 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learned Attribute Self-Interaction Network for Continual and Generalized Zero-Shot Learning
Dec 02, 2023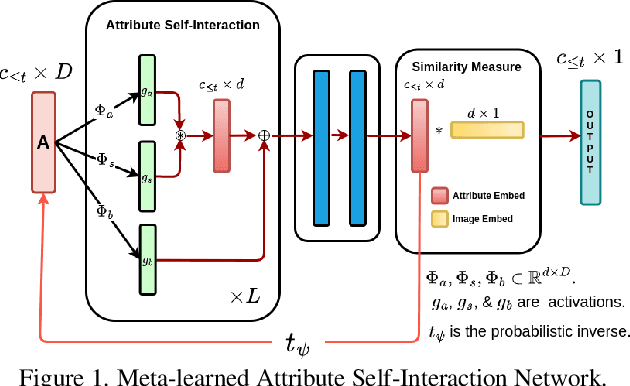
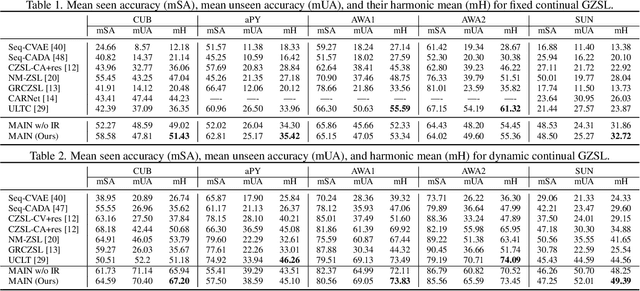
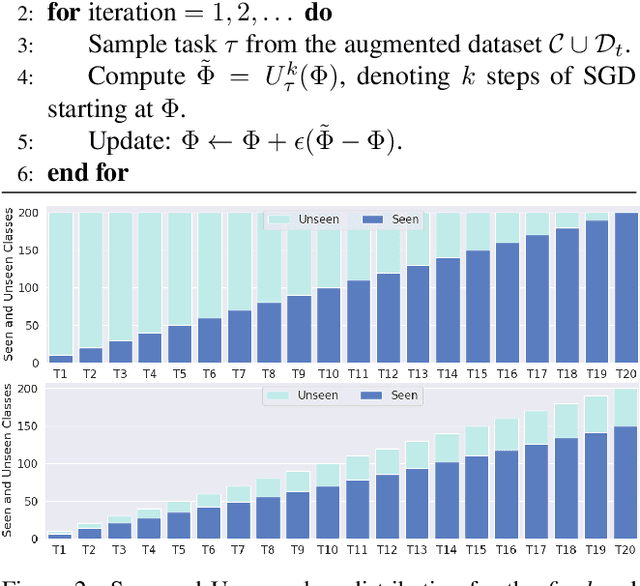
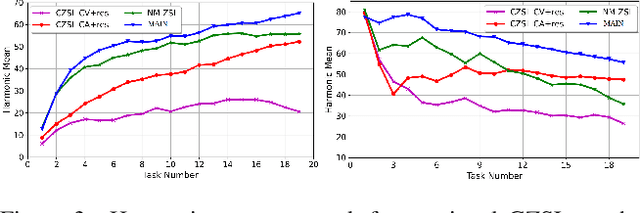
Zero-shot learning (ZSL) is a promising approach to generalizing a model to categories unseen during training by leveraging class attributes, but challenges remain. Recently, methods using generative models to combat bias towards classes seen during training have pushed state of the art, but these generative models can be slow or computationally expensive to train. Also, these generative models assume that the attribute vector of each unseen class is available a priori at training, which is not always practical. Additionally, while many previous ZSL methods assume a one-time adaptation to unseen classes, in reality, the world is always changing, necessitating a constant adjustment of deployed models. Models unprepared to handle a sequential stream of data are likely to experience catastrophic forgetting. We propose a Meta-learned Attribute self-Interaction Network (MAIN) for continual ZSL. By pairing attribute self-interaction trained using meta-learning with inverse regularization of the attribute encoder, we are able to outperform state-of-the-art results without leveraging the unseen class attributes while also being able to train our models substantially faster (>100x) than expensive generative-based approaches. We demonstrate this with experiments on five standard ZSL datasets (CUB, aPY, AWA1, AWA2, and SUN) in the generalized zero-shot learning and continual (fixed/dynamic) zero-shot learning settings. Extensive ablations and analyses demonstrate the efficacy of various components proposed.
