 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learned Attribute Self-Interaction Network for Continual and Generalized Zero-Shot Learning
Paper and Code
Dec 02, 2023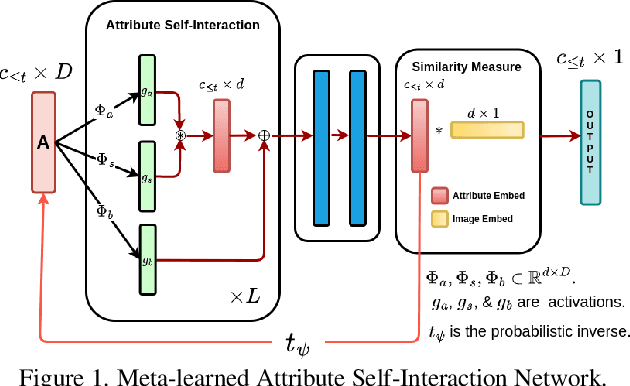
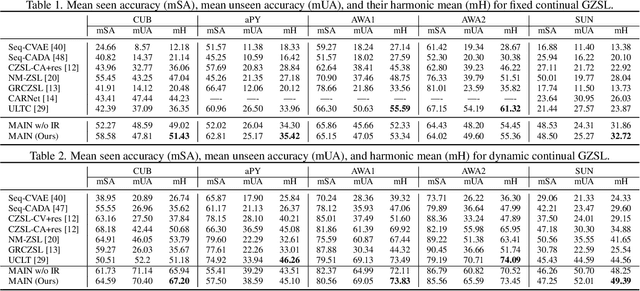
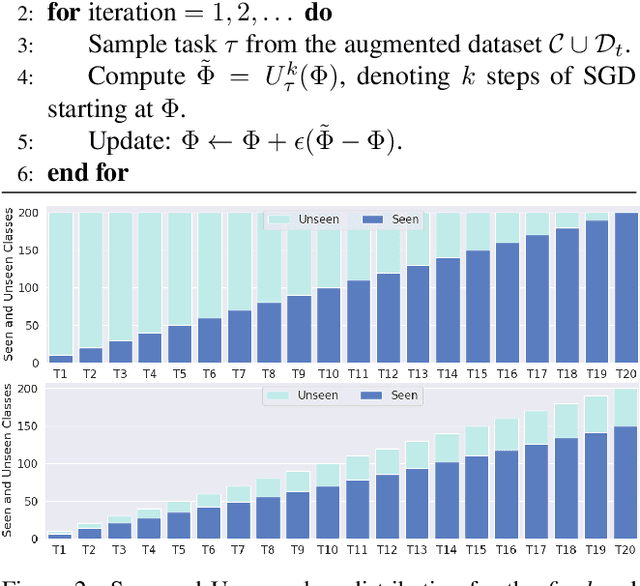
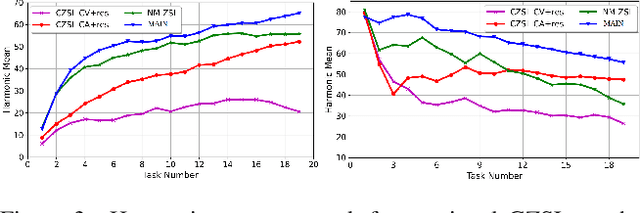
Zero-shot learning (ZSL) is a promising approach to generalizing a model to categories unseen during training by leveraging class attributes, but challenges remain. Recently, methods using generative models to combat bias towards classes seen during training have pushed state of the art, but these generative models can be slow or computationally expensive to train. Also, these generative models assume that the attribute vector of each unseen class is available a priori at training, which is not always practical. Additionally, while many previous ZSL methods assume a one-time adaptation to unseen classes, in reality, the world is always changing, necessitating a constant adjustment of deployed models. Models unprepared to handle a sequential stream of data are likely to experience catastrophic forgetting. We propose a Meta-learned Attribute self-Interaction Network (MAIN) for continual ZSL. By pairing attribute self-interaction trained using meta-learning with inverse regularization of the attribute encoder, we are able to outperform state-of-the-art results without leveraging the unseen class attributes while also being able to train our models substantially faster (>100x) than expensive generative-based approaches. We demonstrate this with experiments on five standard ZSL datasets (CUB, aPY, AWA1, AWA2, and SUN) in the generalized zero-shot learning and continual (fixed/dynamic) zero-shot learning settings. Extensive ablations and analyses demonstrate the efficacy of various components proposed.