 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource Efficient Perception for Vision Systems
May 12, 2024



Despite the rapid advancement in the field of image recognition, the processing of high-resolution imagery remains a computational challenge. However, this processing is pivotal for extracting detailed object insights in areas ranging from autonomous vehicle navigation to medical imaging analyses. Our study introduces a framework aimed at mitigating these challenges by leveraging memory efficient patch based processing for high resolution images. It incorporates a global context representation alongside local patch information, enabling a comprehensive understanding of the image content. In contrast to traditional training methods which are limited by memory constraints, our method enables training of ultra high resolution images. We demonstrate the effectiveness of our method through superior performance on 7 different benchmarks across classification, object detection, and segmentation. Notably, the proposed method achieves strong performance even on resource-constrained devices like Jetson Nano. Our code is available at https://github.com/Visual-Conception-Group/Localized-Perception-Constrained-Vision-Systems.
Meta-Learned Attribute Self-Interaction Network for Continual and Generalized Zero-Shot Learning
Dec 02, 2023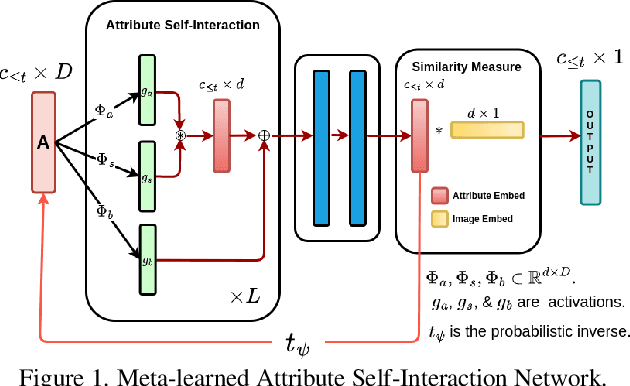
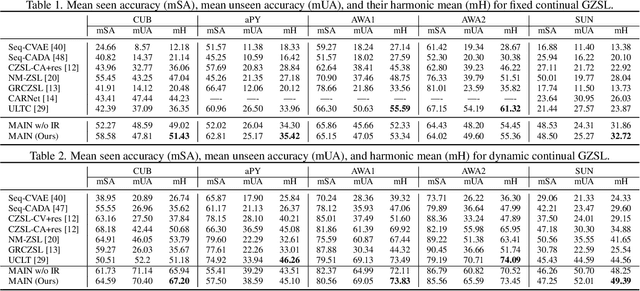
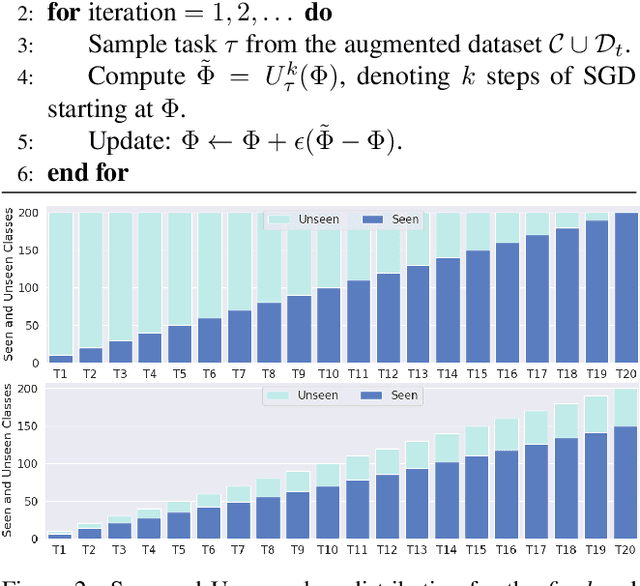
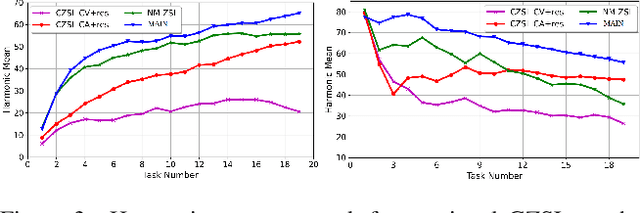
Zero-shot learning (ZSL) is a promising approach to generalizing a model to categories unseen during training by leveraging class attributes, but challenges remain. Recently, methods using generative models to combat bias towards classes seen during training have pushed state of the art, but these generative models can be slow or computationally expensive to train. Also, these generative models assume that the attribute vector of each unseen class is available a priori at training, which is not always practical. Additionally, while many previous ZSL methods assume a one-time adaptation to unseen classes, in reality, the world is always changing, necessitating a constant adjustment of deployed models. Models unprepared to handle a sequential stream of data are likely to experience catastrophic forgetting. We propose a Meta-learned Attribute self-Interaction Network (MAIN) for continual ZSL. By pairing attribute self-interaction trained using meta-learning with inverse regularization of the attribute encoder, we are able to outperform state-of-the-art results without leveraging the unseen class attributes while also being able to train our models substantially faster (>100x) than expensive generative-based approaches. We demonstrate this with experiments on five standard ZSL datasets (CUB, aPY, AWA1, AWA2, and SUN) in the generalized zero-shot learning and continual (fixed/dynamic) zero-shot learning settings. Extensive ablations and analyses demonstrate the efficacy of various components proposed.
Efficient Expansion and Gradient Based Task Inference for Replay Free Incremental Learning
Dec 02, 2023This paper proposes a simple but highly efficient expansion-based model for continual learning. The recent feature transformation, masking and factorization-based methods are efficient, but they grow the model only over the global or shared parameter. Therefore, these approaches do not fully utilize the previously learned information because the same task-specific parameter forgets the earlier knowledge. Thus, these approaches show limited transfer learning ability. Moreover, most of these models have constant parameter growth for all tasks, irrespective of the task complexity. Our work proposes a simple filter and channel expansion based method that grows the model over the previous task parameters and not just over the global parameter. Therefore, it fully utilizes all the previously learned information without forgetting, which results in better knowledge transfer. The growth rate in our proposed model is a function of task complexity; therefore for a simple task, the model has a smaller parameter growth while for complex tasks, the model requires more parameters to adapt to the current task. Recent expansion based models show promising results for task incremental learning (TIL). However, for class incremental learning (CIL), prediction of task id is a crucial challenge; hence, their results degrade rapidly as the number of tasks increase. In this work, we propose a robust task prediction method that leverages entropy weighted data augmentations and the models gradient using pseudo labels. We evaluate our model on various datasets and architectures in the TIL, CIL and generative continual learning settings. The proposed approach shows state-of-the-art results in all these settings. Our extensive ablation studies show the efficacy of the proposed components.