VQA with Cascade of Self- and Co-Attention Blocks
Feb 28, 2023
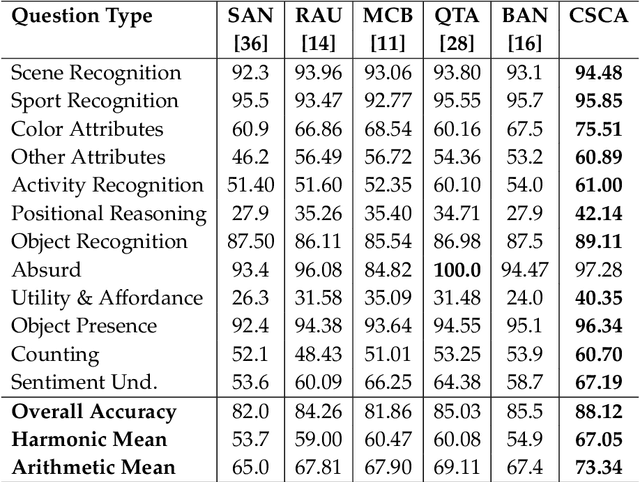
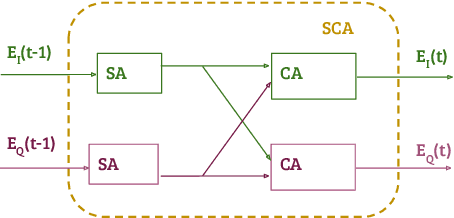
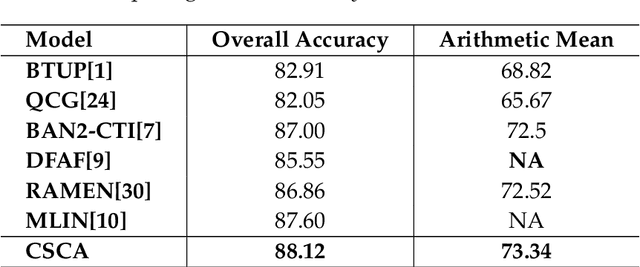
The use of complex attention modules has improved the performance of the Visual Question Answering (VQA) task. This work aims to learn an improved multi-modal representation through dense interaction of visual and textual modalities. The proposed model has an attention block containing both self-attention and co-attention on image and text. The self-attention modules provide the contextual information of objects (for an image) and words (for a question) that are crucial for inferring an answer. On the other hand, co-attention aids the interaction of image and text. Further, fine-grained information is obtained from two modalities by using a Cascade of Self- and Co-Attention blocks (CSCA). This proposal is benchmarked on the widely used VQA2.0 and TDIUC datasets. The efficacy of key components of the model and cascading of attention modules are demonstrated by experiments involving ablation analysis.
CQ-VQA: Visual Question Answering on Categorized Questions
Feb 17, 2020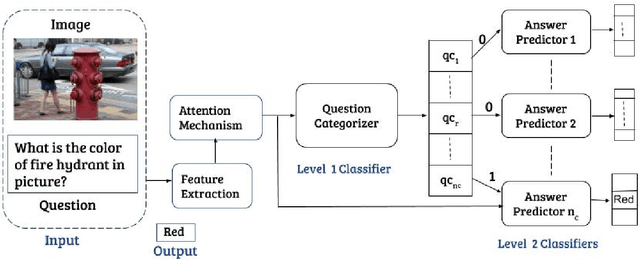
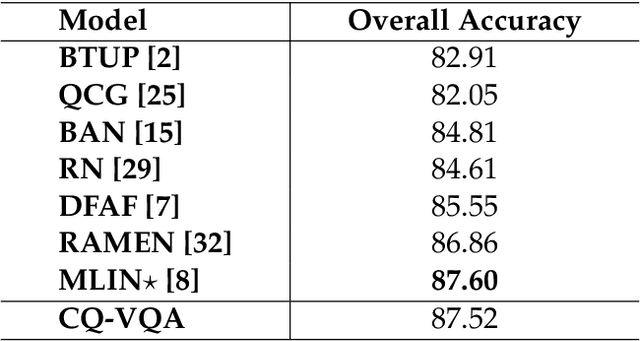
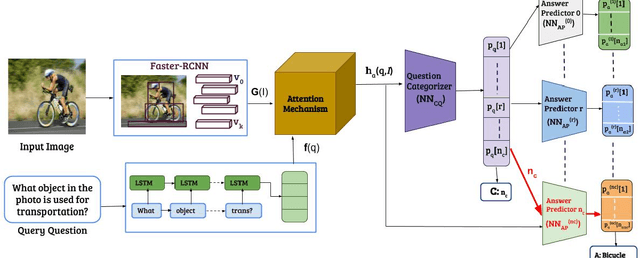
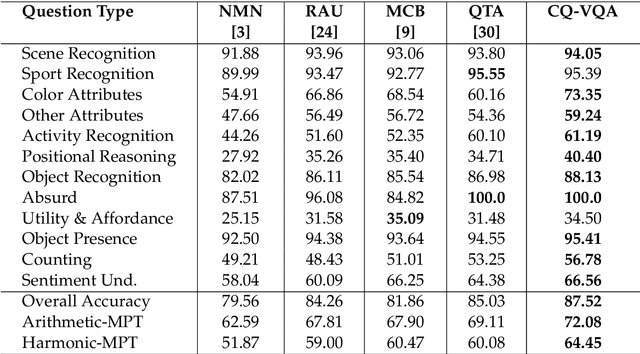
This paper proposes CQ-VQA, a novel 2-level hierarchical but end-to-end model to solve the task of visual question answering (VQA). The first level of CQ-VQA, referred to as question categorizer (QC), classifies questions to reduce the potential answer search space. The QC uses attended and fused features of the input question and image. The second level, referred to as answer predictor (AP), comprises of a set of distinct classifiers corresponding to each question category. Depending on the question category predicted by QC, only one of the classifiers of AP remains active. The loss functions of QC and AP are aggregated together to make it an end-to-end model. The proposed model (CQ-VQA) is evaluated on the TDIUC dataset and is benchmarked against state-of-the-art approaches. Results indicate competitive or better performance of CQ-VQA.
