower-limb amputees has remained less than optimal. In response, this study introduces an innovative zero-shot method employing image generation diffusion models to achieve markerless pose estimation for lower-limb prosthetics, presenting a promising solution to gait analysis for this specific population. Our approach demonstrates an enhancement in detecting key points on prosthetic limbs over existing methods, and enables clinicians to gain invaluable insights into the kinematics of lower-limb amputees across the gait cycle. The outcomes obtained not only serve as a proof-of-concept for the feasibility of this zero-shot approach but also underscore its potential in advancing rehabilitation through gait analysis for this unique population.
Synthetic data generation method for data-free knowledge distillation in regression neural networks
Jan 11, 2023Knowledge distillation is the technique of compressing a larger neural network, known as the teacher, into a smaller neural network, known as the student, while still trying to maintain the performance of the larger neural network as much as possible. Existing methods of knowledge distillation are mostly applicable for classification tasks. Many of them also require access to the data used to train the teacher model. To address the problem of knowledge distillation for regression tasks under the absence of original training data, previous work has proposed a data-free knowledge distillation method where synthetic data are generated using a generator model trained adversarially against the student model. These synthetic data and their labels predicted by the teacher model are then used to train the student model. In this study, we investigate the behavior of various synthetic data generation methods and propose a new synthetic data generation strategy that directly optimizes for a large but bounded difference between the student and teacher model. Our results on benchmark and case study experiments demonstrate that the proposed strategy allows the student model to learn better and emulate the performance of the teacher model more closely.
Optimizing One-pixel Black-box Adversarial Attacks
Apr 30, 2022


The output of Deep Neural Networks (DNN) can be altered by a small perturbation of the input in a black box setting by making multiple calls to the DNN. However, the high computation and time required makes the existing approaches unusable. This work seeks to improve the One-pixel (few-pixel) black-box adversarial attacks to reduce the number of calls to the network under attack. The One-pixel attack uses a non-gradient optimization algorithm to find pixel-level perturbations under the constraint of a fixed number of pixels, which causes the network to predict the wrong label for a given image. We show through experimental results how the choice of the optimization algorithm and initial positions to search can reduce function calls and increase attack success significantly, making the attack more practical in real-world settings.