Generative Model for Zero-Shot Sketch-Based Image Retrieval
Apr 18, 2019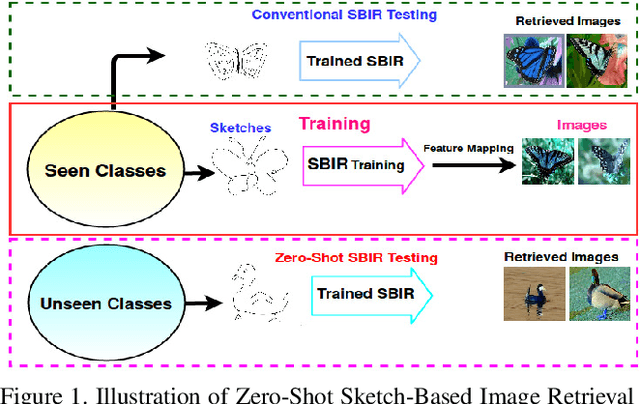
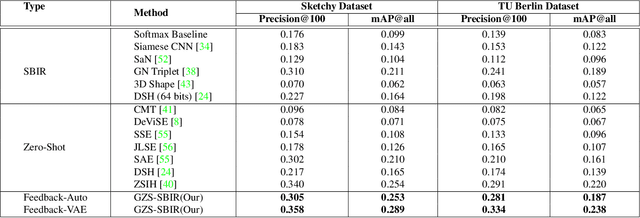
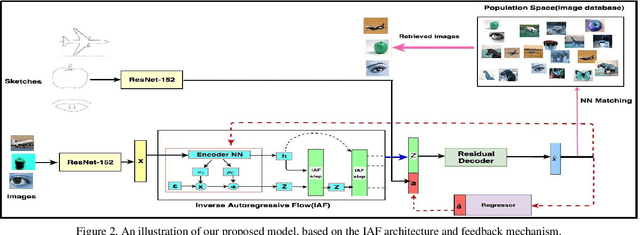
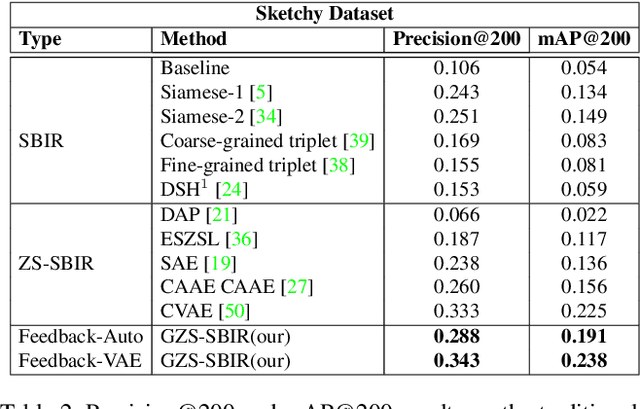
We present a probabilistic model for Sketch-Based Image Retrieval (SBIR) where, at retrieval time, we are given sketches from novel classes, that were not present at training time. Existing SBIR methods, most of which rely on learning class-wise correspondences between sketches and images, typically work well only for previously seen sketch classes, and result in poor retrieval performance on novel classes. To address this, we propose a generative model that learns to generate images, conditioned on a given novel class sketch. This enables us to reduce the SBIR problem to a standard image-to-image search problem. Our model is based on an inverse auto-regressive flow based variational autoencoder, with a feedback mechanism to ensure robust image generation. We evaluate our model on two very challenging datasets, Sketchy, and TU Berlin, with novel train-test split. The proposed approach significantly outperforms various baselines on both the datasets.